1. Introduction
With the emergence of new technologies, including computer networks and multimedia information processing, digital images have become the main way of obtaining information from people’s daily lives, work, and studies because of their wide range of contents. Therefore, efficiently searching for the location information of the target image from visually information-rich images has been a focus of attention. However, images acquired in indoor low-light environments often suffer from quality degradation problems, such as missing features in dark areas and noise interference. These issues limit the effectiveness of feature extraction and matching algorithms, preventing them from providing application value in following target search tasks. As a result, how to improve the quality of low-light images in order to complete the subsequent target search task and then determine the target’s location information is particularly critical.
In order to solve the quality degradation problem of low-light images, researchers have explored histogram equalization (HE)-based methods [
1], Retinex-based methods [
2], and deep-learning-based methods [
3]. Although histogram equalization approaches can improve the contrast of low-light images, the enhanced images still have varying degrees of blurring, causing the number of extracted feature points to fall short of the requirements of the subsequent target search task.
In contrast to histogram equalization, methods based on Retinex theory divide the image into illumination and reflection components by a priori regularization or specific regularization, and use the estimated reflection component as the enhancement result, thereby reducing the loss of detail information in the original image. However, Retinex theory-based methods often ignore the treatment of noise during the enhancement process, which leads to a decrease in the accuracy of feature matching, thus reducing the accuracy of subsequent target searches.
Compared to the above two methods, the deep-learning-based method has made great progress in terms of accuracy, speed, and enhancement in low-light enhancement tasks. However, most deep-learning methods are still unable to balance noise control and luminance accuracy in the enhancement process, which makes the accuracy of feature extraction and matching degrade, thus reducing the accuracy of the target search. Aiming at the problem that the degradation of low-light image quality leads to the inability of the subsequent target search task, a joint local and high-level semantic information (JLHS) target search method is proposed based on joint bilateral filtering and camera response model (JBCRM) image preprocessing enhancement, as shown in
Figure 1.
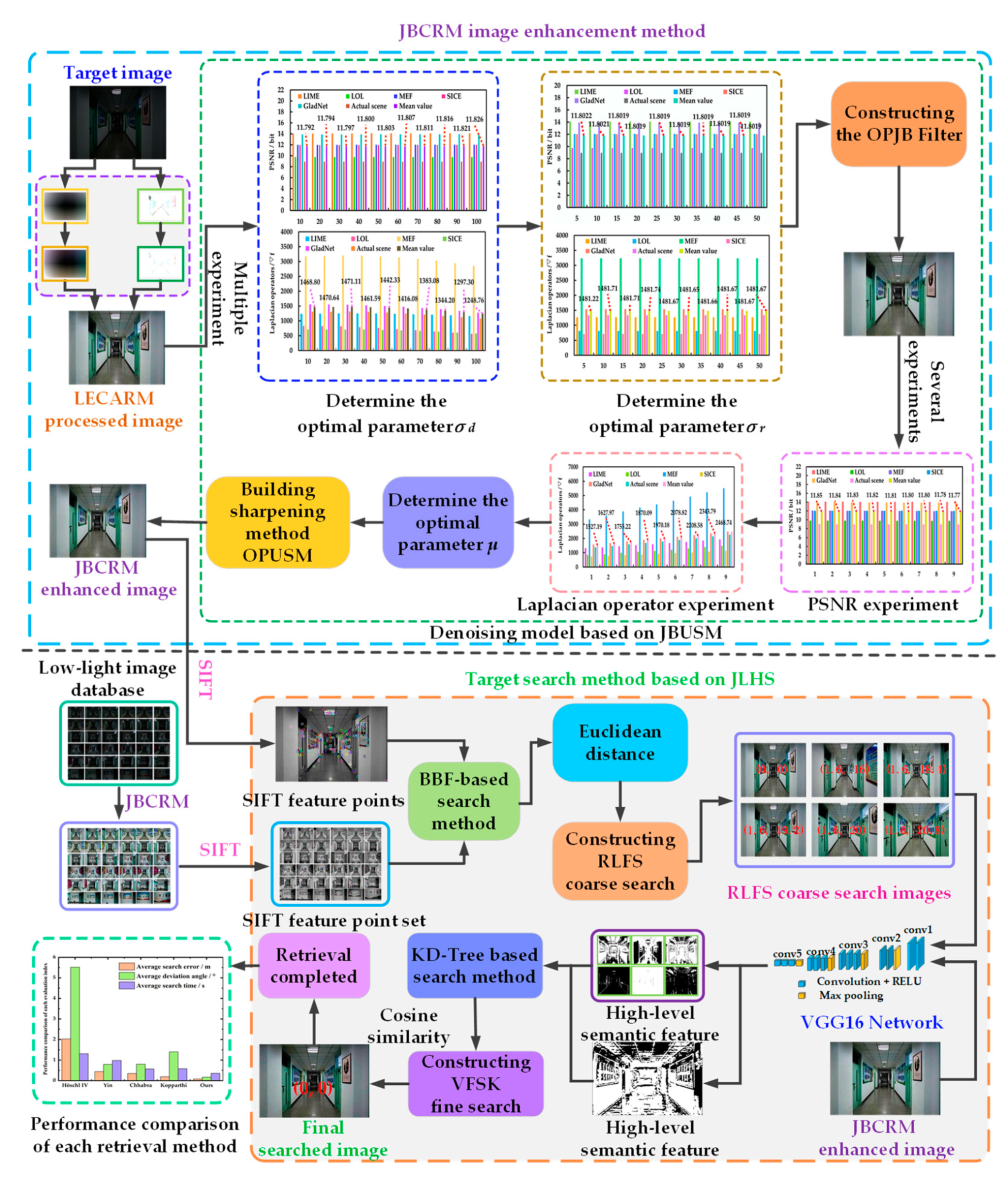
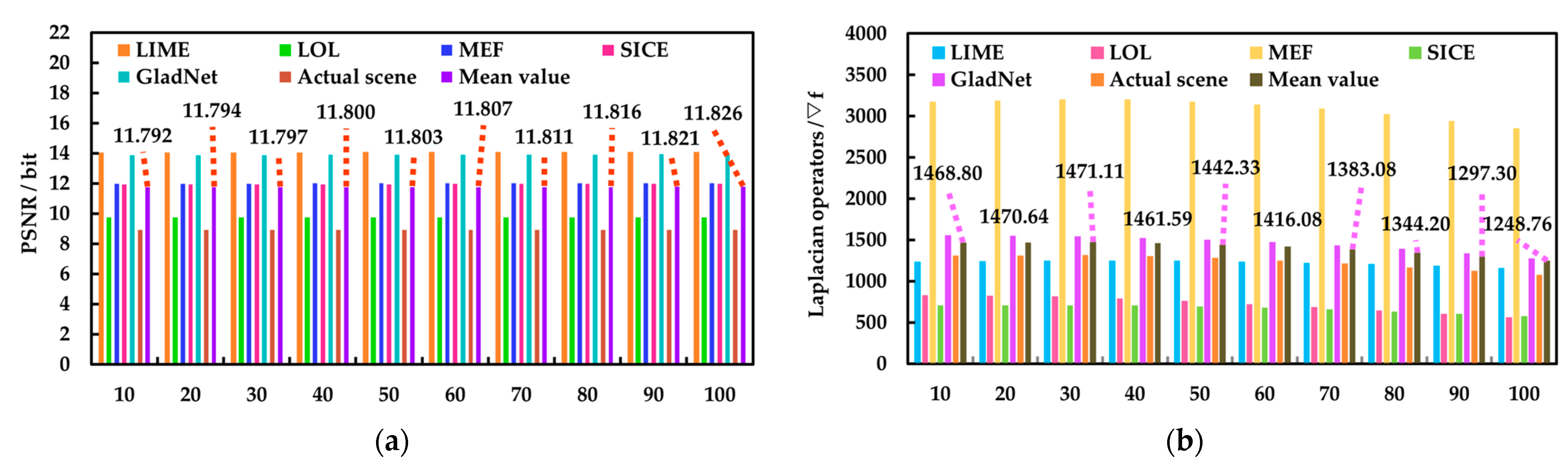
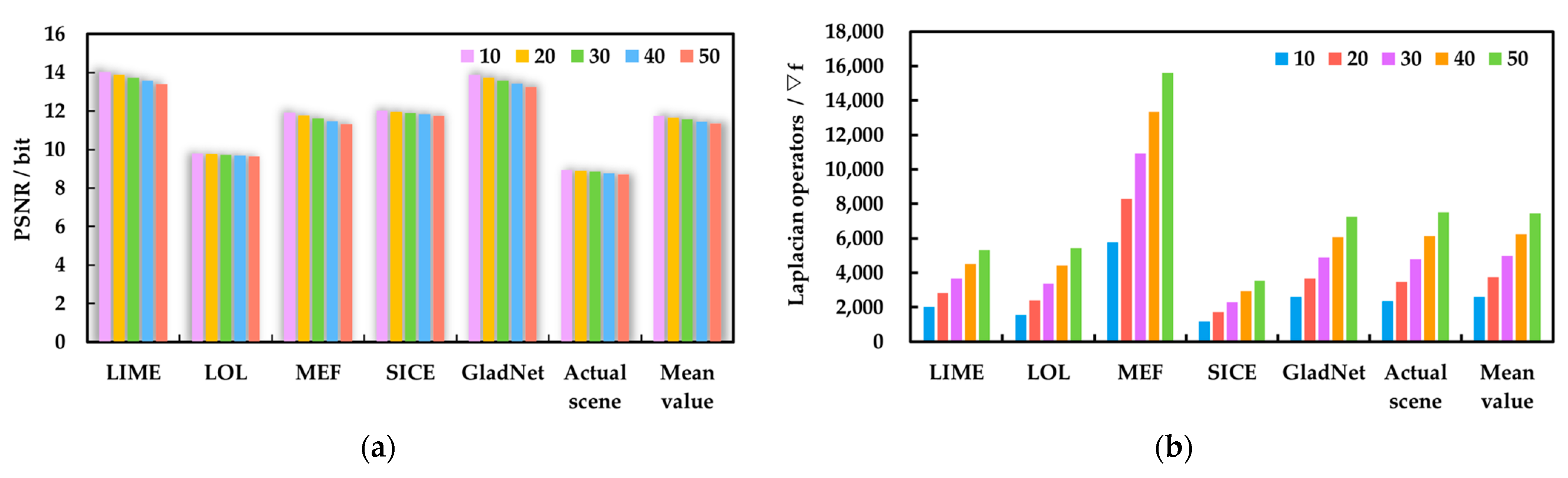
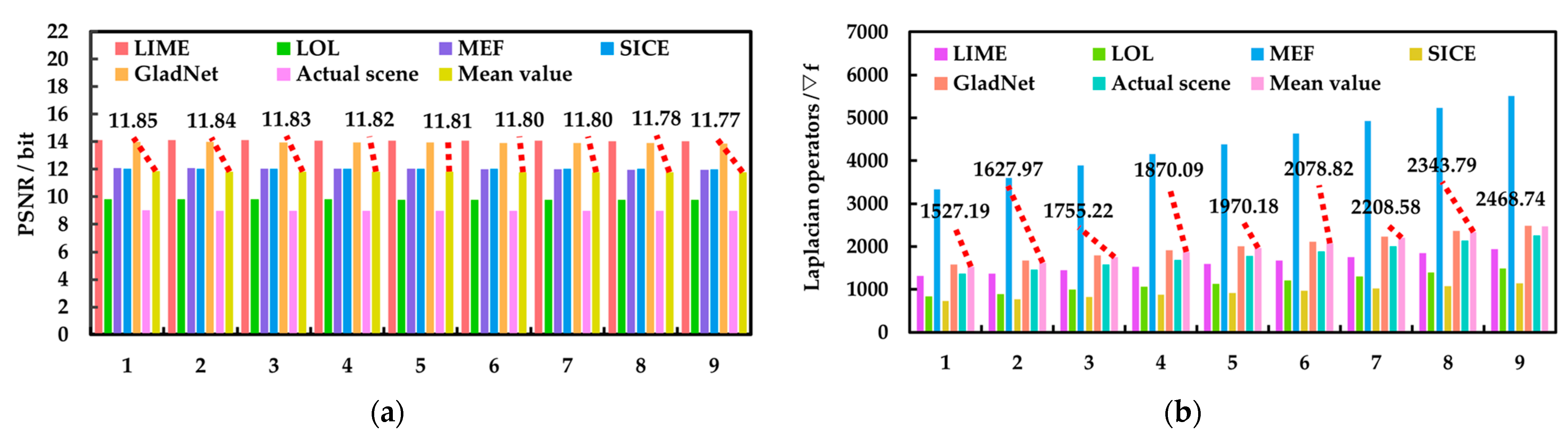
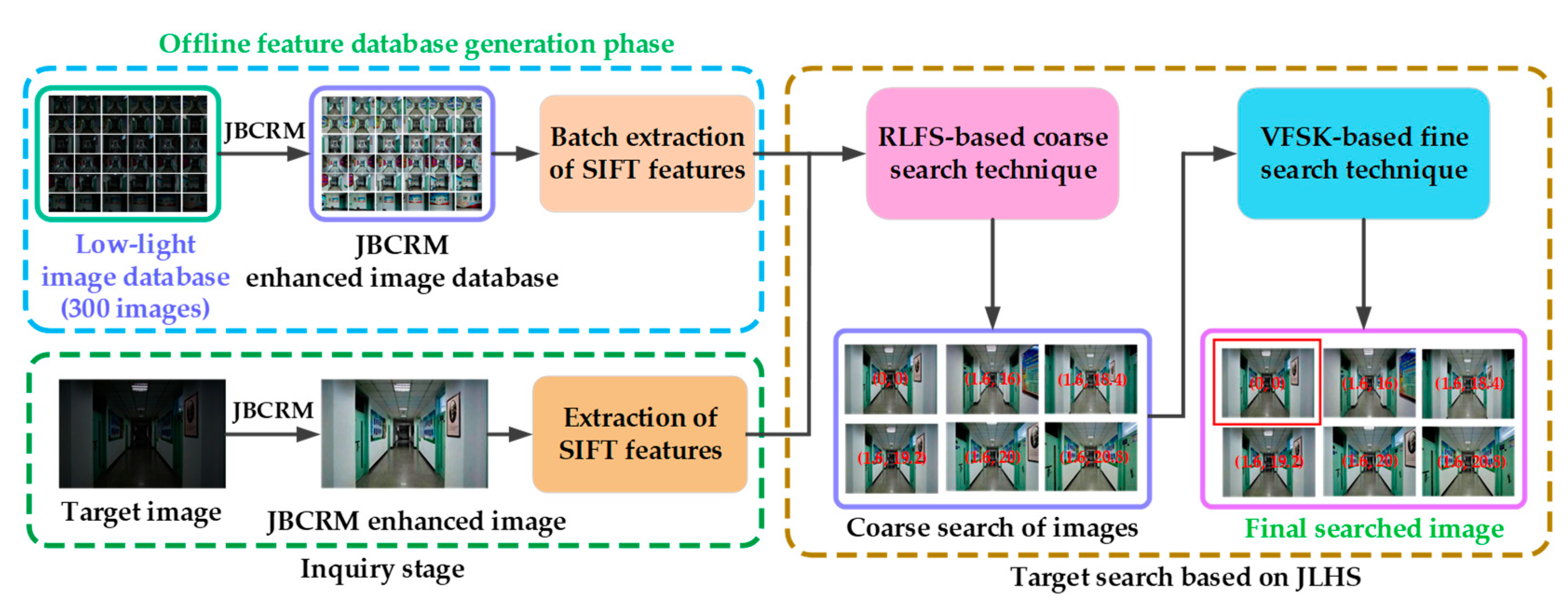
In the image preprocessing enhancement stage, the JBCRM image-enhancement method is composed of three parts: strengthening local features, denoising, and sharpening, in order to solve the problem of difficult feature extraction, thus providing better visual data for the subsequent target search task. Firstly, the indoor low-light images captured by a monocular vision camera (DJI Pocket 2, Shenzhen, China) are divided into an illumination component and a reflection component using the LECARM method. Secondly, the decomposed illuminance and reflection components are processed using the camera response model, thus obtaining the lighting-enhanced illuminance and reflection components, and these two components are fused to obtain the LECARM-processed image. Then, the OPJB filter is constructed by approximating the optimal parameters and through multiple experiments, thus rejecting the noise interference contained in the LECARM-processed image. Finally, the optimal parameter is chosen through several experiments to establish the OPUSM sharpening method, thereby accentuating the texture features of the denoised image. In the target search stage, the JLHS target search method consists of two parts: coarse search and fine search. Firstly, the target image and the offline database image are feature extracted using the rough search based on local feature SIFT (RLFS), respectively, and the corresponding feature vectors are generated and stored as corresponding npy files. Secondly, the BBF method is used to match the feature vectors in the offline database with the feature vectors of the target image, and the Euclidean distance is used to sort the matching results in descending order, so as to obtain the top six matching database images as the coarse search images. Then, the last layer of semantic information of each coarse search image and target image are extracted using the VGG16 fine search based on Keras (VFSK), respectively, and the corresponding feature vectors are generated and stored as h5 files. Finally, the KD-Tree method is used to match the h5 feature vector corresponding to each coarse search image and the h5 feature vector corresponding to the target image, and the cosine similarity is used to sort the matching results in descending order, thereby obtaining the coarse search image that is most similar to the target image. The position information of this coarse search image is the position information of the target image.
The main contributions of this paper are as follows:
- (1)
To address the issue of the difficulty in extracting feature information from low-light images, an image-enhancement method based on JBCRM is constructed. This method improves the image quality by strengthening the features of the dark region and reducing noise interference, so as to solve the problem of difficult feature information extraction.
- (2)
Aiming at the problem that current target search methods are unable to balance accuracy and search time, a target search method based on JLHS is designed. By combining local feature scale-invariant feature transform (SIFT) with high-level semantic features for image description, the method increases the matching accuracy between the target image and the offline database image, thereby improving the target search accuracy and reducing the target search time.
The remaining structure of this paper is as follows:
Section 2 introduces the related work.
Section 3 introduces the proposed JBCRM image-enhancement method, and the corresponding simulation experiments are carried out.
Section 4 describes the designed JLHS target search method.
Section 5 shows the simulation and analysis results of the target search.
Section 6 summarizes the conclusions of the proposed method and prospects for future research directions.
2. Related Work
This section introduces two main parts: enhancement methods for low-light images and search methods for targets. (1) Current low-light image-enhancement methods are presented, which solve the problem of difficult feature information extraction by improving the image quality. (2) Existing target search methods describe the image content in different ways to improve the accuracy of feature matching, thus raising the accuracy of the target search.
2.1. Low-Light Image-Enhancement Methods
Currently, the methods to solve the difficulty of feature information extraction by improving the image quality are mainly classified into three categories: histogram equalization-based methods, Retinex model-based methods, and deep-learning-based methods.
The methods based on histogram equalization improve the brightness and contrast of low-illumination images by expanding the grayscale range. Reference [
4] proposes an extended method based on histogram equalization called contrast limited dynamic quadri-histogram equalization (CLDQHE). The method splits the whole histogram into four sub-histograms and performs adaptive histogram cropping, thus overcoming the defects of over-enhancement and over-smoothing in traditional histogram equalization methods. Reference [
5] describes an adapted contrast enhancement using modified histogram (ACMHE). This method divides the histogram of the input image into four sub-histograms based on the brightness median. Then, independent histogram equalization is performed on each partition, resulting in natural contrast enhancement and brightness preservation. Although histogram equalization-based approaches increase the contrast and brightness of low-light images to varying degrees, they nevertheless suffer from noise interference and color distortion, which degrade the accuracy of feature extraction and matching, thereby decreasing the accuracy of the target search.
To further improve the quality of low-light images, researchers have successively proposed the multi-scale Retinex (MSR) method [
6] and the multi-scale Retinex with color recovery (MSRCR) method [
7]. In order to better preserve the structural information of the original low-light image, reference [
8] proposes an image-enhancement method that combines Zero—DCE and Retinex. This method first utilizes the Retinex model to decompose the image into an illumination component and a reflection component. Then, the illumination component is enhanced by using deep light curve estimation, and the reflection component of the image is kept unchanged, so as to achieve the purpose of maintaining the structural characteristics of the image. Ref. [
9] proposes a global attention-based Retinex network (GARN) for low-light image enhancement by embedding global attention modules in different levels of the network. However, Retinex-based methods produce unnecessary halo artifacts and noise interference, which degrade the accuracy of feature matching, thereby reducing the accuracy of the target search.
With the immense success of convolutional neural networks in various computer vision tasks, deep-learning-based methods have been widely used in the field of image enhancement. Reference [
10] proposes a trainable convolutional neural network (CNN) called LightenNet for enhancing low-light images. The method takes the low-light images as the input, outputs their illumination components, and then obtains the enhanced image based on the Retinex model. Retinex-Net [
11] improves the image brightness by using an end-to-end image decomposition model and a continuous low-light enhancement network. Reference [
12] presents a stacked sparse denoising autoencoder (SSDA) method to enhance low-light images. This method enhances the image by recognizing signal features in low-light images and adaptively enhancing the brightness of the image without over-amplifying the brighter parts of the image. Despite significant progress in low-light image-enhancement tasks using convolutional neural network-based deep-learning methods, there are still issues such as a loss of detail information and noise interference that prevent the number of extracted feature points from being sufficient for subsequent target searches.
To solve these problems, this paper proposes an image-enhancement method based on a joint bilateral filtering and camera response model (JBCRM). This method enhances the quality of the image by highlighting details in the dark areas and removing noise interference, thereby solving the problem of difficult feature extraction and providing better visual data for subsequent target search tasks.
2.2. Target Search Methods
Existing target search methods can be classified into three main categories based on their search principles: text-based image retrieval (TBIR), content-based image retrieval (CBIR), and semantic-based image retrieval (SBIR).
The TBIR approaches mostly employ text annotation to add keywords to images, thereby completing the target search task. Ref. [
13] proposes a target search method based on embedding and scene text. The first step of this method involves utilizing the maximally stable extremal region (MSER) algorithm to detect candidate text regions. Then, geometric features and stroke width transformations are used to eliminate unwanted false-positive text regions. Simultaneously, keywords are formed using a neural probabilistic language model, and the detected keywords are used to index and search the text images. Ref. [
14] presents a hybrid text–visual correlation-based learning method. The method mines textual relevance from image tags, and then combines textual relevance and visual relevance to accomplish the search task. Although TBIR approaches have increased the target search accuracy to some level, image annotation is required to complete the search operation, which increases this method’s manual expenditures.
The CBIR-based target search methods accomplish the search task mainly based on the features of the image content, thus avoiding the process of manually labeling the images. CBIR methods are mainly based on two types of visual features: local features and global features. The former captures underlying features from key points or salient blocks of an image. The latter considers the whole image as a salient region and convolves it, mainly including color [
15], texture [
16], and shape [
17]. Compared to a local feature-based target search, the global feature-based target search method is relatively simple and computationally fast, but it is ambiguous, which means the semantic meanings expressed by images with similar features may be different, thus leading to a lower accuracy of the target search. The common method based on local features is the scale-invariant feature transform (SIFT) method [
18], which generates 128-dimensional feature vectors for each key point. Meanwhile, the SIFT feature vectors are invariant to image scaling and rotation, with robustness to affine transformations, noise interference, and luminance transformations. [
19] proposes a target search framework based on the VLAD model and speeded-up robust feature (SURF) descriptors. This framework converts 64-dimensional SURF descriptors into 8-dimensional SURF descriptors, and then constructs a codebook using a two-step clustering algorithm. After that, it uses an expandable overlapping segmentation method and a feature-fusion strategy to accomplish target search tasks. Although CBIR-based target search methods improve the accuracy of the target search to a great extent, they also face the problem of a semantic gap between low-level visual features such as color, texture, and shape and high-level abstract attributes such as emotion, filling, and expression in the human mind.
To improve the performance and accuracy of content-based target search methods, semantic gaps need to be reduced. With the advancement of machine learning and deep learning in recent years, numerous SBIR-based target search approaches have been presented. These methods can reduce the semantic gap between the low-level features of the image and the high-level concepts in the human mind, and improve the accuracy of the target search. Ref. [
20] designs a color attention function to describe the importance of different image blocks and combines color with texture to construct candidate regions. Meanwhile, it is input into the deep neural network (DNN) for feature extraction, and a similarity function is designed to calculate the distance between different images, where the top-ranked image is used as the searched image. Ref. [
21] proposes a target search method that combines deep-learning semantic feature extraction and regularized Softmax. The method first constructs the convolution depth Boltzmann machine (C-DBM) by combining the deep Boltzmann machine (DBM) and the convolutional neural network (CNN). Then, the Dropout regularized Softmax classifier is used to classify the image features, and the image is searched based on the sorted output. Ref. [
22] presents a semantic target search method that fuses the visual saliency model with the bag-of-words model. This method uses a visual saliency-based segmentation method to segment the image into background regions and foreground targets. Then, multiple features, including SIFT features, are extracted and fused from the background region and foreground target, respectively. Meanwhile, the fusion z-score normalized chi-squared distance is used as the similarity measure to complete the target search. Although this method has a better target search performance, the computational complexity of segmentation is still large, and the performance of segmentation has a significant impact on the search performance. Allani et al. [
23] propose a target search system that fuses semantic and visual features. The system automatically builds a modular ontology for semantic information and organizes visual features in a graph-based model. These two elements are then combined in a component called “pattern” for subsequent target retrieval. Chen et al. [
24] present a method based on deep image search called deep semantic hashing (DSH). This method considers the visual and semantic features of the image based on deep learning and uses the semantic information to generate the hash function of the hash code, thus improving the accuracy of the subsequent target search. Although the target search accuracy is greatly increased by SBIR-based methods, they are still challenging owing to the limitations of present artificial intelligence and related technology. In order to improve the target search accuracy and shorten the search time, this paper constructs a joint local and high-level semantic information (JLHS) target search method. By combining the local feature SIFT with the high-level semantic feature, this method increases the feature matching accuracy of the target image and offline database images, thereby improving the precision and decreasing the search time for the target search.
4. Construction of Target Search Method Based on JLHS
This section presents two main parts: (1) Introducing the process of constructing the JLHS target search method. (2) Simulation and analysis of the existing target search method and JLHS method in the real scenario. The details are as follows.
Currently, global features and local features are the main methods for characterizing image content in CBIR-based target search methods. Compared with the former, the latter can more appropriately characterize the feature information contained in images. The most widely used local features are SIFT local features, which produce 128-dimensional feature vectors for each key point. Compared with speeded-up robust features (SURF) and ORB local features, SIFT feature vectors are resistant to affine transformations, noise interference, and luminance transformations, and are unaffected by image scaling and rotation. As a result, SIFT local features are widely used in the field of target search. However, SIFT feature-based target search methods have a low accuracy and must be combined with other methods to increase target search precision. The success of deep-learning-based methods has provided an effective solution for this. Although deep-learning-based target search methods have a better search accuracy, they take a lot of time and computer resources. To improve the search accuracy and shorten the search time, a joint local and high-level semantic information (JLHS) target search method is proposed in this paper. This method consists of two parts: a rough search based on local feature SIFT (RLFS) and a VGG16 fine search based on Keras (VFSK). The specific construction process of the JLHS search method is shown in
Figure 6.
In indoor low-light environments, the JBCRM image-enhancement method is used to preprocess the acquired image, and then, the JLHS method is used to search the image. The specific steps are as follows:
- (1)
In the offline feature database generation stage, firstly, a monocular vision camera (DJI Pocket 2) is used to collect low-light images of the selected experimental site, and the corresponding position coordinates of the images are recorded to form a low-light image database. Then, the images in the low-light database are preprocessed using the JBCRM image-enhancement method, thus obtaining the JBCRM-enhanced image database. Finally, the images in the JBCRM-enhanced image database are feature extracted using the feature extraction algorithm SIFT to form SIFT feature vectors, thus constructing an offline feature database.
- (2)
In the query stage, the target image is first taken using the monocular vision camera (DJI Pocket 2) at the same experimental site. Then, the JBCRM image-enhancement method is used to preprocess the target image. Finally, the feature extraction algorithm SIFT is used to extract the features of the JBCRM-enhanced image to form the SIFT feature vector, and the SIFT feature vector is stored.
- (3)
For the target search, the offline feature database’s SIFT feature vectors and the JBCRM-enhanced images’ SIFT feature vectors are first matched using the RLFS coarse search method, thus yielding the coarse search images with the top six numbers of matched points. Then, the last layer of convolutional features of the coarse search images and the last layer of convolutional features of the JBCRM-enhanced images are compared using the VFSK fine search technique. By arranging the results in descending order based on the cosine similarity, the most similar database image to the target image is obtained. This database image’s position coordinate is the target image’s position coordinate.
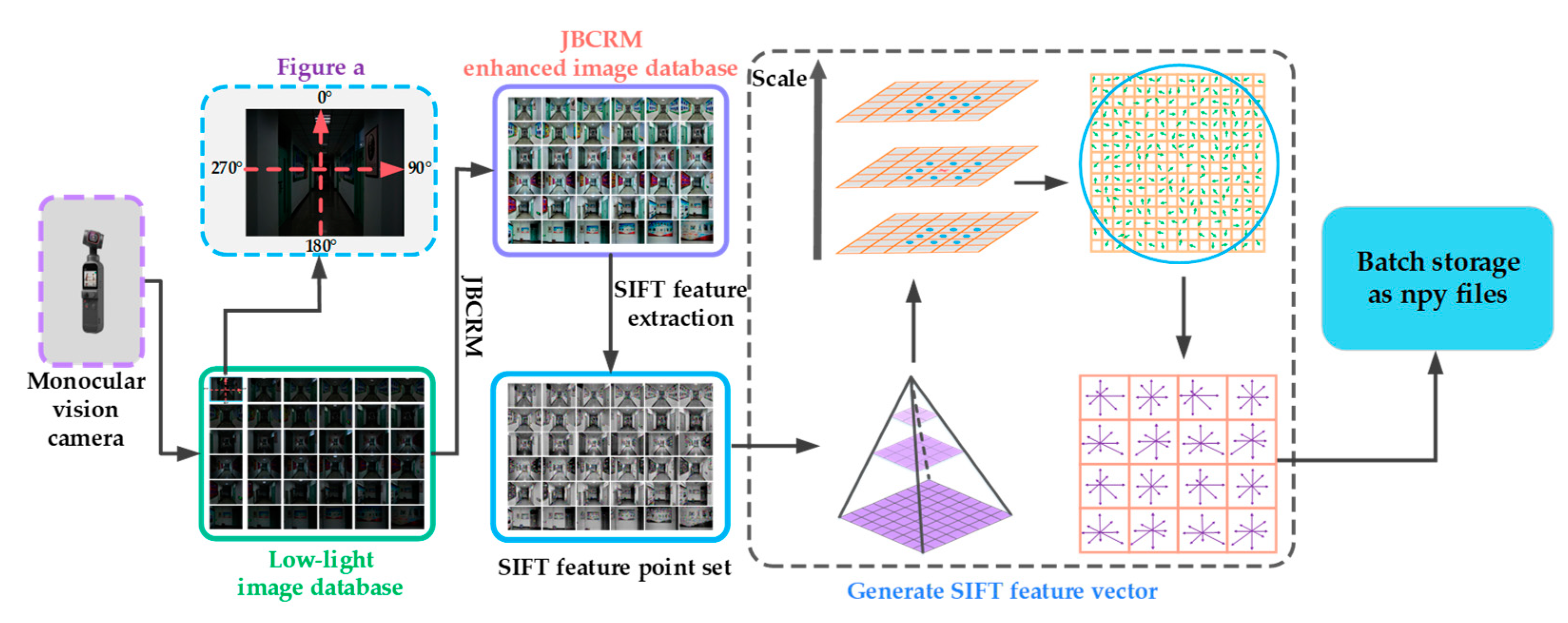
4.1. Construction of Offline Feature Database
In order to scientifically evaluate the effectiveness and feasibility of the JLHS target search method, this paper selected indoor corridors during morning and evening hours as the experimental site. In
Figure 7, the center of Figure a is taken as the origin of the world coordinates, its horizontal direction is taken as the x-axis of the world coordinate system, and its vertical direction is taken as the y-axis of the world coordinate system. Meanwhile, five acquisition points are selected in the x-axis direction, and fifteen acquisition points are selected in the y-axis direction. Each acquisition point acquires images at 90° intervals in the clockwise direction, and a total of 300 images are acquired. The corresponding position coordinates of each image are recorded, thus forming a low-light image database. Then, the JBCRM image-enhancement method is used to preprocess the low-light database, thus obtaining the JBCRM-enhanced image database. Finally, the feature extraction algorithm SIFT is used to extract the SIFT features of the images in the JBCRM-enhanced image database. Meanwhile, SIFT features are generated into SIFT feature vectors and stored in the form of npy files, thereby completing the construction of the offline feature database. The process of building the offline feature database is shown in
Figure 7.
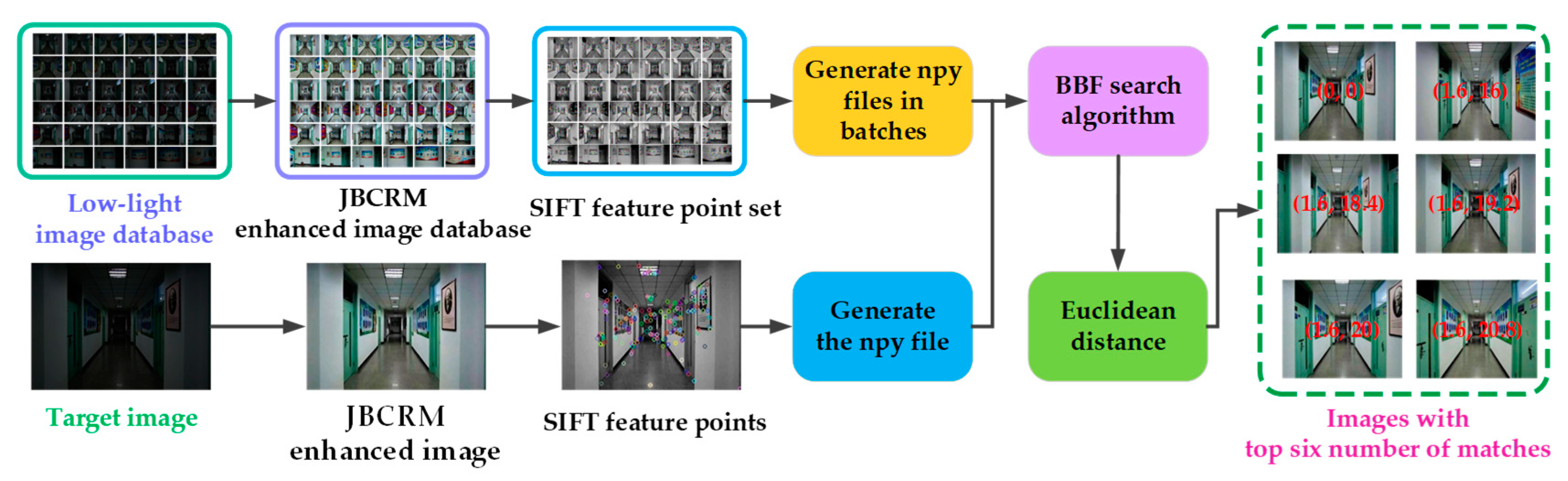
4.2. Constructing RLFS-Based Coarse Search Technology
Aiming at the problem of the long search time of the traditional SIFT target search methods, this paper uses the best bin first (BBF) search method to match the target image with the offline database image. At the same time, this paper uses the Euclidean distance as the similarity measure of key points in two images to reduce the probability of a mismatch. The specific steps of the RLFS-based coarse search technique are shown in
Figure 8.
Firstly, the JBCRM image-enhancement method is used to preprocess the image in the low-light image database and the target image, respectively, thus obtaining the corresponding JBCRM-enhanced image database and JBCRM-enhanced image. Secondly, the SIFT feature extraction algorithm is utilized to extract features from images in the JBCRM-enhanced image database, thereby acquiring the set of SIFT feature points and forming the feature vectors, which are saved as npy files. Simultaneously, the SIFT feature extraction algorithm is used to extract features from the JBCRM-enhanced image, yielding the corresponding SIFT feature points and constructing the feature vector, which is stored as an npy file. Thirdly, the SIFT feature vectors of the JBCRM-enhanced image database are matched with the SIFT feature vector corresponding to the JBCRM image by using the BBF search method, respectively. Then, the Euclidean distance is used to calculate the similarity between the JBCRM-enhanced image and each image in the JBCRM-enhanced image database, and the similarity is sorted in descending order. Finally, the top six similarity images in the JBCRM-enhanced image database are selected as the coarse search images. Among them, the details of the SIFT feature vector construction process are as follows.
4.2.1. Establishment of Scale Space and Detection of Extreme Points
The whole scale space establishment process of the image is as follows: for an image of size
, the image is convolved with the Gaussian kernel, thereby obtaining Gaussian spaces of different scales, which are expressed as:
where
is the Gaussian function with variable parameters;
is the scale space factor;
is the spatial function at a specific scale.
To obtain stable Gaussian scale space extreme points, the original image is convolved with
G with different scale factors. Then, the images of two adjacent Gaussian spaces are subtracted to obtain the difference of Gaussians (DOG), thus eliminating the unstable edge points, whose mathematical expression is:
To ensure the stability and uniqueness of the SIFT features, each sampling point on the DOG needs to be compared with 8 neighboring points at the same scale, as well as 18 points corresponding to the neighboring scales above and below, which are 26 points in total. If the DOG value of this sampling point is greater than or less than the other 26 points, the point is set as a local extreme point.
4.2.2. Precisely Determine the Location of the Feature Points
In the candidate set of local extremum points of scale space, there are many low-contrast and unstable edge points, which directly affect the stability and anti-interference ability of matching. Therefore, these edge points need to be removed to improve the accuracy of matching. The specific removal principle is as follows: the principal curvature value is relatively large in the direction of the edge gradient, while the principal curvature value is small along the edge direction. The principal curvature value of the candidate feature points is proportional to the eigenvalue of the 2 × 2 Hessian matrix. The expression of the Hessian matrix is:
Let
and
be the eigenvalues of
H, and the value of
is greater than
. At the same time, let
, and then, the trace
Tr(
H) and determinant
Det(
H) of
H are as follows:
If , it is retained as the feature point; otherwise, it is discarded.
4.2.3. Direction Distribution of Feature Points
To ensure the rotational invariance of the feature points, it is necessary to assign a principal direction for each feature point based on the magnitude and direction of the gradient. The specific process of determining the main direction of feature points is as follows: firstly, the direction of each feature point is calculated. Then, the gradient information of the pixels around the feature point is counted, and the corresponding gradient histogram is plotted at 45-degree intervals. Finally, the peak of the gradient histogram is selected as the principal direction of the feature point.
For the scale space image
, the size and direction of the gradient at each feature point are as follows:
where
is the magnitude of the gradient and
is the direction of the gradient.
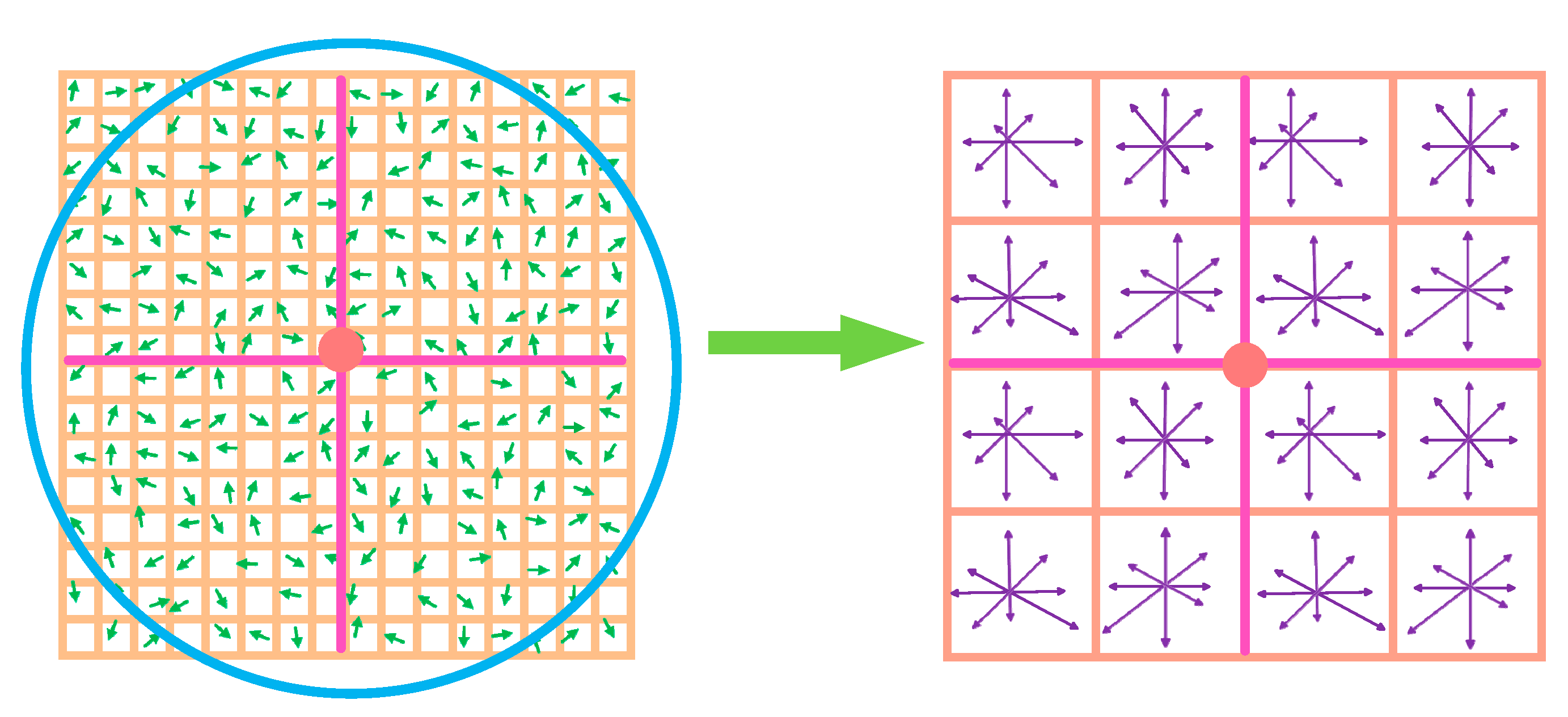
4.2.4. Generating SIFT Feature Point Descriptors
Through the above three processes, the position, scale, and direction information of the feature points are obtained successively. In order to improve the probability of the correct matching of feature points, it is necessary to establish corresponding feature descriptors for each feature point. The specific steps are as follows: firstly, rotate the coordinate axis to align with the main direction of the feature points mentioned above. Then, take a 16 × 16 window centered around the feature point within the same scale domain. Next, divide the window into 4 × 4 sub-block regions (seed points), as shown in
Figure 9. Finally, the gradient histograms of each seed point in eight directions (every 45° is a direction) are counted based on Equations (21) and (22), and each gradient histogram is Gaussian weighted, so as to weaken the influence of the place far away from the feature points on the feature points.
In the left figure, its center position is the position of the feature point, and each cell represents a pixel in the scale space where the neighborhood of the feature point is located. The arrow in each small box corresponds to the direction of the gradient at the feature point, the length of the arrow represents the gradient magnitude, and the circle indicates the range of Gaussian weights. In the right image, the gradient histogram of eight directions is drawn in each 4 × 4 box, and the cumulative value of each gradient direction is calculated, thus forming a seed point. Each feature point consists of 4 × 4 seed points, each with vector information in eight directions, thereby producing a 16 × 8 128-dimensional SIFT feature vector.
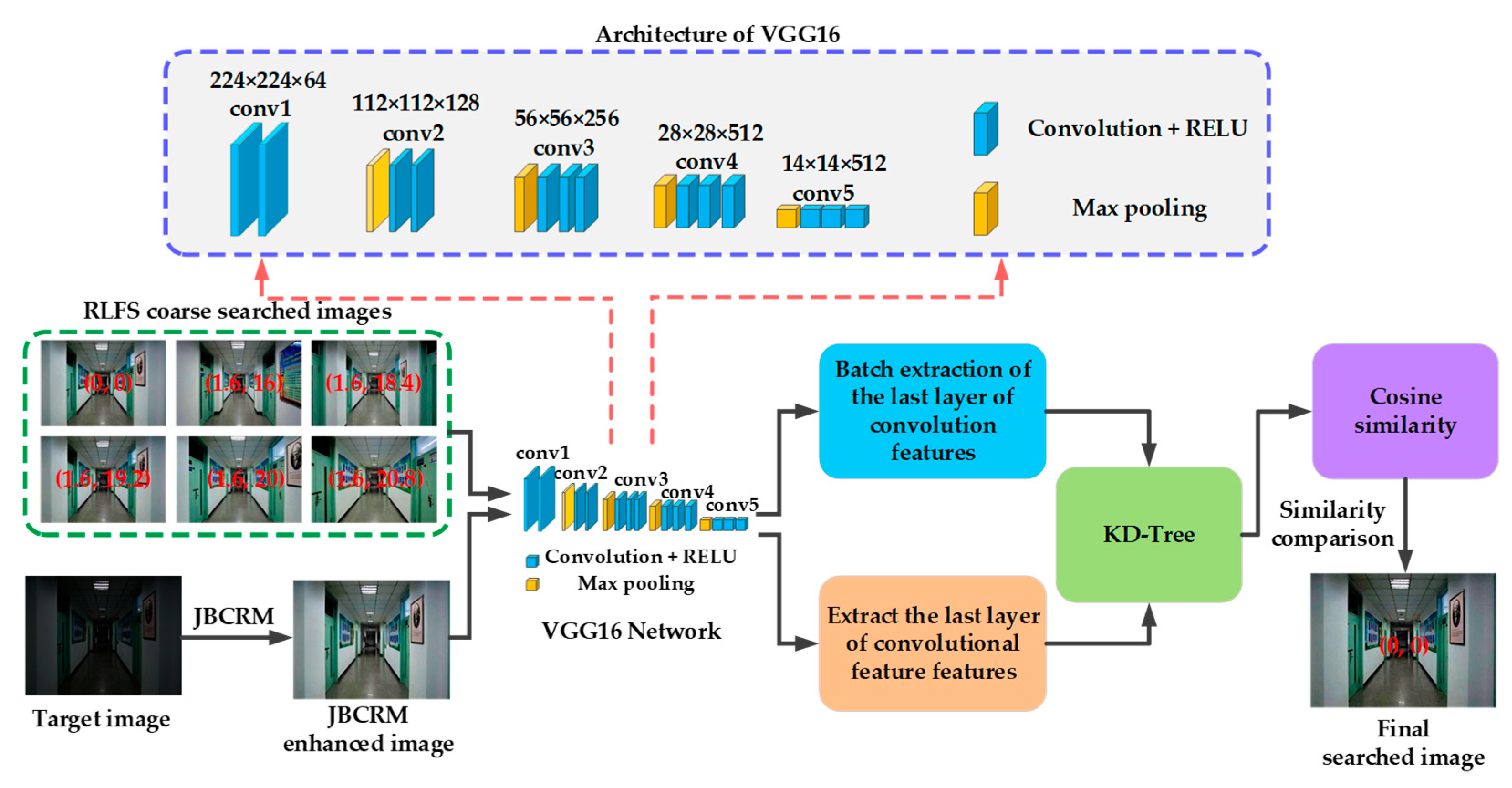
4.3. Constructing VFSK-Based Fine Search Technology
VGG16 was proposed by the Visual Geometry Group of the University of Oxford in 2014, and its specific structure is shown in
Figure 10. VGG16 consists of five convolutional blocks and three fully connected layers. The first two convolutional blocks consist of two convolutional layers and a pooling layer, while the last three convolutional blocks consist of three convolutional layers and a pooling layer. In this paper, conv
i is used to denote the
ith convolutional block, conv
i_
j denotes the
jth convolutional layer of the
ith convolutional block, and conv
i_pool denotes the pooling layer of the
ith convolutional block. The number of filters in the 5 convolutional blocks is 64, 128, 256, 512, and 512, respectively. Compared with the traditional convolutional neural network model, the VGG16 network structure is very simple, which can enhance the richness and hierarchy of the feature representations, thus better capturing the visual features. Therefore, the VGG16 is chosen as the base model for the fine search in this paper.
After using the above RLFS coarse search, there is still the problem of mismatching, which leads to low accuracy in the target search. As a result, this paper builds the VGG16 fine search based on Keras (VFSK) in the fine search stage, thereby increasing the target search accuracy even more, as illustrated in
Figure 10.
To improve the search accuracy and efficiency, VFSK fine search technology employs the VGG16 model to extract high-level semantic features from the conv5 layer, thus completing the accurate search of the target images. The details of the VFSK fine search technology are as follows: firstly, the convolutional feature mapping is extracted from the conv5 layer of each coarsely searched image and JBCRM-enhanced image, respectively, using the VGG16 model with a total number of channels of 512, thus constituting the corresponding h5 feature vectors. Then, the cosine similarity is used to calculate the similarity between the h5 feature vector corresponding with each coarse search image and the h5 feature vector corresponding with the JBCRM-enhanced image, and the obtained similarity is sorted using the K—means clustering method, thereby obtaining the coarse search image that has the highest similarity with the JBCRM-enhanced image. The position coordinates corresponding to this coarse search image are the position coordinates of the target image.
Among them, the calculation formula for the cosine similarity between two feature vectors is as follows:
where
a and
b are two different h5 feature vectors.
is the cosine similarity of the two h5 feature vectors, which ranges from [−1, 1]. The larger the cosine value, the more similar the two h5 feature vectors are represented.
5. Simulation and Result Analysis of Target Search
In order to evaluate the JLHS target search method proposed in this paper, 178 low-light images are taken at any position of the selected experimental site as experimental images for the target search. The specific content of the target search experiment is as follows: firstly, the 178 experimental images captured are preprocessed using the JBCRM method, thereby obtaining the corresponding JBCRM-enhanced images. Then, Höschl IV [
37], Yin [
38], Chhabra [
39], Kopparthi [
40], and the JLHS method proposed in this paper are used to match the JBCRM-enhanced images with the images in the offline database, respectively, thus obtaining the database image that is most similar to the target image. The position coordinates corresponding to this database image are the position coordinates of the target image. The performance comparison results of each target search method are shown in
Table 7.
As can be seen from
Table 7, compared with other target search methods, the average search error of the JLHS method is reduced by 91.90% at most and 18.33% at least. The average search time is reduced by 72.52% at most and 36.84% at least. As a result, the JLHS method proposed in this paper significantly increases the target search accuracy while decreasing the search time.
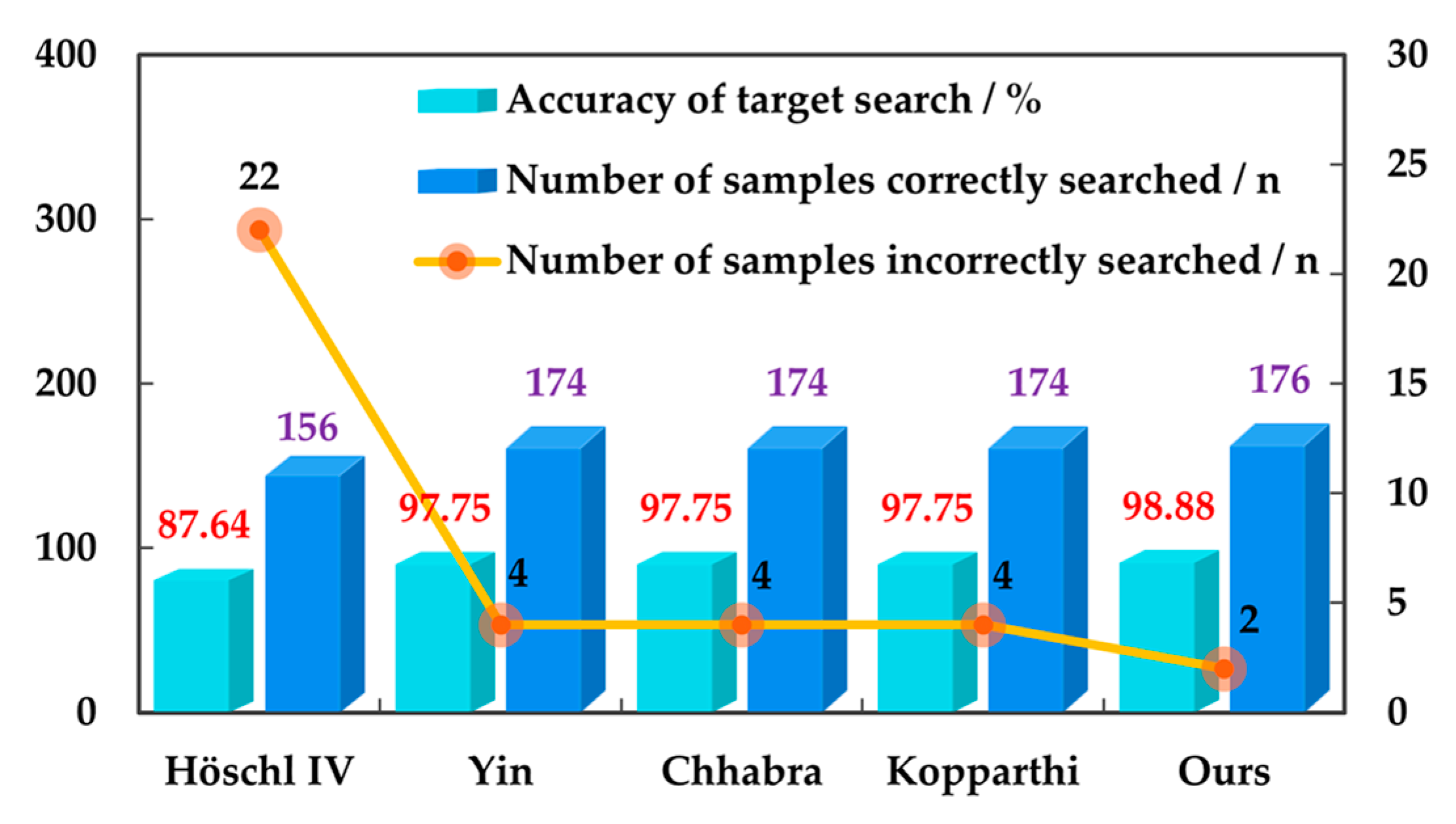
In 178 sets of target search experiments, the accuracy rate of each target search method is shown in
Figure 11. Among them, the formula for the search accuracy is as follows:
where
P represents the accuracy rate,
m represents the number of correctly searched samples, and
N represents the number of searched samples.
As can be seen from
Figure 11, compared to the other four methods, the JLHS method proposed in this paper has the least number of erroneous search samples and the highest search accuracy. Meanwhile, compared to the other four approaches, the JLHS method improves the accuracy by 12.83% at most and 1.16% at least. Therefore, the JLHS method proposed in this paper effectively overcomes the problem of a difficult target search in indoor low-light environments.
6. Conclusions
Aiming at the difficulty of target searching in indoor low-light environments, this paper proposes a JLHS target search method based on JBCRM image preprocessing enhancement. The JBCRM approach solves the problem of difficult feature extraction and gives superior visual data for the succeeding target search task by enhancing the dark area features and eliminating noise interference during the image preprocessing stage. Compared to other image-enhancement techniques, the PSNR of the JBCRM-enhanced images is boosted by 34.24% at most and 2.61% at least. The Laplace operator is increased by 54.47% at most and 3.49% at least. From the evaluation metrics, the JBCRM-enhanced images have less noise, higher clarity, and more details. In terms of feature extraction, the maximum increase in the number of feature points in JBCRM-enhanced images is 303.44%, and the minimum increase is 20.51% as compared to the original low-light images. In the target search phase, the JLHS method designed in this paper improves the matching accuracy between the target image and the offline database image by combining the local feature SIFT and high-level semantic features to describe the image, thus boosting the target search accuracy. Compared with other target search methods, the average search error of the JLHS method is only 9.8 cm, and the average search time is only 360 ms. Experimental results demonstrate the effectiveness of the proposed method in the task of target searching in indoor low-light environments, which is able to obtain the position information of the target more accurately. In our future work, we will reduce the dimension of the local feature descriptor SIFT by using the effective dimension reduction algorithm, which improves the efficiency of SIFT feature extraction and further shortens the search time.



 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}































































































