
Partial Order-Based Decoding of Rate-1 Nodes in Fast Simplified Successive-Cancellation List Decoders for Polar Codes


Abstract
:1. Introduction
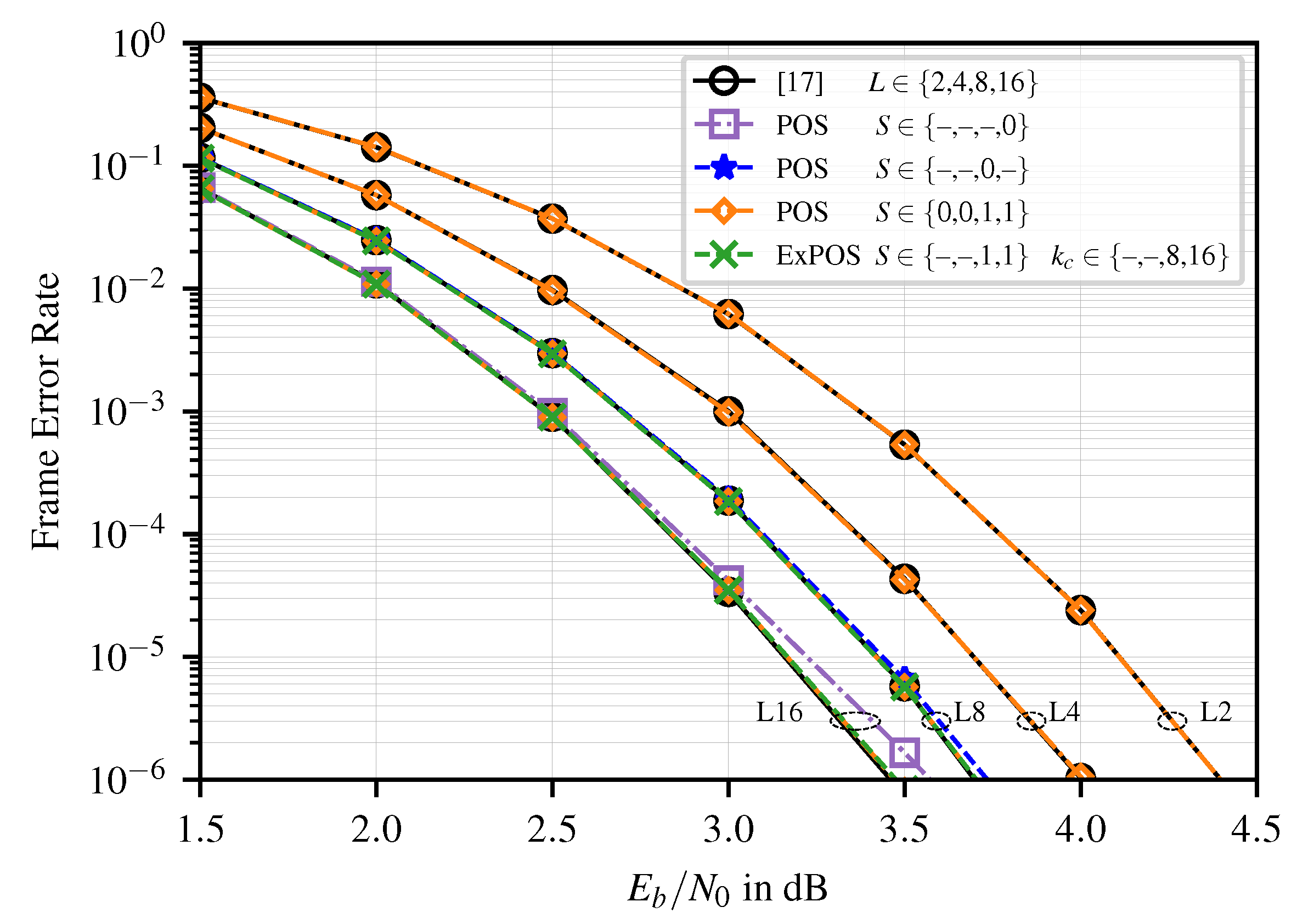
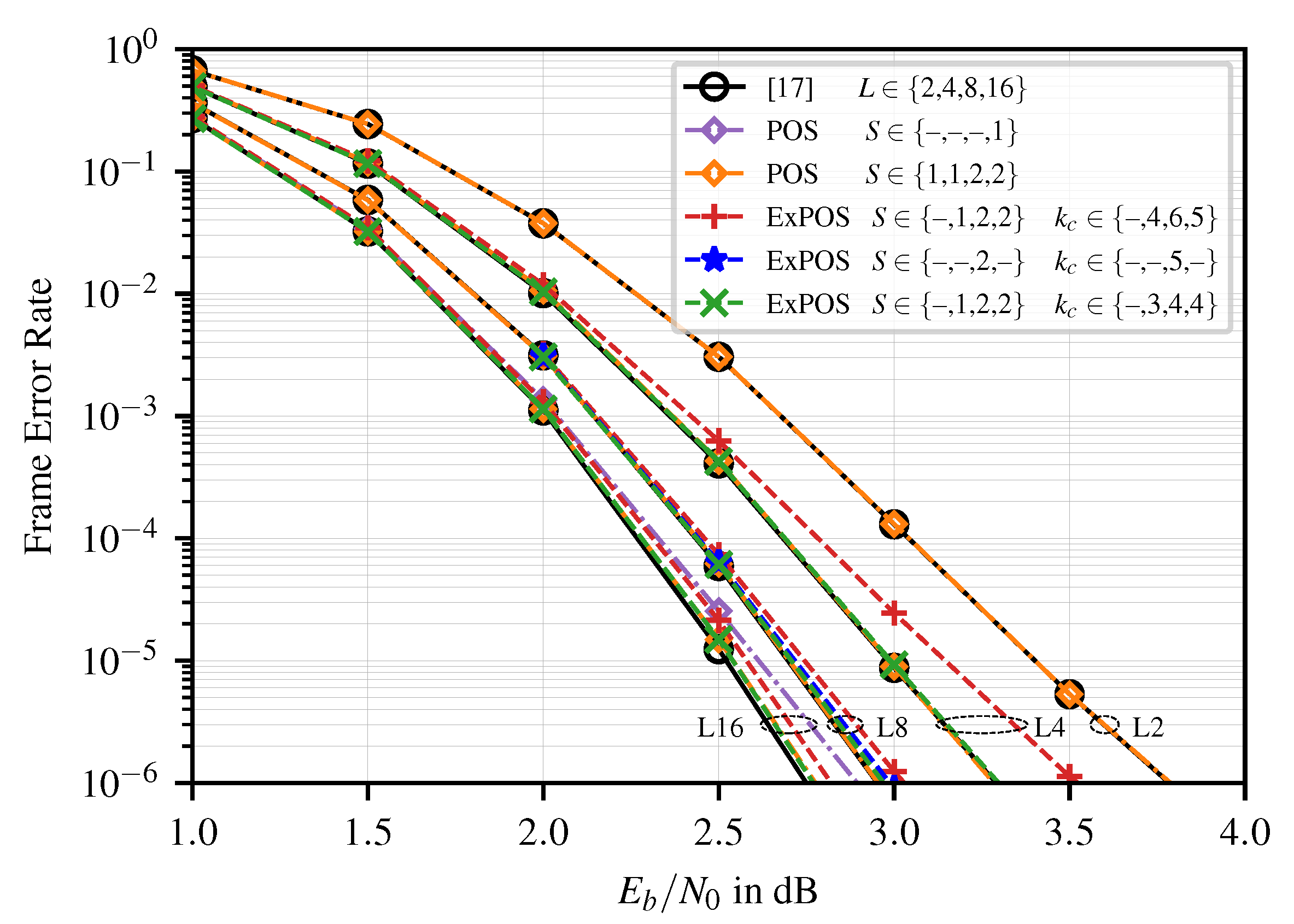
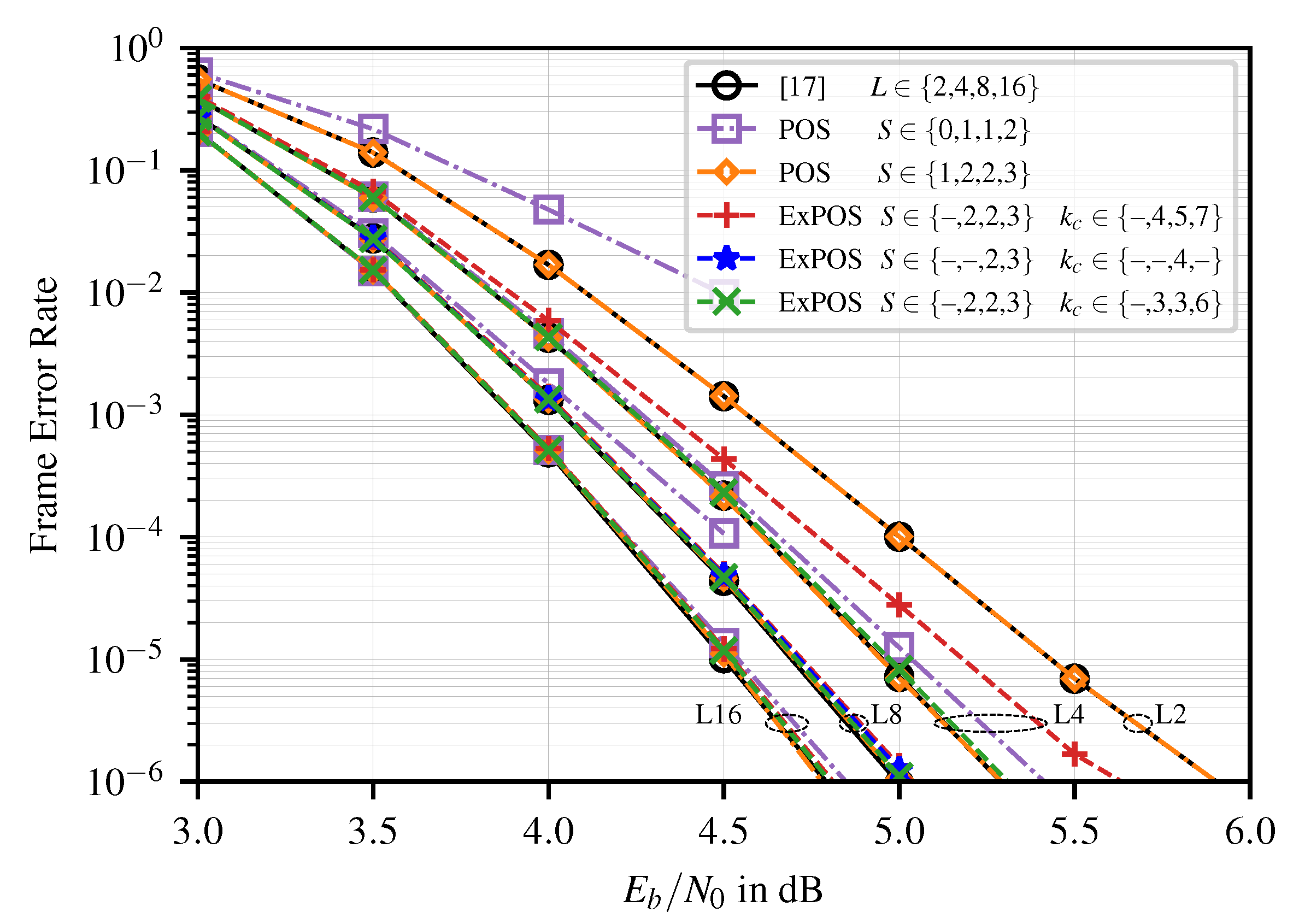
- We present a new algorithm for the candidate generation in Rate-1 nodes of SCL decoders based on a partial order of the candidates. With this algorithm, the number of candidates is significantly reduced. We show that the presented algorithm preserves the error-correction performance of conventional SCL decoding.
- We introduce an extended threshold-based candidate selection scheme for practical SCL decoder implementations, which further reduces the number of considered decoding paths with negligible error-correction performance degradation. Compared to the state-of-the-art, this scheme can reduce the number of considered candidates and the sorter complexity in terms of the number of comparators by up to % and %, respectively.
- We present new architectures for Rate-1 nodes, which are based on the presented candidate generation algorithms. Using these architectures in unrolled Fast-SSCL decoder implementations significantly reduces the implementation costs. We present a set of decoder implementations in a 28 Fully Depleted Silicon on Insulator (FD-SOI) Complementary Metal-Oxide-Semiconductor (CMOS) technology for a Polar code with to compare the implementation costs in terms of area efficiency and energy efficiency with state-of-the-art decoders. Improvements of up to % and % in the aforementioned metrics are observed, respectively.
2. Background
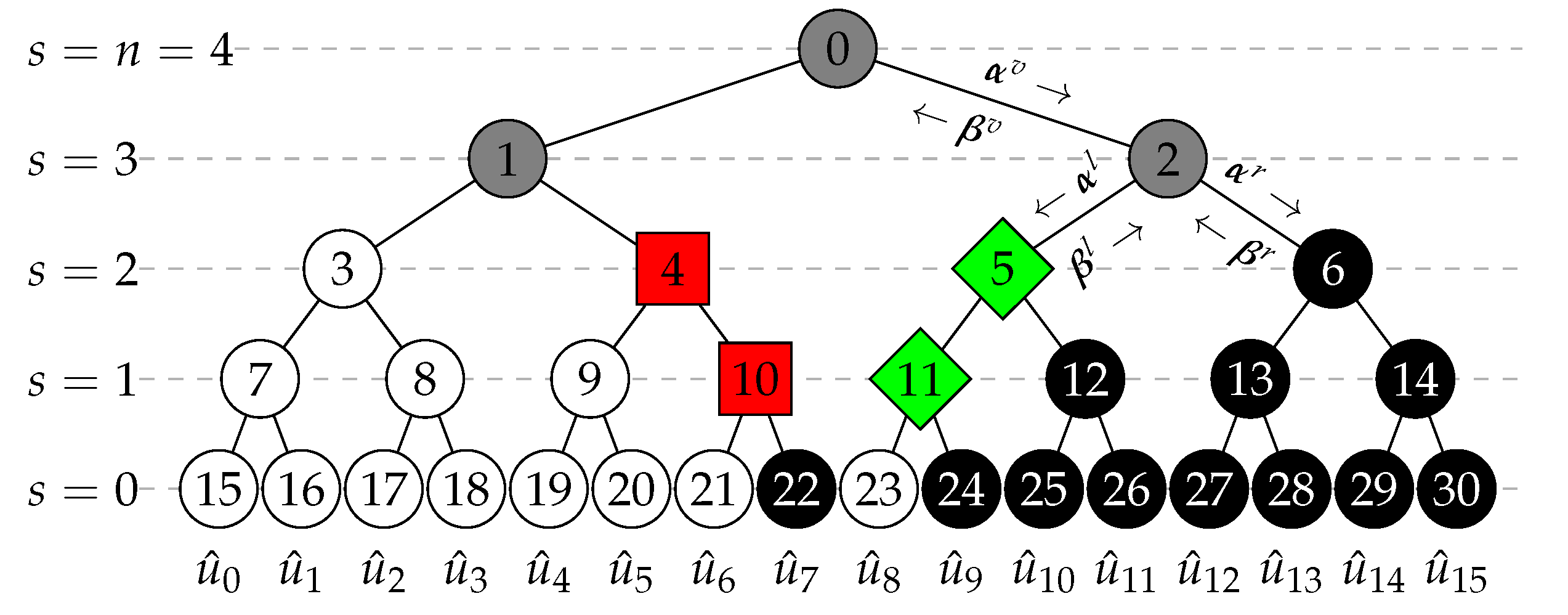
2.1. SC and Fast-SSC Decoding
2.2. SCL Decoding
2.3. Fast-SSCL Decoding and Rate-1 Nodes
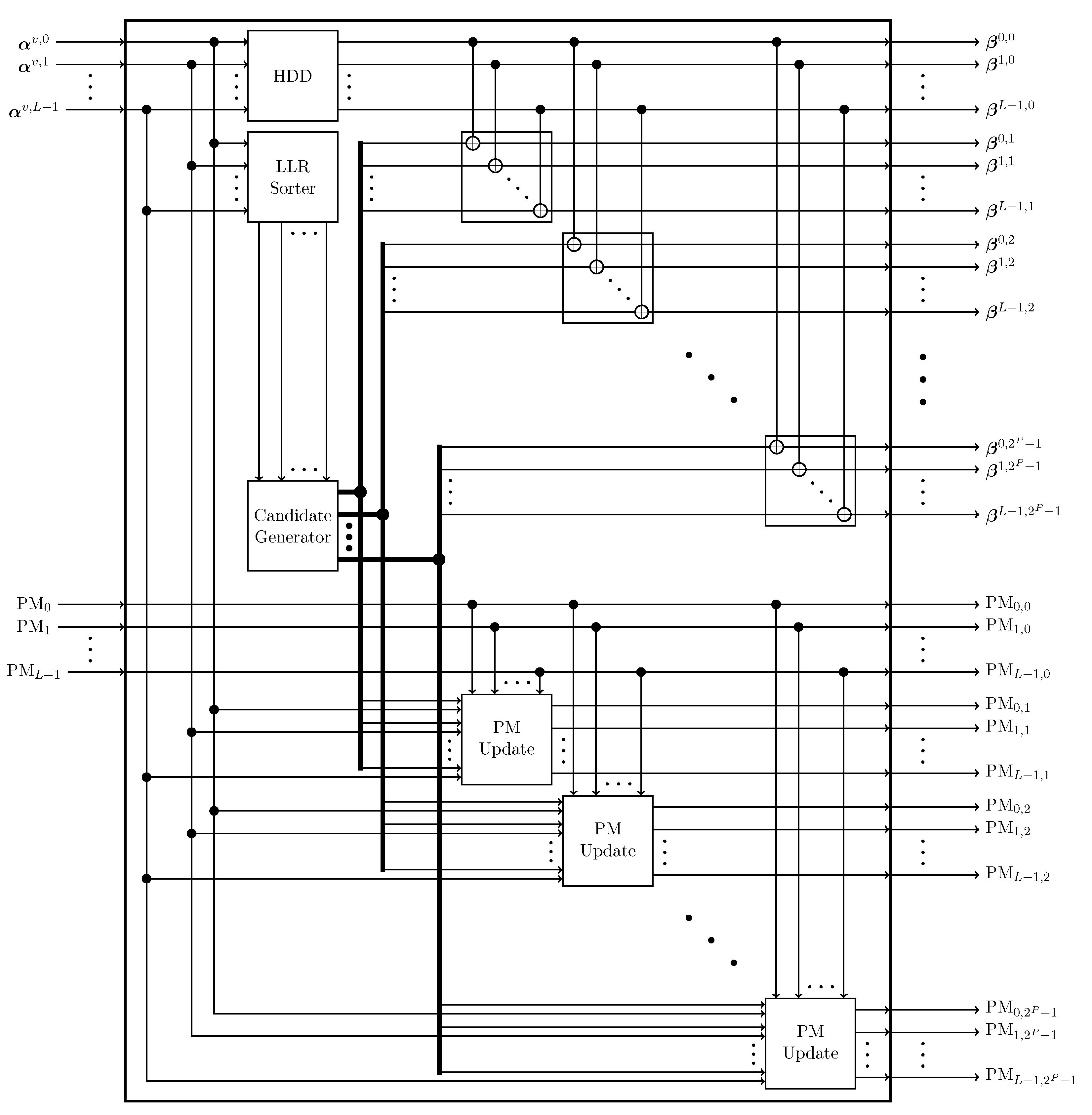
3. Candidate Generation in Parallel Decoding of Rate-1 Nodes
3.1. Path Exclusion Based on PM Relations
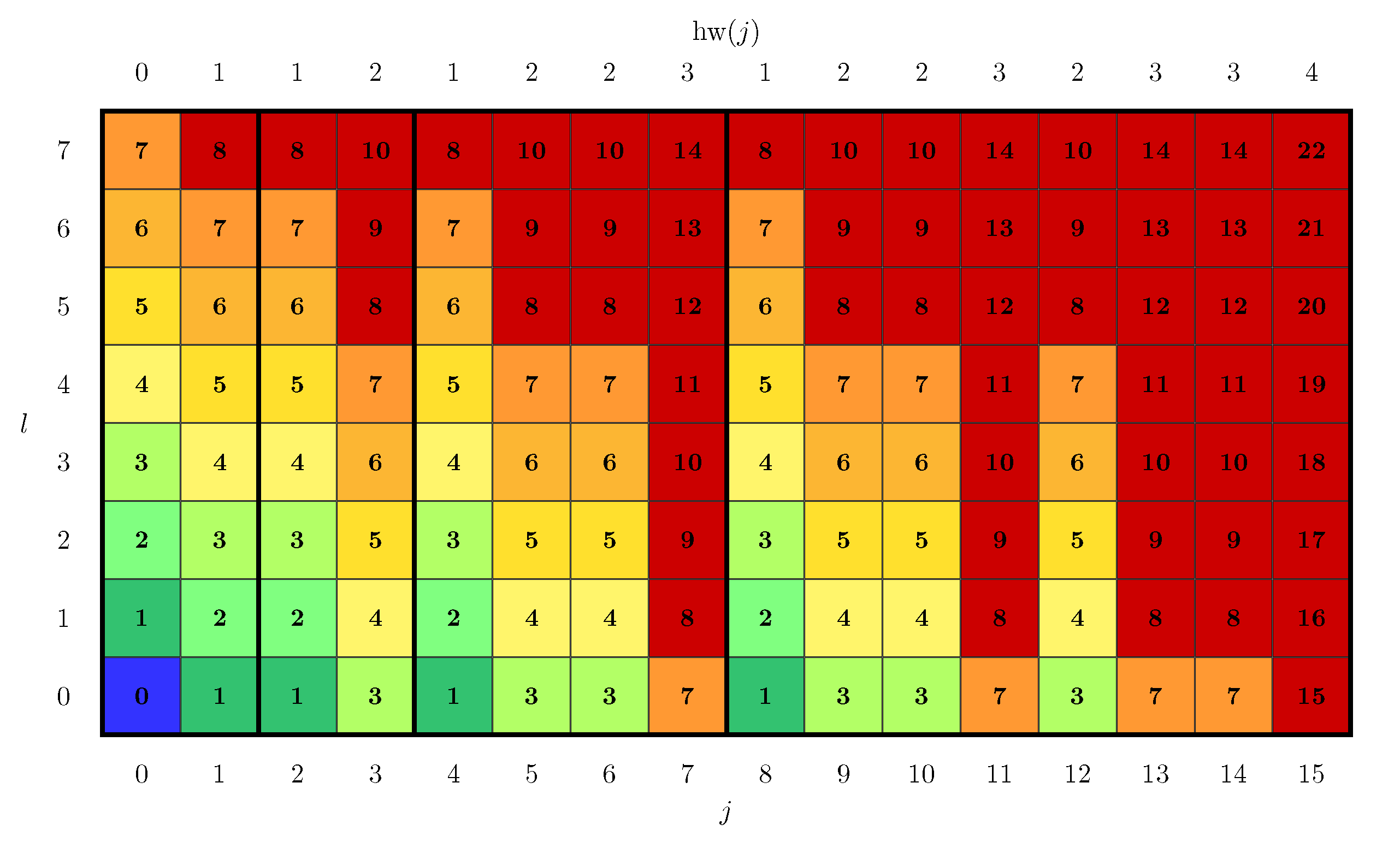
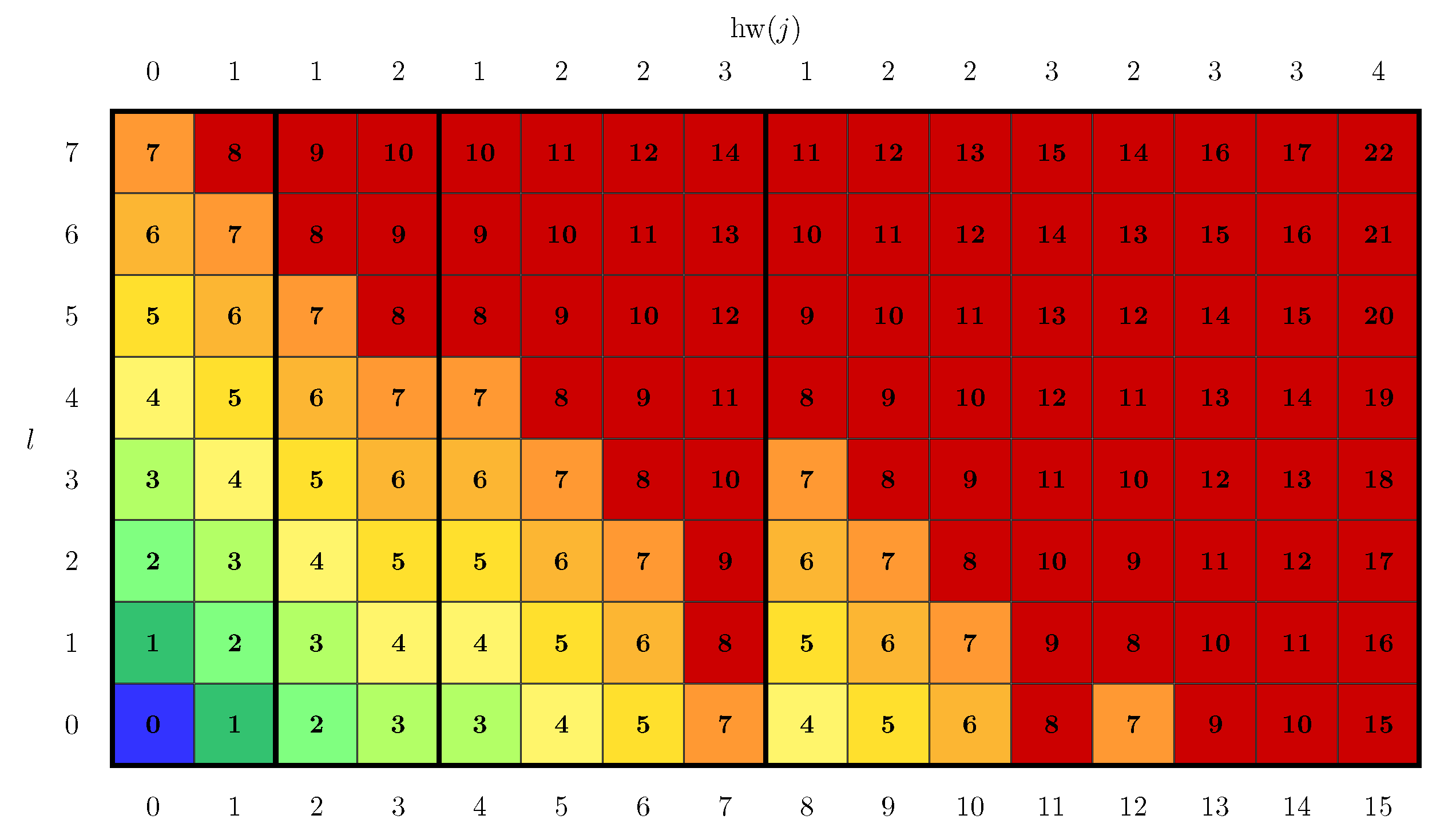
- One flipped bit: According to (7), all PMs of the candidates with exactly one flipped bit are greater than or equal to of the HDD estimation candidate of path l because the one corresponding is added. Thus, the minimal index these candidates can have after sorting is . The candidate index j in this case is a power of 2 because for all .
- Two flipped bits: The PMs of the candidates generated by flipping exactly two bits are greater than or equal to and greater than or equal to the two PMs of the candidates where the bits at the same two positions were flipped separately. To clarify, let us suppose three different candidates with indices exhibit and , respectively. These two bits in which candidates and differ from the HDD candidate 0 are flipped simultaneously in candidate . Then,andConsidering a new candidate with , the relation between candidates and is an open question. A priori, the relation between and is unknown, since can be smaller than, greater than, or equal to . Therefore, we can only state with certainty that the three candidates , and are always more likely than candidate . Consequently, the minimal index candidates with exactly two flipped bits can have after sorting is .
- x flipped bits: In general, the number of PMs known to be less than or equal to with equals . This is the case because the number of candidates generated by the combinations of flipping the same x bits is and candidate j is the one where all x bits are flipped simultaneously. It follows that the minimal index candidate j can have after sorting all forks is .
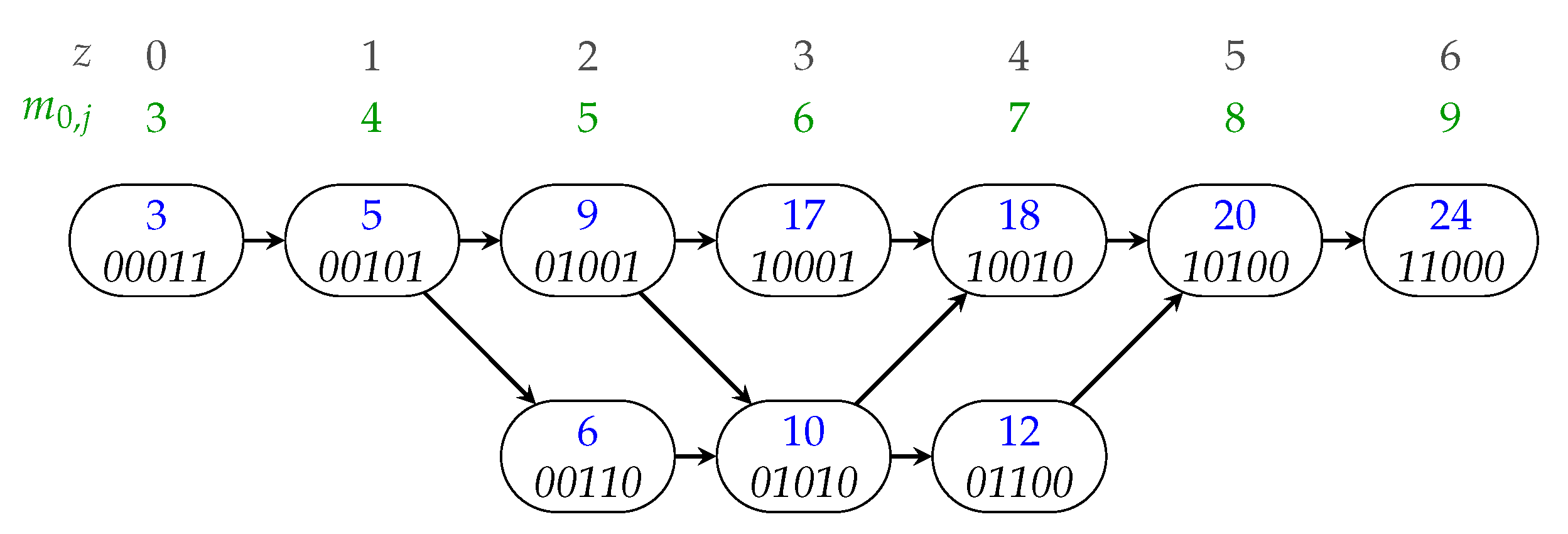
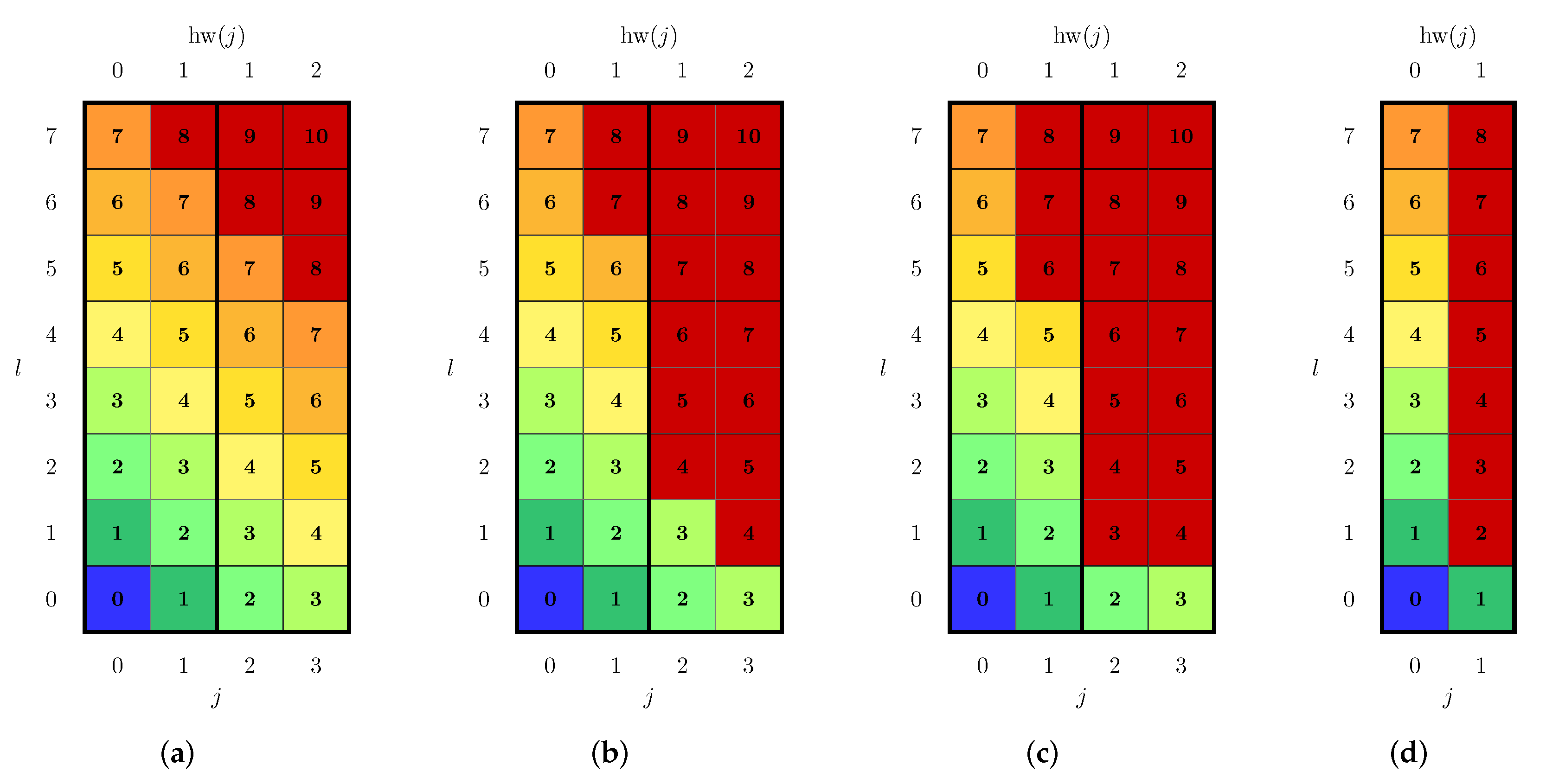
3.2. Candidate Generation Based on Partially Ordered Candidate Sets
| Algorithm 1 Partial order based candidates generation. |
 |
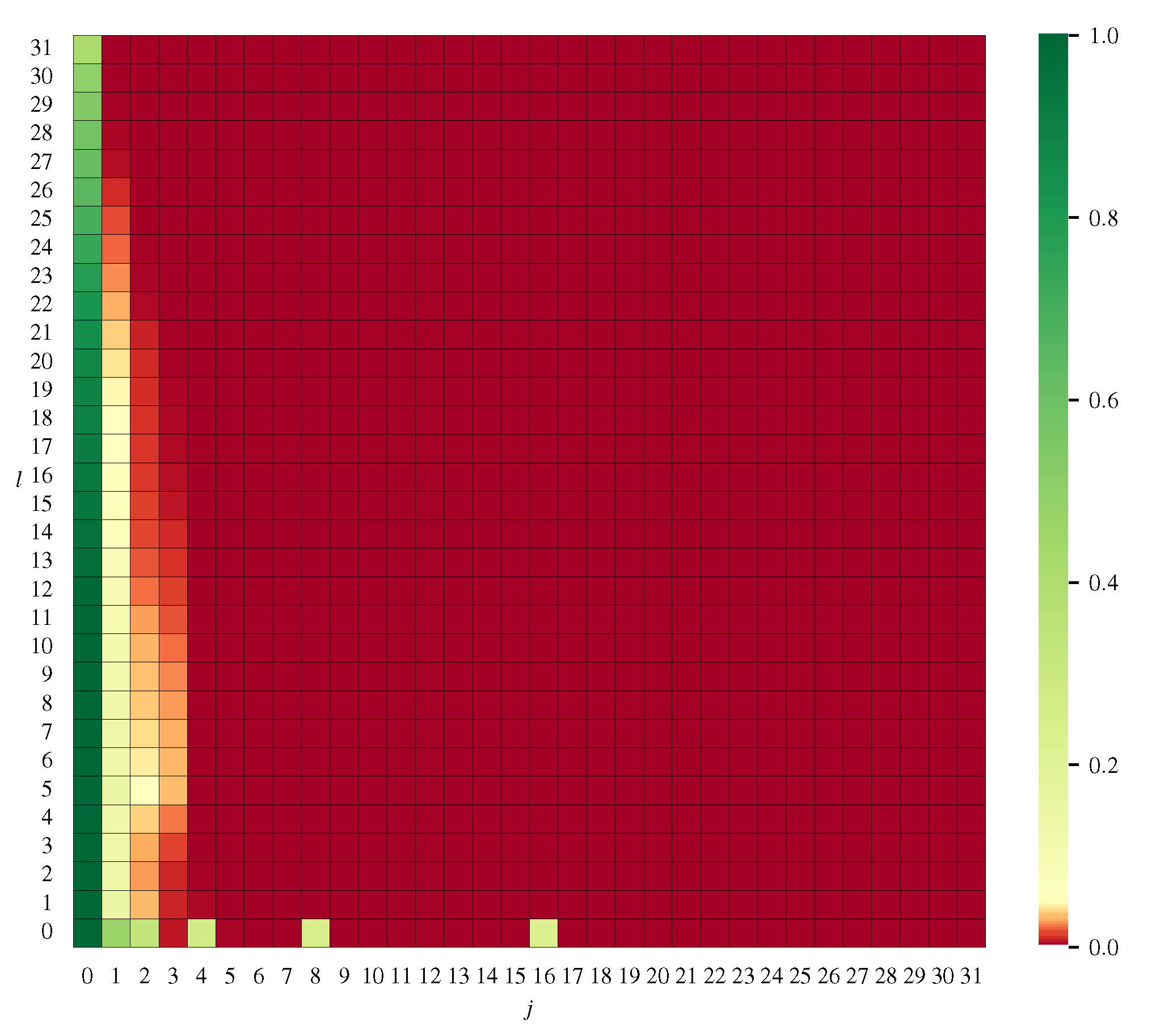
3.3. Partial Order-Based Candidate Generation with Threshold
3.4. Extended Threshold Partial Order-Based Candidate Generation
- Candidates with are the only needed candidates with . All other candidates with can be discarded.
- The number of candidates with equal j can be decreased linearly until only the candidate originating from path needs to be considered.
- line 4:
- Set instead of looping over the number of flipped bits.
- line 8:
- Replace the stopping condition by .
- line 19:
- Append candidate when and according to (32).
| Algorithm 2 Iterative threshold approximation. |
 |
4. Results and Discussion
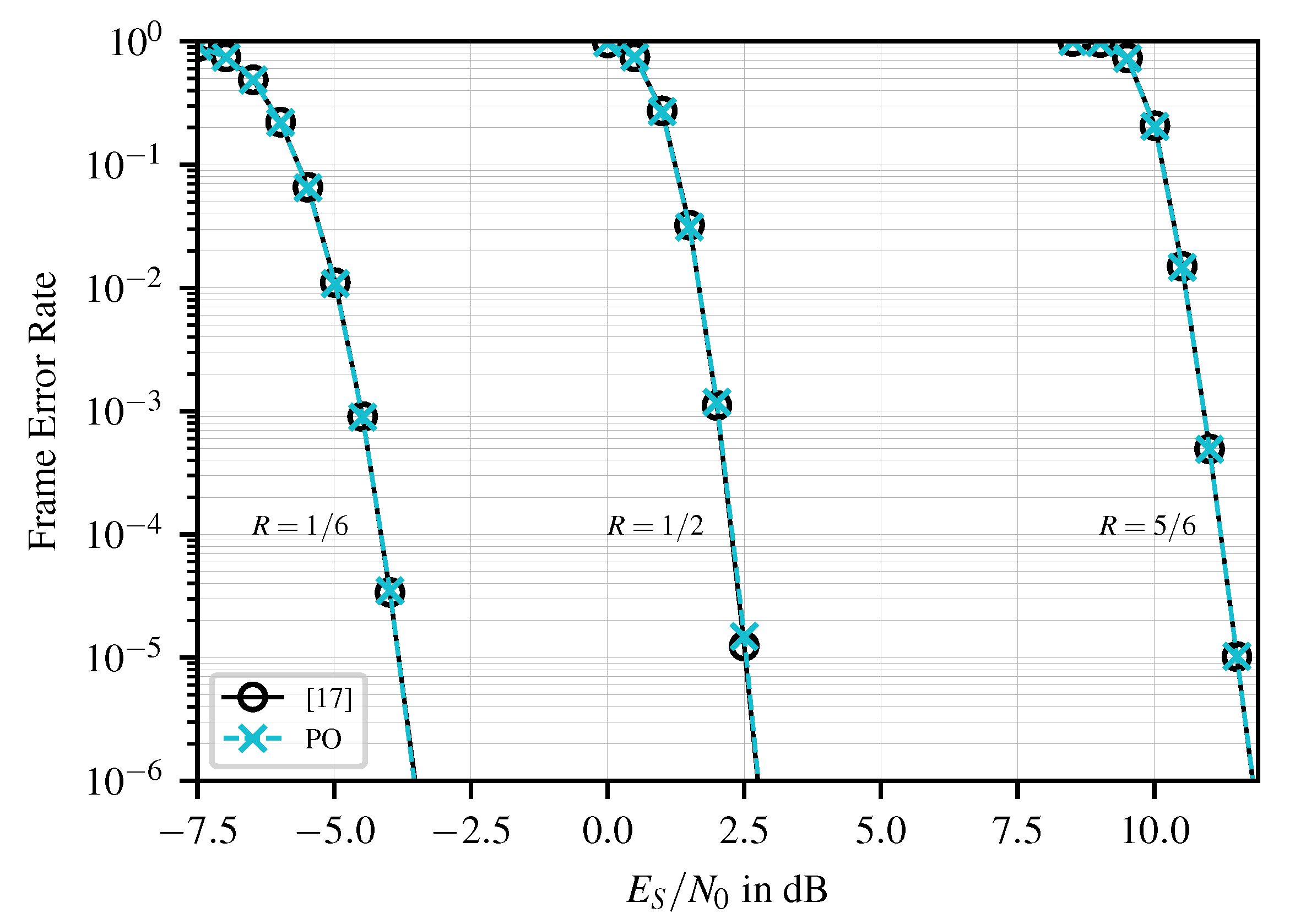
4.1. Error-Correction Performance
4.2. Complexity Estimations
4.3. Implementation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Arikan, E. Channel Polarization: A Method for Constructing Capacity-Achieving Codes for Symmetric Binary-Input Memoryless Channels. IEEE Trans. Inf. Theory 2009, 55, 3051–3073. [Google Scholar] [CrossRef]
- Alamdar-Yazdi, A.; Kschischang, F.R. A Simplified Successive-Cancellation Decoder for Polar Codes. IEEE Commun. Lett. 2011, 15, 1378–1380. [Google Scholar] [CrossRef]
- Sarkis, G.; Giard, P.; Vardy, A.; Thibeault, C.; Gross, W.J. Fast Polar Decoders: Algorithm and Implementation. IEEE J. Sel. Areas Commun. 2014, 32, 946–957. [Google Scholar] [CrossRef] [Green Version]
- Afisiadis, O.; Balatsoukas-Stimming, A.; Burg, A. A Low-Complexity Improved Successive Cancellation Decoder for Polar Codes. In Proceedings of the 2014 48th Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 2–5 November 2014; pp. 2116–2120. [Google Scholar] [CrossRef] [Green Version]
- Tal, I.; Vardy, A. List Decoding of Polar Codes. IEEE Trans. Inf. Theory 2015, 61, 2213–2226. [Google Scholar] [CrossRef]
- Niu, K.; Chen, K. CRC-Aided Decoding of Polar Codes. IEEE Commun. Lett. 2012, 16, 1668–1671. [Google Scholar] [CrossRef]
- Zhang, Z.; Zhang, L.; Wang, X.; Zhong, C.; Poor, H.V. A Split-Reduced Successive Cancellation List Decoder for Polar Codes. IEEE J. Sel. Areas Commun. 2016, 34, 292–302. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Zhang, H.; Li, J.; Bao, X.; Xie, K. An Improved Path Splitting Decision-Aided SCL Decoding Algorithm for Polar Codes. IEEE Commun. Lett. 2021, 25, 3463–3467. [Google Scholar] [CrossRef]
- Peng, Y.; Bao, J.; Liu, X. An Improved Path Splitting Strategy on Successive Cancellation List Decoder for Polar Codes. IET Commun. 2021, 15, 1198–1209. [Google Scholar] [CrossRef]
- Sarkis, G.; Giard, P.; Vardy, A.; Thibeault, C.; Gross, W.J. Fast List Decoders for Polar Codes. IEEE J. Sel. Areas Commun. 2016, 34, 318–328. [Google Scholar] [CrossRef] [Green Version]
- Hashemi, S.A.; Condo, C.; Gross, W.J. Fast Simplified Successive-Cancellation List Decoding of Polar Codes. In Proceedings of the 2017 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar] [CrossRef] [Green Version]
- Kestel, C.; Johannsen, L.; Griebel, O.; Jimenez, J.; Vogt, T.; Lehnigk-Emden, T.; Wehn, N. A 506Gbit/s Polar Successive Cancellation List Decoder with CRC. In Proceedings of the 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, London, UK, 31 August–3 September 2020; IEEE: London, UK, 2020; pp. 1–7. [Google Scholar] [CrossRef]
- Lee, H.Y.; Pan, Y.H.; Ueng, Y.L. A Node-Reliability Based CRC-Aided Successive Cancellation List Polar Decoder Architecture Combined With Post-Processing. IEEE Trans. Signal Process. 2020, 68, 5954–5967. [Google Scholar] [CrossRef]
- Kim, D.; Kim, S.; Kim, I.; Kim, M.G. Reliability Based Candidate Selection of List Decoding for Polar Code. In Proceedings of the 2021 IEEE 93rd Vehicular Technology Conference (VTC2021-Spring), Helsinki, Finland, 25–28 April 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Zhao, Y.; Yin, Z.; Wu, Z.; Xu, M. Minimum-Combinations Set-Based Rate-1 Decoder for Fast List Decoding of Polar Codes. IEEE Commun. Lett. 2021, 25, 3185–3189. [Google Scholar] [CrossRef]
- Leroux, C.; Raymond, A.J.; Sarkis, G.; Gross, W.J. A Semi-Parallel Successive-Cancellation Decoder for Polar Codes. IEEE Trans. Signal Process. 2013, 61, 289–299. [Google Scholar] [CrossRef]
- Balatsoukas-Stimming, A.; Parizi, M.B.; Burg, A. LLR-Based Successive Cancellation List Decoding of Polar Codes. IEEE Trans. Signal Process. 2015, 63, 5165–5179. [Google Scholar] [CrossRef] [Green Version]
- Hashemi, S.A.; Condo, C.; Gross, W.J. Simplified Successive-Cancellation List Decoding of Polar Codes. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 815–819. [Google Scholar] [CrossRef]
- Hashemi, S.A.; Condo, C.; Gross, W.J. A Fast Polar Code List Decoder Architecture Based on Sphere Decoding. IEEE Trans. Circuits Syst. Regul. Pap. 2016, 63, 2368–2380. [Google Scholar] [CrossRef]
- Hashemi, S.A.; Condo, C.; Gross, W.J. Fast and Flexible Successive-Cancellation List Decoders for Polar Codes. IEEE Trans. Signal Process. 2017, 65, 5756–5769. [Google Scholar] [CrossRef] [Green Version]
- Wu, W.; Siegel, P.H. Generalized Partial Orders for Polar Code Bit-Channels. IEEE Trans. Inf. Theory 2019, 65, 7114–7130. [Google Scholar] [CrossRef]
- Schürch, C. A Partial Order for the Synthesized Channels of a Polar Code. In Proceedings of the 2016 IEEE International Symposium on Information Theory (ISIT), Barcelona, Spain, 10–15 July 2016; pp. 220–224. [Google Scholar] [CrossRef]
- Tal, I.; Vardy, A. How to Construct Polar Codes. IEEE Trans. Inf. Theory 2013, 59, 6562–6582. [Google Scholar] [CrossRef] [Green Version]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| L | Number of Paths | Reduction of Paths [%] Related to | Number of Comparators | Reduction of Comparators [%] Related to | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ExPOS Equation (35) | [20] Equation (5) | [15] ∆ Equation (34) | [20] | [15] ∆ | ExPOS Equation (36) | [20] Equation (33) | [15] ∆ Equation (36) | [20] | [15] ∆ | |||
| 2 | 1 | 2 | 3 | 4 | 4 | 25.0 | 25.0 | 3 | 6 | 6 | 50.0 | 50.0 |
| 4 | 1 | 3 | 6 | 8 | 8 | 25.0 | 25.0 | 15 | 28 | 28 | 46.4 | 46.4 |
| 2 | 3 | 8 | 12 | 16 | 33.3 | 50.0 | 28 | 56 | 66 | 50.0 | 57.6 | |
| 8 | 1 | 8 | 9 | 16 | 16 | 43.8 | 50.0 | 36 | 120 | 120 | 70.0 | 70.0 |
| 2 | 3 | 17 | 24 | 32 | 29.2 | 46.9 | 136 | 240 | 496 | 43.3 | 72.6 | |
| 2 | 4 | 15 | 24 | 32 | 37.5 | 53.1 | 105 | 240 | 496 | 56.3 | 78.8 | |
| 2 | 5 | 14 | 24 | 32 | 41.7 | 56.3 | 91 | 240 | 496 | 62.1 | 81.7 | |
| 16 | 1 | 16 | 17 | 32 | - | 46.9 | - | 136 | 496 | - | 72.6 | - |
| 2 | 4 | 41 | 48 | - | 14.6 | - | 820 | 992 | - | 17.3 | - | |
| 3 | 6 | 33 | 64 | - | 48.4 | - | 528 | 1488 | - | 64.5 | - | |
| 3 | 7 | 30 | 64 | - | 53.1 | - | 435 | 1488 | - | 70.8 | - | |
| ExPOS | PO | [12] | ||||||
|---|---|---|---|---|---|---|---|---|
| L | 2 | 4 | 8 | 4 | 8 | 2 | 4 | 8 |
| 1 | 2 | 2 | 3 | 7 | 1 | 3 | 7 | |
| 2 | 3 | 4 | - | - | - | - | - | |
| - | - | - | - | - | - | - | 4 | |
| Frequency [MHz] | 502 | 503 | 500 | 503 | 442 | 502 | 499 | 418 |
| Throughput [Gbps] | 64 | 64 | 64 | 64 | 57 | 64 | 64 | 53 |
| Latency [ns] | 41.8 | 63.7 | 90.1 | 65.5 | 108.5 | 41.8 | 64.1 | 141.3 |
| Area [mm] | 0.22 | 0.51 | 1.47 | 0.55 | 1.89 | 0.23 | 0.56 | 3.15 |
| Area Efficiency | ||||||||
| [Gbps/mm] | 295 | 125 | 44 | 117 | 30 | 283 | 113 | 17 |
| Power Total [W] | 0.23 | 0.50 | 1.51 | 0.54 | 1.82 | 0.25 | 0.56 | 3.34 |
| Energy Efficiency | ||||||||
| [pJ/bit] | 3.52 | 7.78 | 23.59 | 8.31 | 32.18 | 3.87 | 8.75 | 62.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Johannsen, L.; Kestel, C.; Griebel, O.; Vogt, T.; Wehn, N. Partial Order-Based Decoding of Rate-1 Nodes in Fast Simplified Successive-Cancellation List Decoders for Polar Codes. Electronics 2022, 11, 560. https://doi.org/10.3390/electronics11040560
Johannsen L, Kestel C, Griebel O, Vogt T, Wehn N. Partial Order-Based Decoding of Rate-1 Nodes in Fast Simplified Successive-Cancellation List Decoders for Polar Codes. Electronics. 2022; 11(4):560. https://doi.org/10.3390/electronics11040560
Chicago/Turabian StyleJohannsen, Lucas, Claus Kestel, Oliver Griebel, Timo Vogt, and Norbert Wehn. 2022. "Partial Order-Based Decoding of Rate-1 Nodes in Fast Simplified Successive-Cancellation List Decoders for Polar Codes" Electronics 11, no. 4: 560. https://doi.org/10.3390/electronics11040560