1. Introduction
Over the past few years, the global economy has undergone a substantial period of rapid development. However, this growth has been accompanied by increasing energy demands, expanding resource supplies, and intensifying environmental pollution [
1]. In response to these pressing challenges, the power Internet of Things (PIoT) technology has been steadily addressing existing issues. PIoT capitalizes on its sensitive transmission capability, real-time communication prowess, intelligent control capacity, and robust information security capability. As a result, it seamlessly integrates traditional Internet of Things (IoT) concepts and transforms into a cutting-edge system for efficiently operating and managing power systems [
2,
3]. This concept fully utilizes the mature advantages of IoT technology in areas such as smart sensors, wide-area communication, and edge computing. Resource coordination is accomplished via intelligent network control and grid distribution.
The application of PIoT technology spans across diverse sectors, encompassing industrial production, smart cities, agricultural production, environmental monitoring, security surveillance, and home automation, achieving significant economic benefits [
4]. However, PIoT also faces security issues. Due to its structure and operational characteristics, it demands high-security protection to ensure the confidentiality, integrity, and availability of data, meeting the requirements of information security. It is more complex than conventional IoT as it involves a greater variety of devices and denser node deployment. Therefore, the overall security risks of PIoT are also higher. Additionally, the health condition of power equipment is a crucial factor in ensuring the secure and reliable operation of the power system [
5]. In the power grid, the interconnection between terminal devices and edge nodes allows for the comprehensive and flexible perception of electricity consumption status, enabling intelligent sensing of real-time operational conditions and digitalized maintenance. This facilitates the efficient processing of collected information and prompt intelligent decision-making. For power companies, important tasks encompass monitoring and the intelligent management of power equipment status, and key aspects include the collection, storage, and processing of large amounts of power equipment data [
6]. Therefore, applying machine learning technology to the management, analysis, and decision-making of power equipment data can effectively enhance the efficiency of related work in PIoT.
Existing applications of machine learning and PIoT typically involve training large-scale machine learning models by uploading local data from edge nodes to cloud servers. Data management, analysis, and decision-making are conducted through centralized approaches based on cloud storage [
7]. In traditional power systems, direct data transmission occurs between edge nodes and cloud servers. However, this method of data transmission is vulnerable to attacks by malicious third parties, resulting in data breaches that compromise the security of power data and lead to significant power incidents [
8]. Moreover, future trends will require real-time data privacy and security to reduce the risk of data leaks and enhance the overall reliability of the power grid. Centralized data centers no longer suffice in addressing the confidentiality, authenticity, integrity, and reliability requirements of the information security of power IoT data.
Federated learning, as a machine learning approach, involves multiple data owners and a central server collaborating to train models [
9]. It enables the maintenance of multiple distributed training datasets simultaneously. Federated learning offers the opportunity to employ more sophisticated models while simultaneously safeguarding privacy and the security of local data. It facilitates the collaborative training of machine learning models among several data owners without the necessity of transmitting data to a central server. The benefits of federated learning stem from the fact that the raw data remain locally stored and are not exchanged or transmitted, replacing the conventional approach of aggregating all data directly to achieve training goals [
10].
1.1. Challenge
Due to the mutual exclusivity among multiple edge nodes in the smart grid of Internet of Things (IoT), data sharing between these edge nodes becomes challenging, affecting the data aggregation capability in the smart grid of IoT. To address this issue, the federated learning (FL) framework enables data sharing among multiple edge nodes, ensuring effective data aggregation in the power sector.
While federated learning is the way to go with training models in privacy-dependant systems, it does pose some problems that need to be addressed. One of the biggest concerns is data privacy. Firstly, attackers may infer original data by analyzing the shared parameters (parameter inversion). Even without direct access to raw data, they could deduce sensitive information by observing updates to the shared model’s parameters. Secondly, in some cases, the shared model might contain data labeling or partial data, leading to the potential leakage of sensitive information. Lastly, if the parameter updates lack noise, attackers may infer individual data by monitoring the gradient updates, thus compromising privacy.
Consequently, we propose an enhanced FL system that is specifically designed for data aggregation in the smart grid domain. The secure multi-party computation (SMC) [
11] and differential privacy (DP) [
12] is integrated with FL to mitigate inference attacks during the learning process and output process, thereby ensuring ample privacy guarantees. Within this system, a trusted third party can securely acquire model parameters from data holders and securely update the global model through aggregation. Throughout this entire process, the integrity of data from each party is maintained, ensuring that private information cannot be inferred from the global model [
13].
1.2. Contributions
This paper makes the following contributions:
(1) As a pioneering work, this paper presents an FL-based framework for the PIoT. Building upon the existing system architecture of the smart grid of IoT and the collaborative cloud–edge-end structure, the framework is enhanced to address the current privacy issues and leverage the characteristics of federated learning.
In this framework, machine learning tasks are executed at edge nodes, and only the model’s trained parameters are transmitted to the cloud server. This approach ensures the privacy and security of local data, as no data from any party involved in the learning process are leaked when compared to directly aggregating all power consumption data on the cloud server. The use of the cloud server for aggregating parameter data transmitted from edge nodes involves identity verification during the aggregation process, effectively guarding against forged identities of edge nodes within the framework, thus enhancing overall security.
(2) A secure aggregation algorithm based on federated learning is proposed. This method improves upon traditional federated learning approaches by combining secure multi-party computations and differential privacy techniques. By securely aggregating data, this method prevents attackers from decrypting the encrypted data during the learning process and inferring private information from intermediate results, thus providing sufficient privacy protection for the aggregation of data in the PIoT.
Moreover, this method utilizes aggregation algorithms based on secret sharing and key negotiations to support edge node dropouts, mid-process, while ensuring the security of data transmission. Through security analysis, it has been demonstrated that the proposed secure aggregation algorithm in this paper can achieve secure and reliable data aggregation from edge nodes to cloud servers in the PIoT.
(3) A privacy-preserving aggregation result verification algorithm is proposed. This method utilizes homomorphic hash functions and pseudo-random functions to protect data privacy while supporting edge nodes in verifying the aggregation results on the cloud server, ensuring the data correctness during the federated learning process. The performance analysis of the efficiency and overall overhead of the federated learning process demonstrates that the framework and method proposed in this paper can effectively execute FL tasks without compromising the normal efficiency of data model training.
(4) A performance evaluation concerning the efficiency and overall cost of the FL process demonstrates that the proposed framework and methods can effectively execute federated learning tasks with good model accuracy and a shorter learning time.
The subsequent sections of this paper are structured in the following manner.
Section 2 examines previous studies on privacy-preserving strategies in smart grids. Our suggested model is introduced in
Section 3.
Section 4 presents the preliminaries relevant to our scheme. In
Section 5 and
Section 6, we present the technical intuition and proposed scheme in detail. The security analysis is displayed in
Section 7. The experiments and performance analysis are presented in detail in
Section 8. Finally, a brief conclusion is drawn in
Section 9.
2. Related Works
We will conduct a comparative analysis of the existing work based on the features within our system. In reference [
14], Shokri and Shmatikov introduced a technique aimed at training neural networks on horizontally partitioned data by exchanging update parameters. This method ensures the privacy of participants’ training data while maintaining the accuracy of the resulting model. Additionally, Phong et al. [
15] presented a novel deep learning system that employs additive techniques to safeguard gradients from inquisitive servers, thus preserving user privacy, while assuming no degradation in the accuracy of deep learning with homomorphic encryption. Cao et al. [
16] proposed an optimized federated learning framework that incorporates a balance between local differential privacy, data utility, and resource consumption. They classified users based on varying levels of privacy requirements and provided stronger privacy protection for sensitive users. Moreover, Bonawitz et al. [
17] devised a secure aggregation approach for high-dimensional data and proposed a federated learning protocol that supports offline users using secure multi-party computing.
Aono et al. [
18] proposed a secure framework using homomorphic encryption to protect training data in logistic regression. Their approach ensures security even when dealing with large datasets. Nikolaenko et al. [
19] utilized homomorphic encryption and Yao’s scrambled circuit to construct a privacy-preserving system for ridge regression. This system outputs the best-fit curve without exposing the input data to additional information. Truex et al. [
20] suggested a method that combines DP and SMC to address inference threats and generate highly accurate models for federated learning techniques. Hu et al. [
21] proposed a privacy-preserving approach that ensures that user data satisfy DP and can be effectively learned for distributed user data. Chase [
22] combined DP and SMC with machine computing, presenting a feasible protocol for learning neural networks in a collaborative manner while protecting the privacy of each recording.
In contrast to prevailing methods, our system primarily enhances the FL process’s security by integrating advanced techniques, such as homomorphic encryption and DP. By doing so, it effectively safeguards against inference threats and ensures the privacy of users’ sensitive data, even if they decide to withdraw from the learning process before completion.
4. Preliminaries
We shall initially present the fundamental principles of FL, followed by an overview of the cryptographic source languages and modules employed in this framework.
4.1. Federated Learning
In federated learning, multiple participants can collaboratively train a model without the need to centralize their original datasets. Instead, each participant retains their own data and conducts model training locally. By employing techniques such as encryption and secure computation, participants can aggregate the model’s update information to achieve global performance improvement while preserving the privacy of individual data [
23]. Federated learning enables the sharing of knowledge among multiple organizations or individuals, promoting the development and application of machine learning under the premise of sensitive data protection.
There are two primary aspects of privacy in the context of learning: the privacy during the learning process [
24], and the privacy of the learning outcome [
25]. Privacy in the learning process refers to the process in which participants and the server transmit data between each other, and one of the participants infers the private data of the other participants from the data transmitted by the server. The privacy of the learning outcome involves the disclosure of intermediate data transmitted by participants and the server or the disclosure of the model (M) that the server ultimately obtains.
Privacy in the learning process: In an FL environment, participant ought to transmit the parameters of the local learning model to the server, and if an attacker obtains , it is possible to infer ’s private data . Therefore, the risk of inferring must be considered in a privacy-protected federated learning system.
To address this potential risk, secure multi-party computation (SMC) is a widely adopted approach. In SMC, the security model inherently involves multiple participants and provides robust security proof within a well-defined simulation framework. This framework ensures "absolute zero knowledge", meaning that each participant remains completely unaware of any information other than their own inputs and outputs. Zero-knowledge is highly desirable due to its enhanced data privacy and security features. However, achieving such properties often requires the implementation of more complex computational protocols, which might not always be practical. Under certain circumstances, accepting partial knowledge disclosure might be considered acceptable, as long as adequate security assurances are provided. While SMC effectively mitigates risks during the learning process, it is important to recognize that federated learning systems relying solely on SMC may still be susceptible to learning outcome inferences. Consequently, privacy-protecting FL systems must also account for potential inferences related to the learning outcomes. This entails incorporating additional measures or protocols to prevent unauthorized access or inference of sensitive information regarding the learning process results.
Privacy of learning outcomes: Learning outcomes encompass the intermediate outcomes attained throughout the federated learning process as well as the ultimate learning model. Several studies have demonstrated that an attacker can deduce information about the training data [
25]. Consequently, in a federated learning environment, the inference made regarding the learning outcome must adhere to the principle that the owner
of the data
is the only party capable of inferring any outcome related to
.
The differential privacy (DP) framework is commonly employed to address privacy concerns pertaining to output results [
26]. By introducing noise to the data through differential privacy, applying techniques like
k-anonymity or diversification, or by utilizing inductive methods to obfuscate sensitive attributes, the data become indistinguishable, safeguarding user privacy. Nonetheless, these approaches often necessitate the transfer of data to external entities, resulting in a trade-off between accuracy and privacy.
4.2. Differential Privacy
Differential privacy (DP) was introduced by Cynthia Dwork at Microsoft Research Labs and was initially designed for tabular data. It provides a statistical concept of privacy, allowing for highly accurate privacy-preserving statistical analysis of sensitive datasets [
27]. The level of DP is measured using privacy loss parameters (
,
), where smaller values of (
,
) correspond to higher privacy levels. Strictly speaking, for all
and neighboring datasets
D and
, if the randomization algorithm
A satisfies the following equation, it is considered (
,
)-differentially private [
28]:
In order to fulfill the requirements of DP, it is necessary to introduce noise into the output of the algorithm. Gaussian mechanisms are adopted in our scheme [
29].
4.3. Secret Sharing
Secret sharing is a sophisticated technique used to protect sensitive information by breaking it into multiple fragments and distributing those fragments to various entities, thereby concealing the original secret. The process of secret sharing involves allocating portions of the secret value to different individuals, and the shared value is obtained by summing up the contributions from each participant. Consequently, each party only gains access to a limited portion of the shared value, ensuring that no single entity possesses the complete secret. Depending on the specific scenario, it may be necessary to retrieve all or a predefined number of shared values to reconstruct the original secret. Shamir’s secret sharing is an exemplary method that relies on the polynomial equation theory to achieve a high level of information security. Additionally, it effectively utilizes matrix operations, leading to enhanced computational efficiency and accelerated processing [
30]. This approach is widely recognized for its robustness and practicality in safeguarding confidential data.
The secure aggregation algorithm proposed in this paper uses secret sharing based on Shamir’s secret sharing, which allows users to decompose their desired secret s into n fragments and distribute them to n other individuals for safekeeping. In this way, when the number of collected secret fragments is less than a threshold t, no one can obtain information about the secret s. However, when t individuals present their own secret fragments, the secret s can be reconstructed. The secret sharing comprises two processes: the sharing process, executed by the algorithm , produces a collection of secret fragments for each user u involved in the sharing. These fragments are uniquely associated with each user. Similarly, the recombination process, performed by the algorithm , combines the fragments and generates the reconstructed secret s.
4.4. Key Agreement
The Diffie–Hellman key agreement [
31] is adopted in our scheme, which comprises three algorithms:
is responsible for initialization,
is responsible for generating key pairs, and
is used for key negotiation. The aforementioned agreement keys are utilized for the exchange of information among users throughout the FL process.
4.5. Threshold Homomorphic Encryption
Threshold homomorphic encryption is a cryptographic scheme that allows for performing computations on encrypted data without decrypting it. It incorporates the concept of threshold cryptography, where multiple participants collectively hold shares of a secret key [
32]. The encryption scheme ensures that a certain threshold number of participants must collaborate to perform operations on the encrypted data. In threshold homomorphic encryption, encrypted values can be combined through specific homomorphic operations, such as addition or multiplication, while ensuring the secrecy of the original data remains intact. The encrypted result of the computation can be decrypted by the participants only when the threshold number of participants collaborate to collectively decrypt it. This cryptographic scheme provides a secure and distributed way to perform computations on sensitive data while preserving privacy. It allows for collaborative computation without revealing individual input and ensures that no single participant has complete access to the decrypted data [
33].
4.6. Homomorphic Hash Functions
The message (
M) undergoes encryption using a homomorphic hash function that is resistant to collisions [
34,
35].
In this case, both and are randomly chosen secret keys from . The homomorphic hash function possesses the following properties:
1. ←, .
2. ←, .
Additional properties of this homomorphic hash function are documented in [
34,
35].
4.7. Pseudorandom Functions
We utilize the pseudorandom functions [
36] in this paper. The pseudorandom function
uses the secret key
K to generate some arguments for the subsequent verification section:
In our scheme, the combination of a pseudo-random function and a homomorphic hash function is used to authenticate the aggregated results provided by the system [
37].
5. Technical Intuition
In this model, each user possesses a private vector of size m, includes the parameters of the model obtained by the user after local training using private data. We further assume that and its elements are for R in . The server (S) plays the role of an aggregator, which aggregates the data transmitted by each user (u) and trains the data to obtain a new model M. The objective of this model is to ensure the privacy of the user’s data during the FL process. The server only obtains the sum of the parameters provided by the users to the client , while each user has the ability to verify the final model returned by the .
In order to provide privacy to the model parameters
of the users, we add two random vectors,
and
, to each user’s
to compute
in perfect secrecy. We assume that the list of users is ordered and that there is a random vector
between each pair of users
. Before a user sends
to the server, the random vector
between
u and every other user
v is added to
, namely:
and, finally, the server calculates:
To ensure that a user cannot quit midway before committing
to the server, leading to the server’s inability to recover from
X, we implemented a Pseudorandom Generator
technique. This method involves generating random vectors using
PRG [
36,
37], and then sending the seeds used for generating these random vectors to all other users through threshold secret sharing of Diffie–Hellman secret shares. By doing so, even if a user
v decides to quit midway, the server can still reconstruct a random vector associated with
v using the shares provided by other users. And to prevent the server from obtaining the private data
of user
u by asking users for their shares of
, we add another random vector
to
, where
is seeded to a random vector that is unique to each user. Also, transferring these seeds for
PRG between users saves more communication overhead than transferring the entire random vector. Then, before a user sends
to the server, the user needs to calculate the following:
and the server needs to calculate
In the above formula, means all surviving users, and , where when , when , .
Prior to the secure aggregation round, the server needs to make a specific decision for each user u. The server can request either or shares, which are associated with u from each remaining user other than u. It is important to note that an honest user will never disclose both shares of the same user. Once the server has collected at least t shares of from the departing user and t shares of from all remaining users, it can subtract the remaining masks to obtain the precise aggregation result.
6. Proposed Scheme
We will provide an overview of the implementation of our FL system, focusing on addressing four key privacy concerns in the FL environment. Firstly, we aim to safeguard the privacy of local data throughout the FL process. Secondly, we are committed to preventing any potential disclosure of intermediate results or the final model. Furthermore, we guarantee the integrity of results even if a user exits prematurely. Lastly, we incorporate mechanisms that enable users to authenticate the results provided by the .
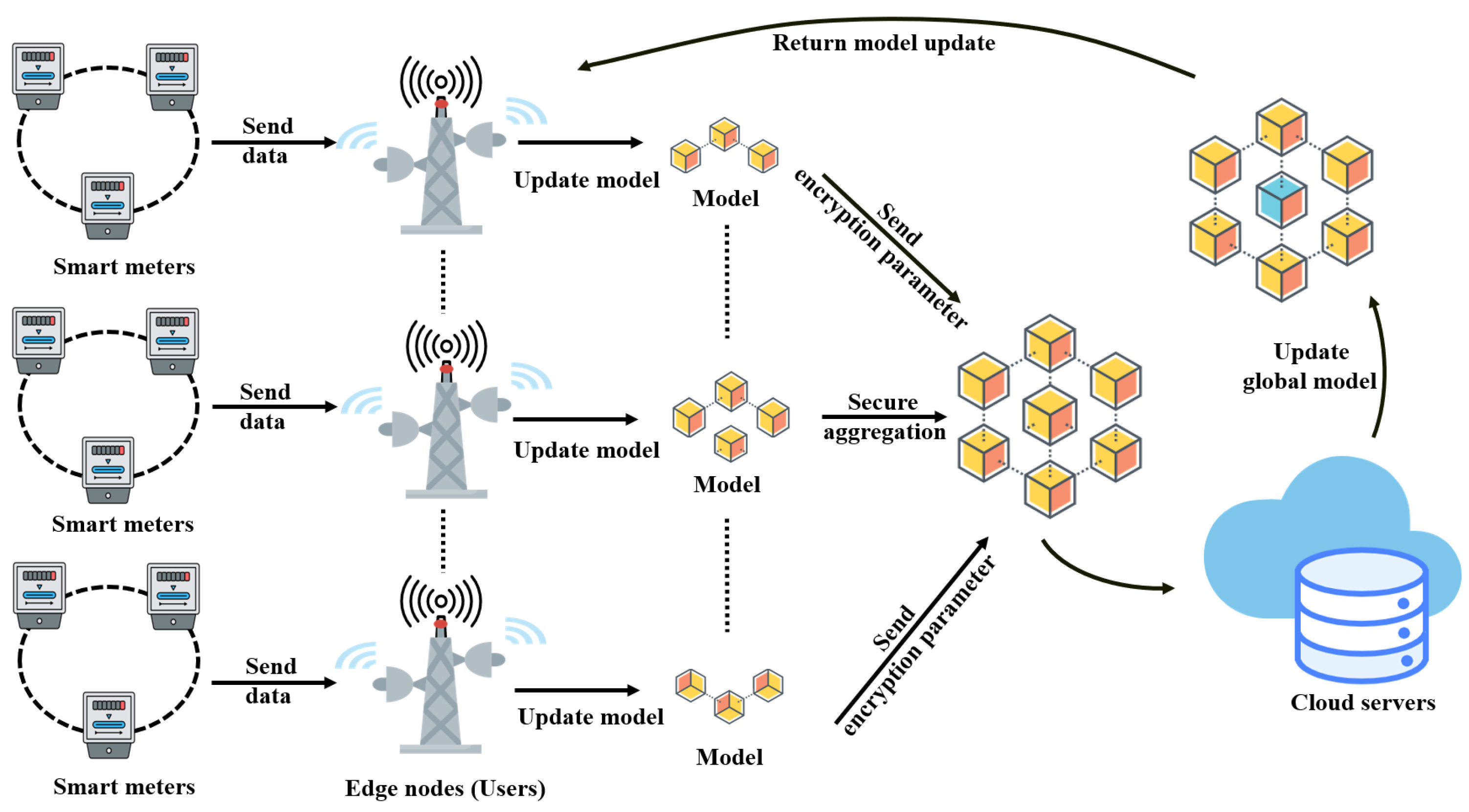
The initial phase of the scenario is shown in
Figure 2.
Figure 3 shows the interaction diagram between the edge node and the cloud server after the initialization of the scheme. The system is structured around six interaction rounds, designed to accomplish the aforementioned objectives. Initially, the system initiates and generates all the necessary keys for both users and
. Subsequently, each user
encrypts their gradient
and transmits it to the
. Upon receiving an adequate number of messages from all active users,
aggregates the gradients from each user and returns the computed results, along with a corresponding Proof, to each user. Finally, each user verifies the Proof to determine whether to accept or reject the computed result. The process then loops back to Round 0 to commence a new iteration.
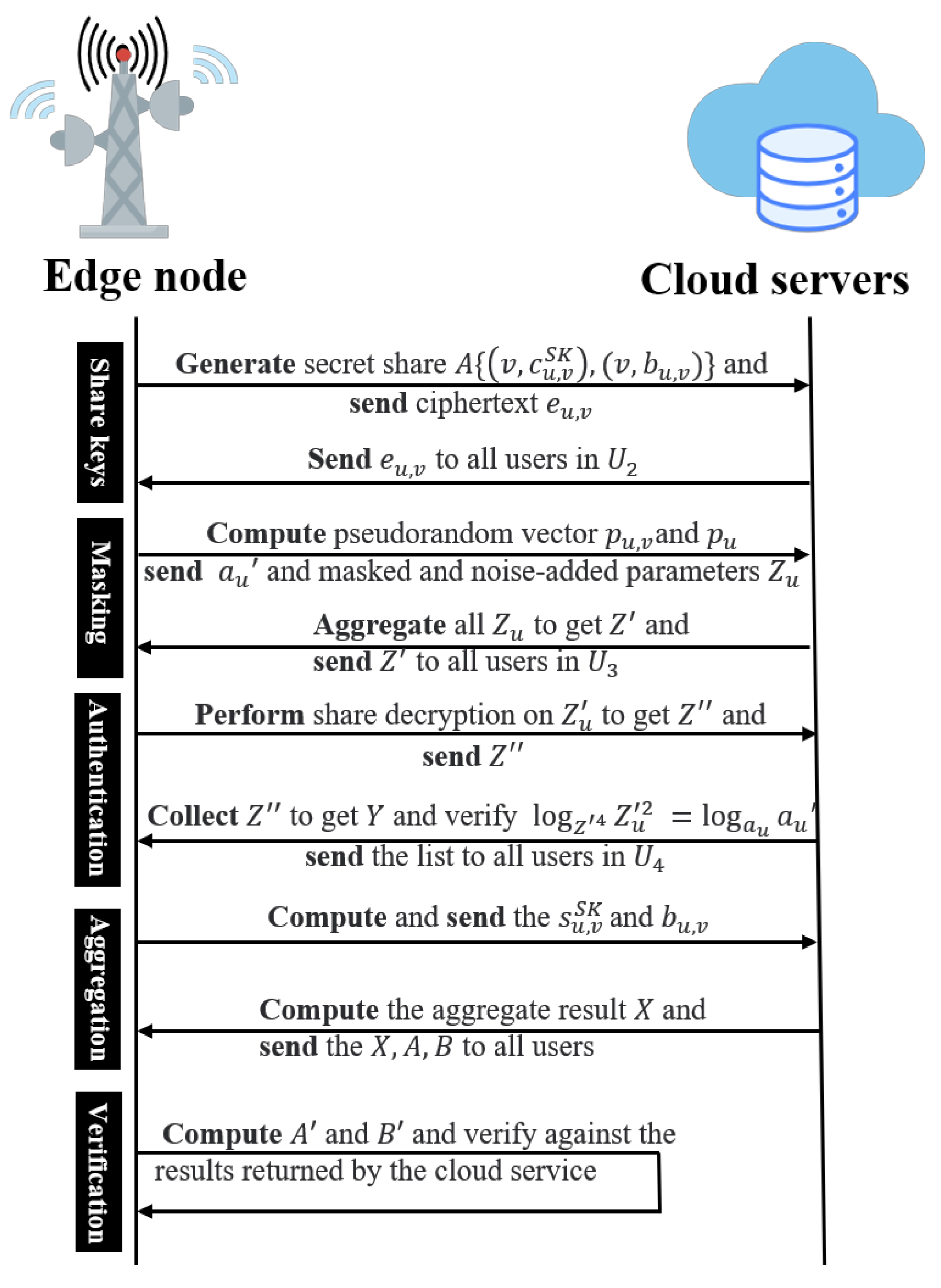
Figure 4 shows the specific process of interaction between edge nodes and cloud servers.
6.1. Share Decryption and Share Combining
In order to safeguard the confidentiality of the local data throughout the learning process, we employed a threshold homomorphic encryption technique to encrypt the model parameters of each user
u. Additionally, to mitigate the risk of information leakage pertaining to intermediate learning results and the final model, Gaussian noise is incorporated into the encryption process of the model parameters
. Furthermore, to establish the authenticity of user identities, a Fiat–Shamir zero-knowledge proof [
38] is constructed, enabling the server to authenticate the user’s identity.
During Round 2, each user utilizes their individual public key
to encrypt the previously noise-added data
, resulting in
where
represents the privacy guarantee, and
refers to the number of non-colluding parties.
Based on the Paillier cryptosystem, each user is required to compute the following expression:
where
, and
denotes a randomly chosen number.
In Round 3, users are selected by the server to perform decryption sharing on , which is the service aggregate.
Each user initially computes
and transmits it to the server. Upon receiving these values, the server computes the aggregated encrypted value
as
. In other words,
is equal to
, where
.
Subsequently, each user computes
based on the received
and forwards it to the server. Upon receiving these data, the server verifies the correctness as follows:
If the server possesses a sufficient number of shares and valid
proof, it can merge them to obtain the final result by selecting a subset
S of
shares, combining them as follows:
where
.
The value of M can be expressed as . It should be noted that . Therefore, the server can deduce that . Considering that , we have . The server can calculate .
6.2. Verification
In Round 5, each user receives
and verifies its correctness through proofing:
6.3. Reducing Noise with SMC
The SMC framework is harnessed to efficiently address the noise introduced by differential privacy (DP). Let denote the noise parameters in the federated learning (FL) algorithm, while represents the sensitivity of the allocated budget. Within this framework, the noise is effectively reduced by a factor of , leading to enhanced data privacy and accuracy.
Since , the noise present in the aggregated value satisfies the requirements of DP strictly. Additionally, as the SMC framework involves a maximum of colluders, it is not possible to decrypt the private data of other users. To summarize, the SMC framework effectively reduces the noise introduced by DP, thereby ensuring the security of the FL system.
7. Security Analysis
7.1. Correctness Verification
In Round 5, each remaining user receives the final values of
sent by the server. The user verifies the correctness of
by applying the l-BDHI assumption [
35]. If
is verified correctly, the user can deduce
A and
L and further verify that
,
based on the DDH assumption [
39]. By performing these verifications, the user can confirm that the server has computed the correct values of
B and
Q. This implies that the result
X returned by the server is accurate.
The proof process can be performed easily using l-BDHI [
35] and DDH [
39]. The specific steps of the proof process are not included here.
7.2. Threshold Homomorphic Encryption
During Round 2 and Round 3, each user transmits to the server, and the server calculates . Subsequently, the server conducts the zero-knowledge proof to authenticate that =. As every user shares the exclusive public value with the server in the setup phase, this assures the server that the user’s identity has not been counterfeited by an adversary.
The non-interactive zero-knowledge proof described above employs the Fiat–Shamir heuristic, which can be readily derived from the relevant publication [
38].
7.3. Honest but Curious Security
In this section, the technical principles used in this system for security purposes will be described. Before the user transmits the parameters, we use PRG to add pairs of random vectors to the data, which hide the specific information entered by the user, so that the final result obtained by the server is always uniformly random to the result obtained without adding the random vectors.
Within our system, the transfer of user data occurs in an environment where all participants are honest but curious. During this process, the users collaboratively engage in computational logic while preserving the utmost confidentiality of their private data. Each participant gains access solely to the computation results, completely oblivious to the data of other participants or the intermediate outcomes of the computation process. This ensures a high level of privacy and security for all involved parties, including both the participants and the server. The system effectively shields the sensitive data from being disclosed, fostering trust and confidentiality among the users, while allowing them to collectively obtain the required results without any compromise on their privacy.
We assume that the server S interacts with a group of n users, denoted as , and the threshold is set to t. Users have the freedom to exit at any point during their interaction with the server. Let represent the set of users who have sent data to the server in Round or, in other words, the users who have not exited by Round . Therefore, we have . refers to the users who sent data to the server in Round 1 but did not send data within the time limit of Round 2. For any arbitrary subset C, is a random variable representing a collective perspective of the parties in C during the execution of the system. In the following, two theorems applied in this system will be given. In a user honest-but-curious environment, the joint view with fewer than t users can only infer its own data. In the server’s honest-but-curious environment, the server and the joint view with fewer than t users can only infer the sum of its own data and the other users’ data.
Theorem 1. k, t, , , , , , , , C with , , , . SIM Proof of Theorem 1. The collective perspective of users in C relies only on their own inputs, so it is possible to run their inputs through the simulator and obtain a simulated perspective of users in C that is consistent with REAL. The server’s response in Round 2 solely consists of a list of user identities without disclosing specific values of . As a result, the simulator can execute the inputs of users in C and utilize hypothetical values to represent the inputs of all honest participants not in C. This ensures that the collective perspective of users in C in the simulation remains consistent with REAL. □
By combining the insights from the previous hybrid and the arguments presented above, we are able to define a PPT simulator, denoted as . The purpose of this simulator is to mimic the behavior of the system and produce outputs that are computationally indistinguishable from the outputs of the real system, denoted as .
8. Evaluation
We conducted an assessment of the honest-but-curious version of our system and provided a comprehensive overview of its performance in various aspects. Our scheme offers user validation of aggregated results, ensuring the privacy of users’ sensitive data throughout and after the execution process. Additionally, users have the flexibility to exit the system while ensuring the integrity and accuracy of the final outcome at any stage of the system’s operation. Through our evaluation, we aimed to demonstrate the effectiveness and reliability of our system, highlighting its capabilities in maintaining data security, supporting user validation, and accommodating user exits while preserving result correctness.
Considering that the accuracy of the model in federated learning (FL) depends on two crucial factors—the number of participating users during training and the magnitude of the local gradient held by each user—we conducted our experiments with careful attention to detail. We meticulously recorded the user count and gradient size in each experiment, aiming to thoroughly examine the correlation between these variables, the model’s accuracy, and the system’s overhead.
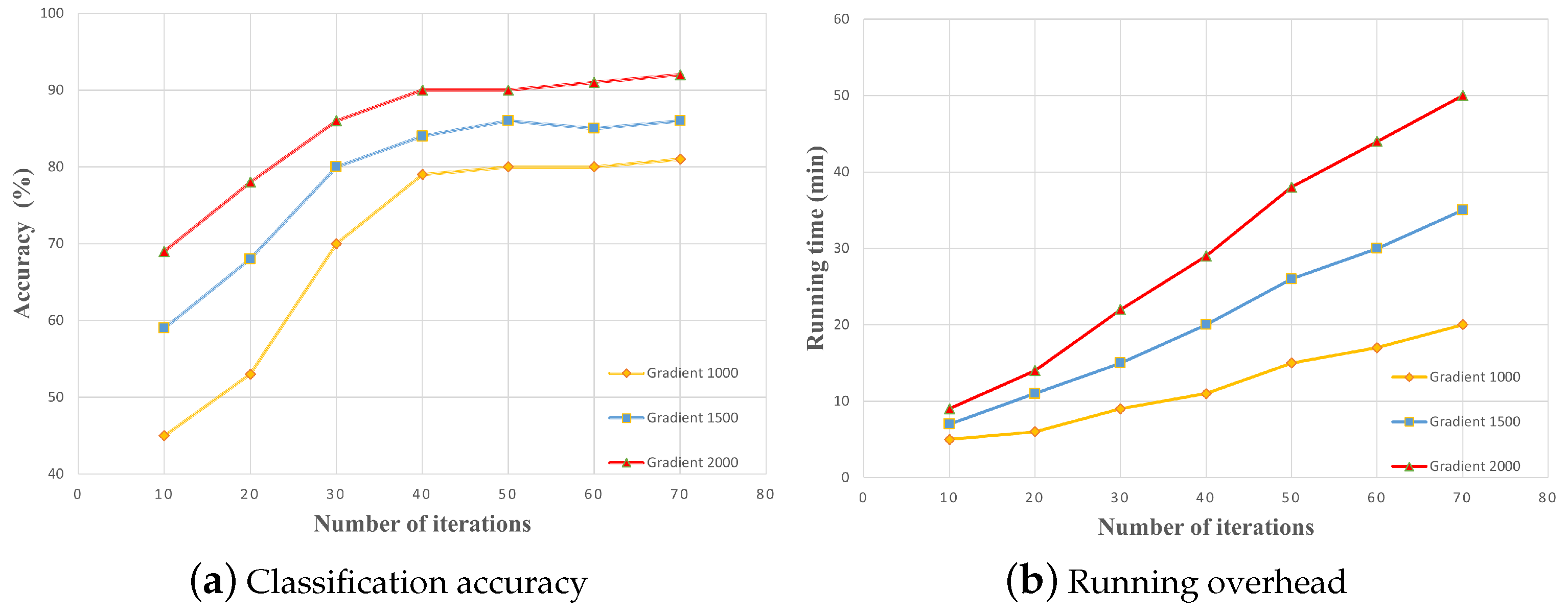
Figure 5 presents the classification accuracy and execution time in relation to various gradients in our experimental trials. The system’s computation overhead and accuracy exhibit variations contingent upon the number of users and the magnitude of the gradient. As illustrated in
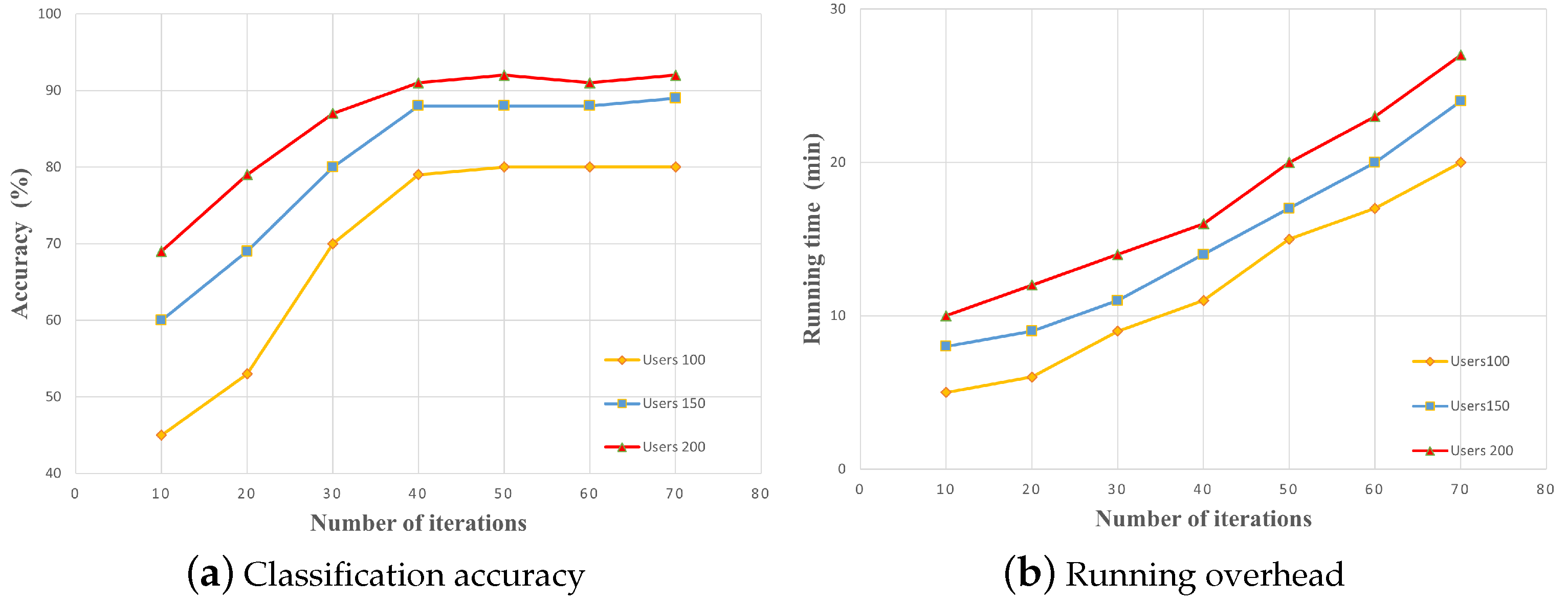
Figure 5a, an augmentation in the number of local gradients possessed by users corresponds to an elevated accuracy in the model’s outcome. However, it also results in greater computation overhead per round. Once the number of gradients surpasses a certain threshold, the model’s accuracy tends to stabilize. Likewise,
Figure 6 demonstrates that solely considering changes in the number of users, an elevation in user count enhances the computation overhead while improving the model’s accuracy. An increase in both the number of users and gradients unavoidably amplifies the computation overhead. Consequently, it is advisable to select an appropriate number of users and gradients, taking into account the computational overhead, rather than simply striving for more.
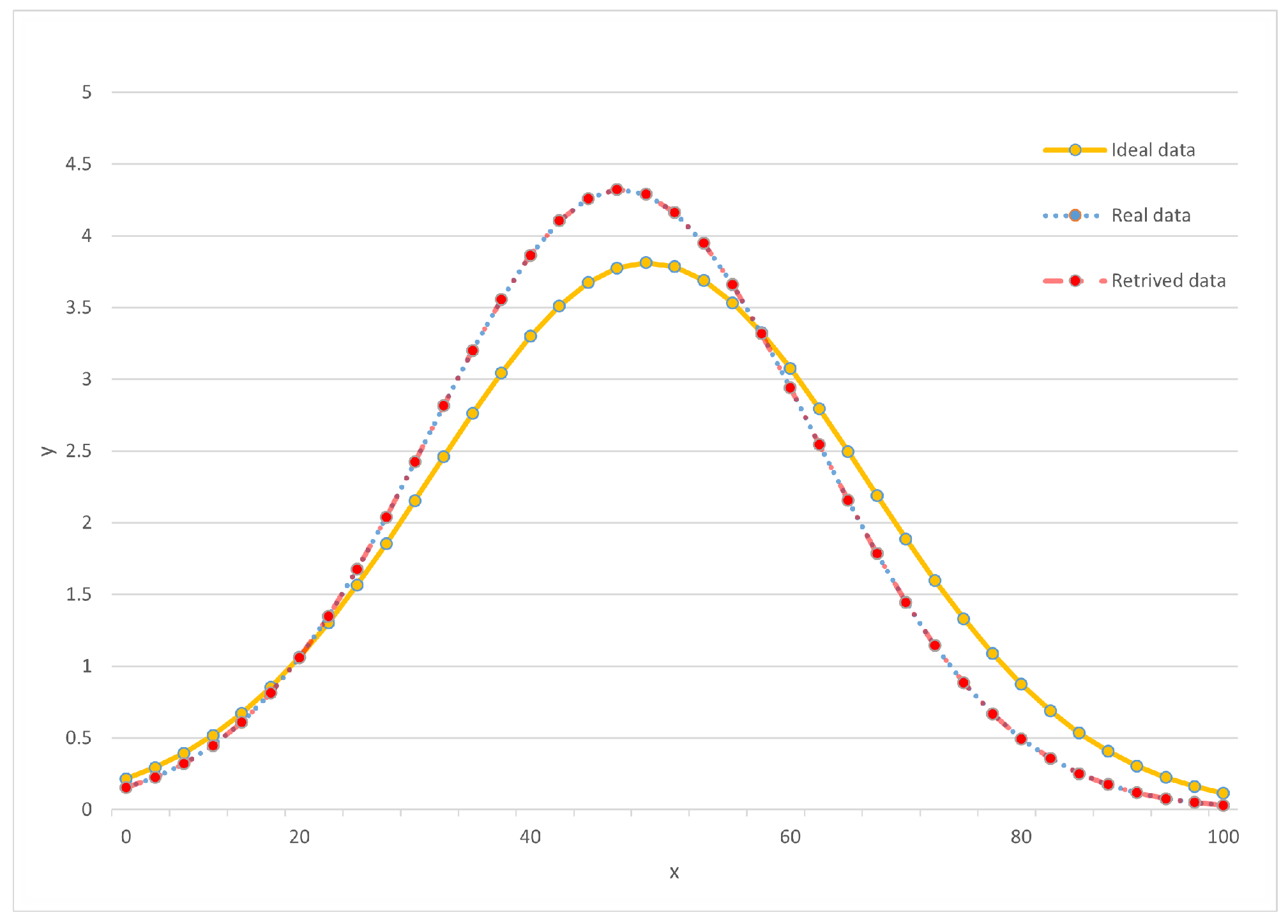
Figure 7 depicts the experimental evaluation of the accuracy of results obtained from the user verification server. During the verification stage, each user is tasked with validating the aggregated results received from the server and making a decision to either accept or reject them before updating their local model. Our analysis involves a diverse set of users, and we compare their verified server aggregation results with the ground truth. As illustrated in the figure, the validated data precisely align with the actual data, underscoring the confidence in the accuracy of the aggregated results generated by the server after undergoing the rigorous validation process. This validates the effectiveness of our approach, as the verification stage ensures the reliability of the server’s aggregated outcomes and confirms that they remain consistent with the ground truth.
Figure 8 and
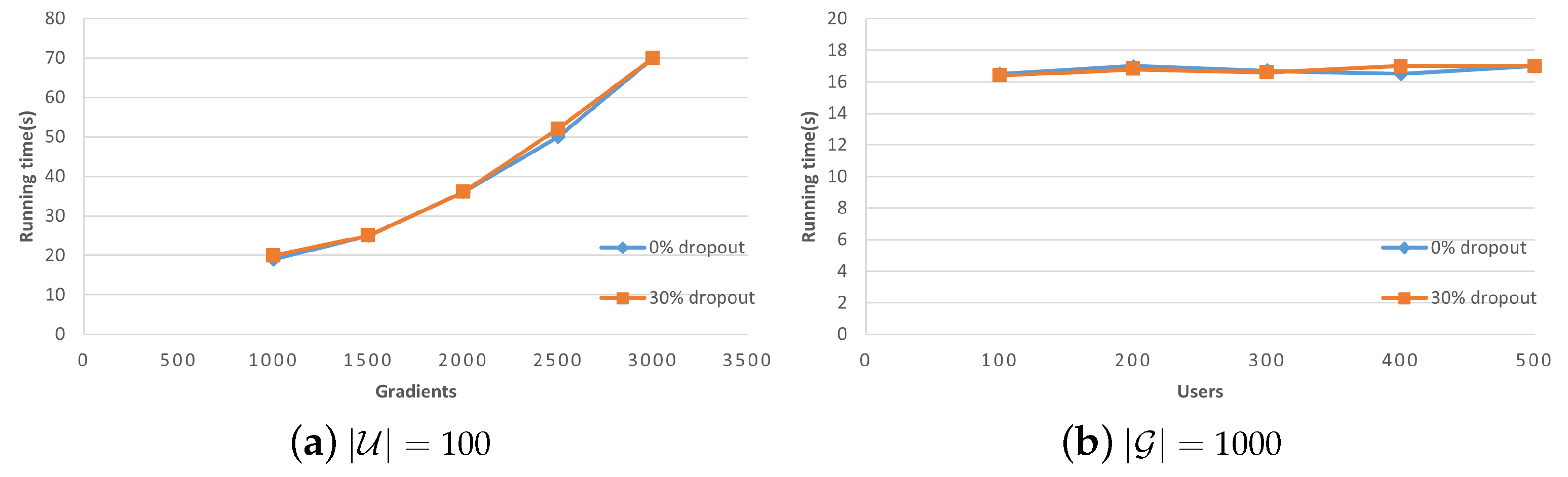
Figure 9 provide insight into the computation and communication overhead incurred by users during the execution of the system, measured in terms of runtime and data volume. As depicted in
Figure 8, it is apparent that the computation overhead escalates as the number of local gradients possessed by users increases. Nevertheless, if only the number of users increases without any change in the local gradients, the computation overhead remains constant. These overheads primarily relate to the number of user gradients, meaning that an increase in the number of user gradients leads to an overall rise in the total overhead.
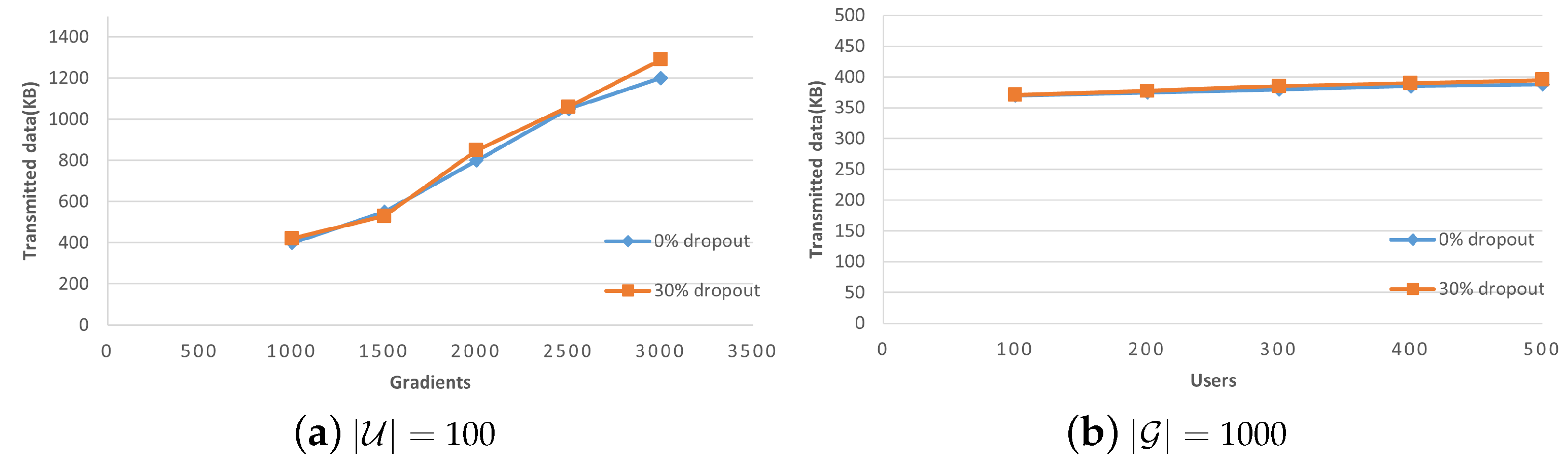
Figure 9 demonstrates that the communication overhead of users follows a similar pattern as the computation overhead. Regardless of any variations in the number of users, the transmitted data volume demonstrates a linear increase as the number of user gradients rises. Additionally,
Table 1 reveals that the communication overhead of users within the system primarily stems from the masking and verification stages, where
refers to the number of clients,
means dropout,
stands for share keys,
denotes masking,
marks user authentication,
represents secure aggregation, and
denotes correctness verification.
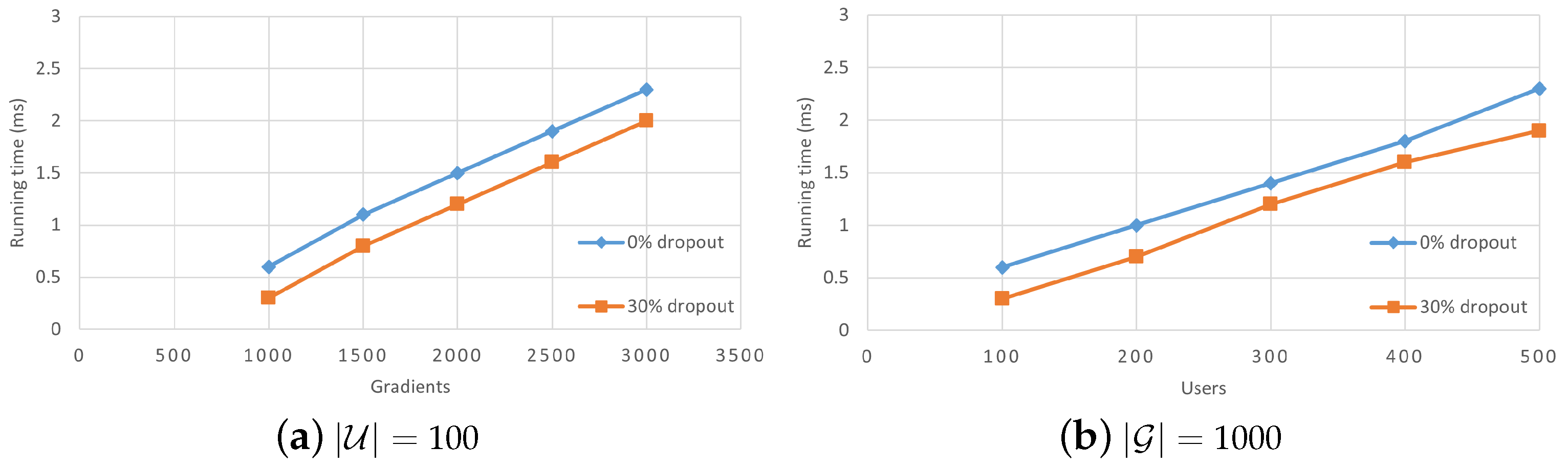
Figure 10 presents a visualization of the computation overhead experienced by the server throughout the system’s execution. Contrary to the variation pattern observed in the computation overhead of users, the server exhibits a linear correlation with both the number of local gradients held by users and the number of users. As the number of gradients or users increases, the server’s computation overhead rises correspondingly. Furthermore,
Table 1 reveals that the server’s computation overhead is greatly influenced by the number of users who withdraw from the system. Overall, the primary sources of overhead for the
during system execution are the aggregation of gradients transmitted by users and the removal of masks.
The algorithm proposed in this paper and its comparison with existing federated learning algorithms in terms of functionality are shown in
Table 2. The comparison indicators include transmission process protection (TPP), intermediate results protection (IRP), support for exit (SE), identity recognition (IR), and results verification (RV). In the table, the presence of “Y” indicates the availability of the feature in the corresponding scheme, while “N” denotes its absence. All algorithms in this table achieve transmission process protection in federated learning. Bonawitz et al.’s algorithm, for the first time in the federated learning framework, introduces a privacy-preserving approach by adding random vectors to transmitted data to protect data privacy and using digital signature technology for identity identification. Truex et al.’s algorithm uses homomorphic encryption to protect the aggregation intermediate results in the federated learning environment and achieves identity verification through zero-knowledge proof algorithms. Xu et al.’s algorithm provides authentication for the correctness of aggregation results while protecting transmitted data and implementing identity identification using hash functions. Cao et al.’s algorithm combines federated learning with differential privacy, making it difficult for attackers to infer the original data, thus protecting the intermediate results of federated learning. This table shows that our proposed algorithm successfully achieves the aforementioned functionalities, affirming the efficacy of our approach.
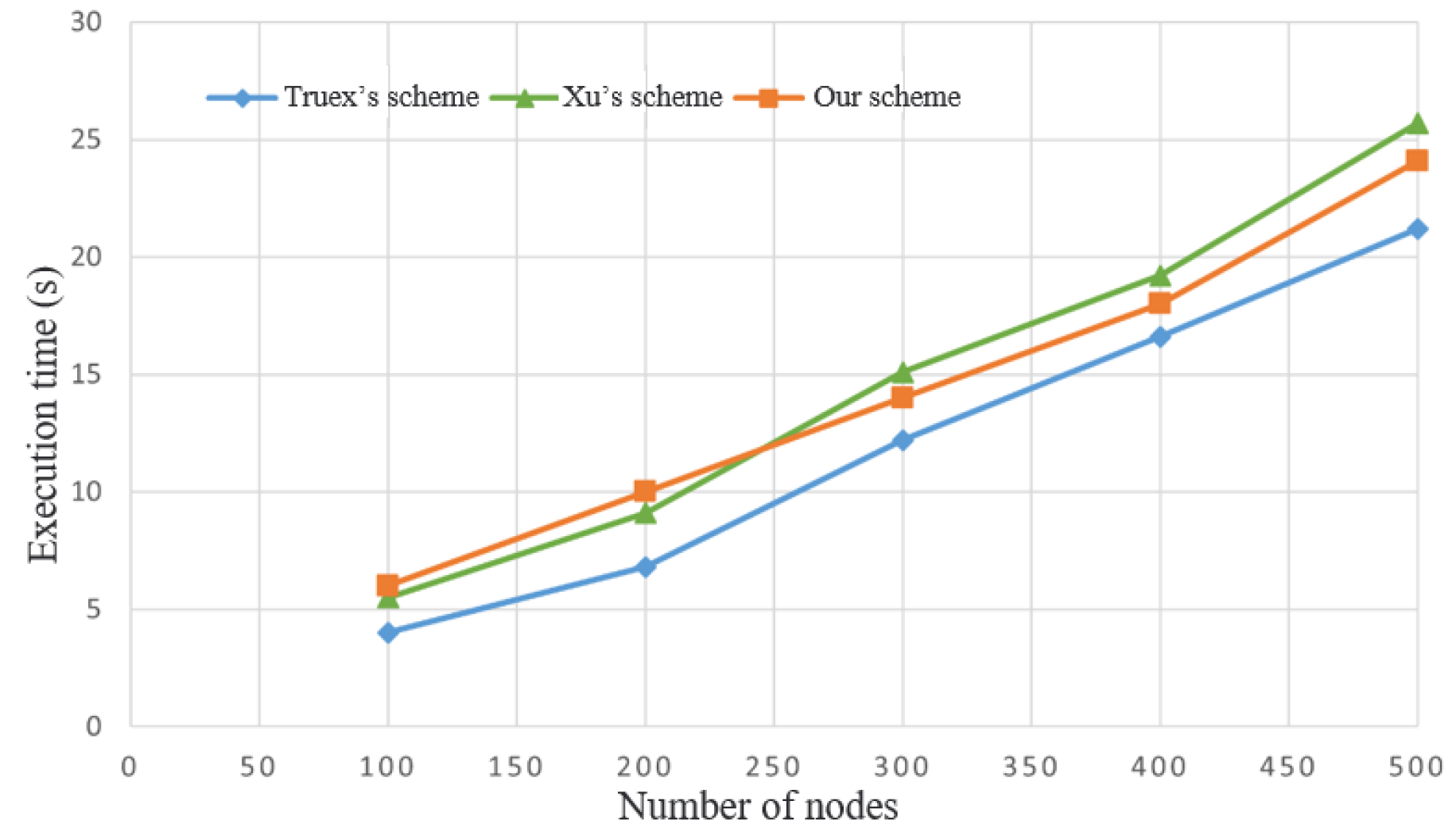
Figure 11 presents a comparison between the proposed approach and the federated learning algorithm in terms of time consumption. In the comparative experiment, the federated learning environment was uniformly configured with the possibility of the mid-way node dropout. In our proposed approach, additional phases were introduced compared to the algorithms presented by Truex and Xu et al. These extra phases include support for mid-way node dropout, validation result correctness, and protection of intermediate results. Notably, the validation phase requires higher time consumption. Consequently, from the graph, it can be observed that our proposed approach, which includes the validation phase, takes longer execution time compared to Truex et al.’s approach, which lacks a correctness validation phase, regardless of the number of nodes. Regarding Xu et al.’s approach, which also incorporates a validation phase, our proposed approach exhibits similar time consumption when the number of nodes is relatively small. However, as the number of nodes increases, our proposed approach maintains a shorter execution time compared to Xu et al.’s approach.
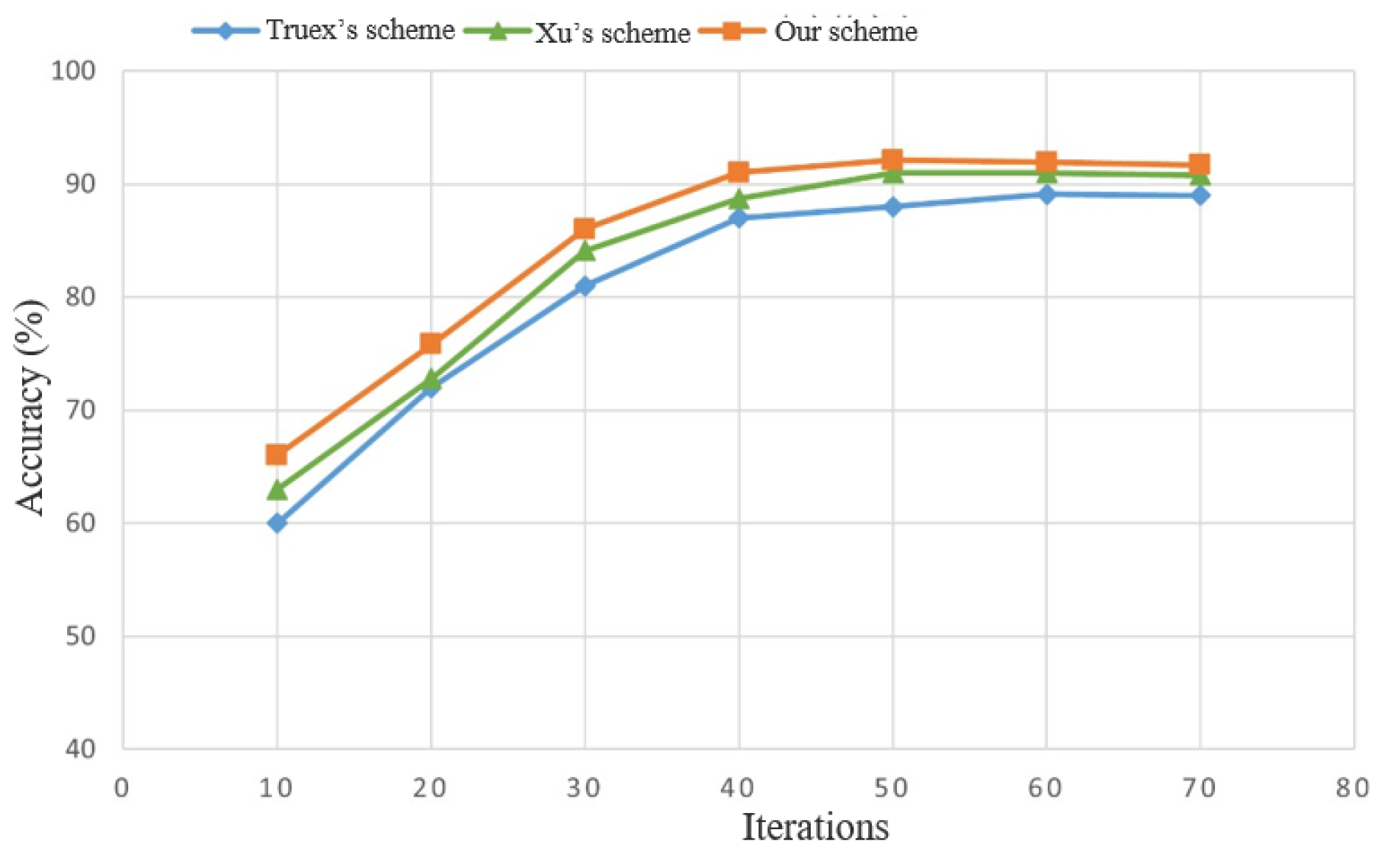
Figure 12 is configured with the possibility of mid-way node dropout, and the number of nodes is fixed at 200. From the graph, it is evident that the federated learning algorithm executed in our proposed approach consistently maintains higher model accuracy across various iterations compared to the other two schemes.
Through the above experimental analysis, it can be seen that the proposed method can provide more accurate data aggregation and, thus, obtain better overall model performance.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}