

Thermophilic Nucleic Acid Polymerases and Their Application in Xenobiology
 , ,
, ,
Abstract
:1. Introduction
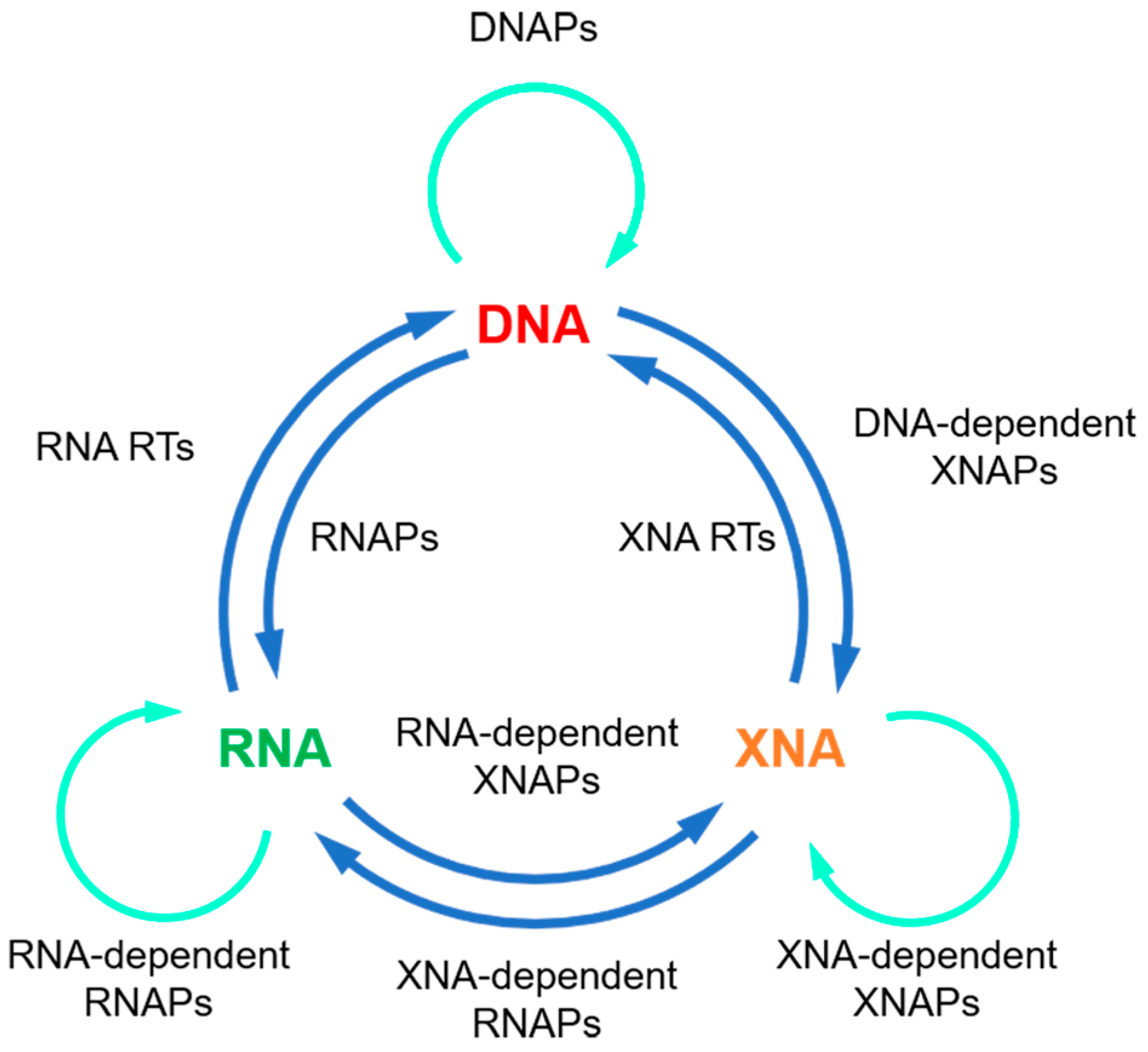
2. Thermophilic and Hyperthermophilic Nucleic Acid Polymerases
3. Strategies for Engineering Thermophilic Nucleic Acid Polymerases
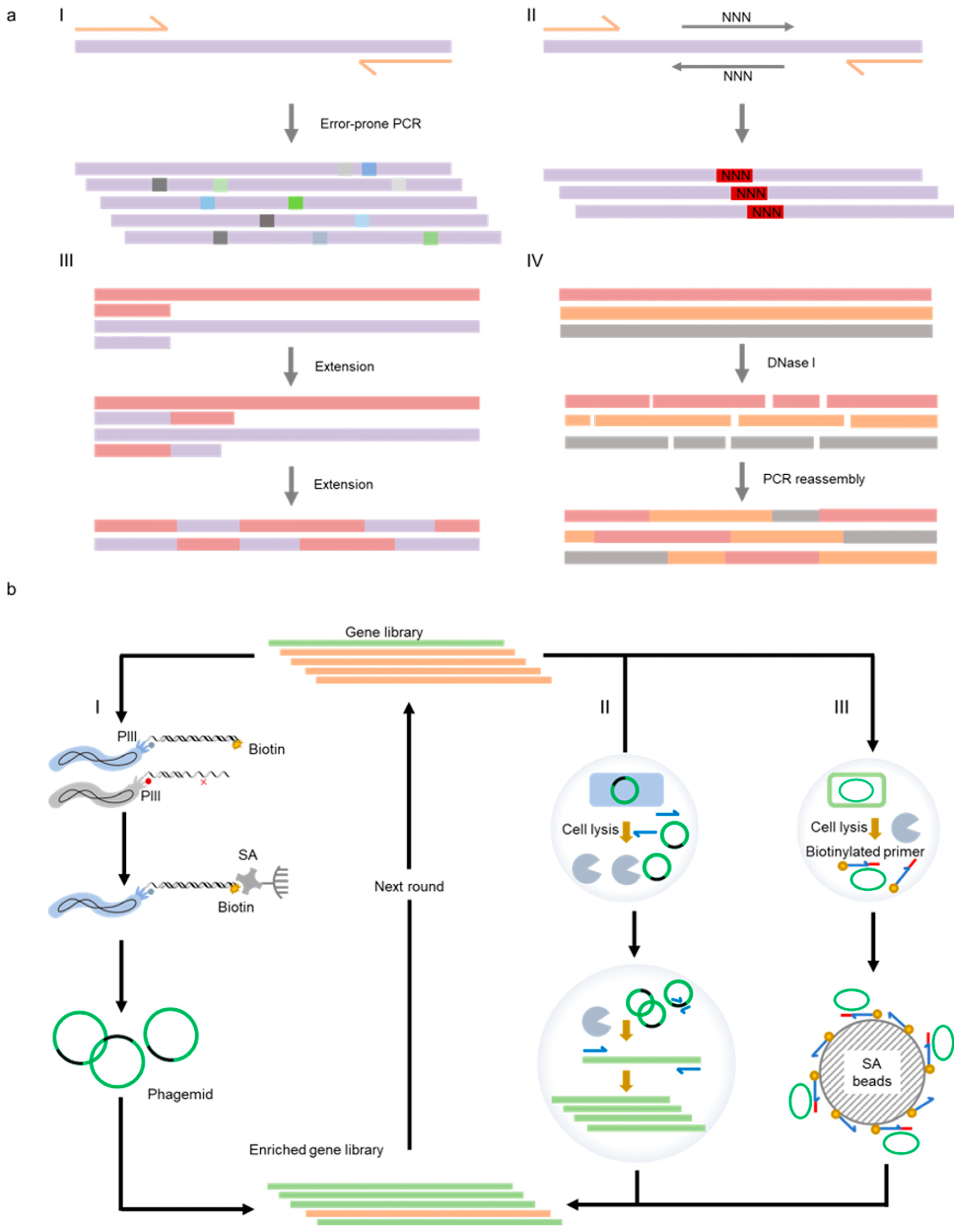
3.1. Strategies for Mutant Generation or Library Construction
3.2. Strategies for the Selection or Screening of Polymerase Libraries
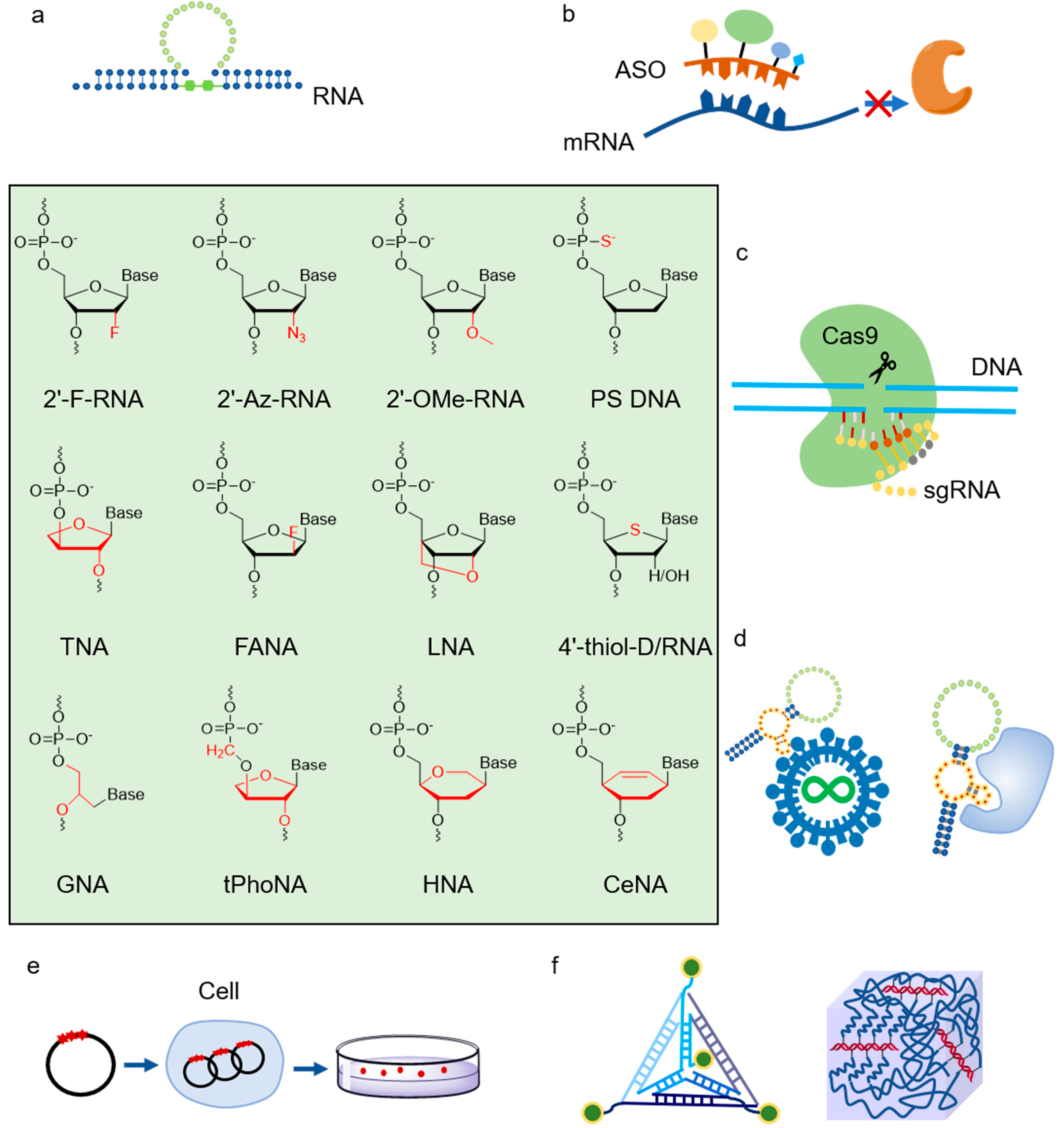
4. Thermophilic XNAPs
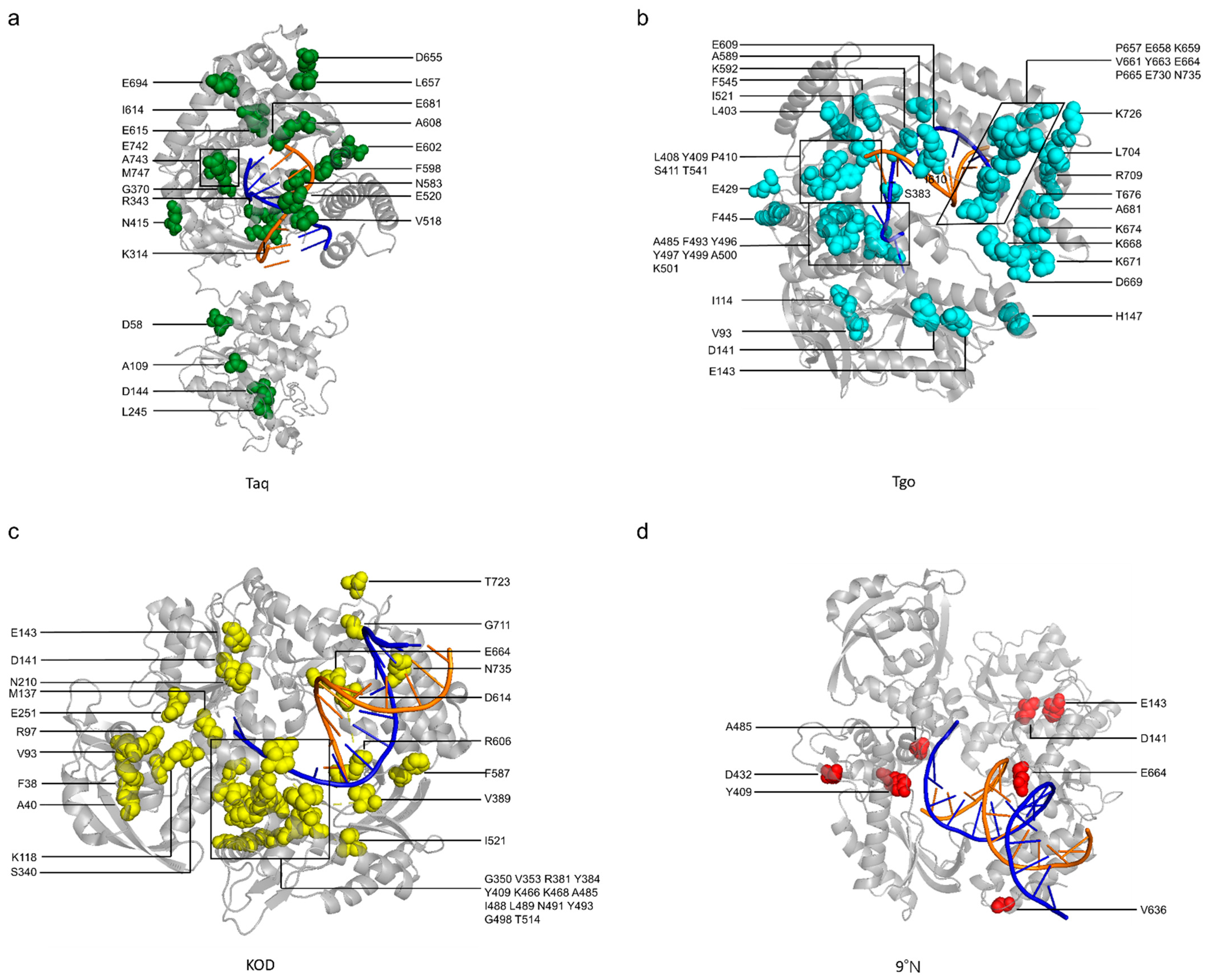
5. Key Mutations in Engineered XNAPs
6. Application of XNAs and Thermophilic XNAPs
7. Conclusions and Perspective
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Aschenbrenner, J.; Marx, A. DNA Polymerases and Biotechnological Applications. Curr. Opin. Biotechol. 2017, 48, 187–195. [Google Scholar] [CrossRef]
- Borkotoky, S.; Murali, A. The Highly Efficient T7 RNA Polymerase: A Wonder Macromolecule in Biological Realm. Int. J. Biol. Macromol. 2018, 118, 49–56. [Google Scholar] [CrossRef] [PubMed]
- Martin-Alonso, S.; Frutos-Beltran, E.; Menendez-Arias, L. Reverse Transcriptase: From Transcriptomics to Genome Editing. Trends Biotechnol. 2021, 39, 194–210. [Google Scholar] [CrossRef]
- Venkataraman, S.; Prasad, B.V.L.S.; Selvarajan, R. RNA Dependent RNA Polymerases: Insights from Structure, Function and Evolution. Viruses 2018, 10, 76. [Google Scholar] [CrossRef] [Green Version]
- Laos, R.; Thomson, J.M.; Benner, S.A. DNA Polymerases Engineered by Directed Evolution to Incorporate Non-Standard Nucleotides. Front. Microbiol. 2014, 5, 565. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.L.; Zhang, H.Q.; Xu, Y.; Lassakova, S.; Korabecna, M.; Neuzil, P. PCR Past, Present and Future. Biotechniques 2020, 69, 317–325. [Google Scholar] [CrossRef]
- Roberts, M.A.J. Recombinant DNA Technology and DNA Sequencing. Essays Biochem. 2019, 63, 457–468. [Google Scholar] [CrossRef]
- Shendure, J.; Balasubramanian, S.; Church, G.M.; Gilbert, W.; Rogers, J.; Schloss, J.A.; Waterston, R.H. DNA Sequencing at 40: Past, Present and Future. Nature 2017, 550, 345–353. [Google Scholar] [CrossRef] [PubMed]
- Meiser, L.C.; Nguyen, B.H.; Chen, Y.J.; Nivala, J.; Strauss, K.; Ceze, L.; Grass, R.N. Synthetic DNA Applications in Information Technology. Nat. Commun. 2022, 13, 352. [Google Scholar] [CrossRef]
- Terpe, K. Overview of Thermostable DNA Polymerases for Classical PCR Applications: From Molecular and Biochemical Fundamentals to Commercial Systems. Appl. Microbiol. Biotechnol. 2013, 97, 10243–10254. [Google Scholar] [CrossRef]
- Ishino, S.; Ishino, Y. DNA Polymerases as Useful Reagents for Biotechnology—The History of Developmental Research in the Field. Front. Microbiol. 2014, 5, 465. [Google Scholar] [CrossRef] [Green Version]
- Kim, K.P.; Cho, S.S.; Lee, K.K.; Youn, M.H.; Kwon, S.T. Improved Thermostability and PCR Efficiency of Thermococcus celericrescens DNA Polymerase via Site-Directed Mutagenesis. J. Biotechnol. 2011, 155, 156–163. [Google Scholar] [CrossRef] [PubMed]
- Budisa, N.; Kubyshkin, V.; Schmidt, M. Xenobiology: A Journey towards Parallel Life Forms. ChemBioChem 2020, 21, 2228–2231. [Google Scholar] [CrossRef]
- Kubyshkin, V.; Budisa, N. Synthetic Alienation of Microbial Organisms by Using Genetic Code Engineering: Why and How? Biotechnol. J. 2017, 12, 1600097. [Google Scholar] [CrossRef]
- Schmidt, M. Xenobiology: A New Form of Life as the Ultimate Biosafety Tool. Bioessays 2010, 32, 322–331. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Thirunavukarasu, D.; Chen, T.; Liu, Z.X.; Hongdilokkul, N.; Romesberg, F.E. Selection of 2′-Fluoro-Modified Aptamers with Optimized Properties. J. Am. Chem. Soc. 2017, 139, 2892–2895. [Google Scholar] [CrossRef] [PubMed]
- Chen, T.; Romesberg, F.E. Directed Polymerase Evolution. FEBS Lett. 2014, 588, 219–229. [Google Scholar] [CrossRef] [Green Version]
- Zhu, G.; Song, P.; Wu, J.; Luo, M.; Chen, Z.; Chen, T. Application of Nucleic Acid Frameworks in the Construction of Nanostructures and Cascade Biocatalysts: Recent Progress and Perspective. Front. Bioeng. Biotechol. 2022, 9, 792489. [Google Scholar] [CrossRef]
- Sun, L.; Ma, X.; Zhang, B.; Qin, Y.; Ma, J.; Du, Y.; Chen, T. From Polymerase Engineering to Semi-Synthetic Life: Artificial Expansion of the Central Dogma. RSC Chem. Biol. 2022, 3, 1173–1197. [Google Scholar] [CrossRef]
- Hervey, J.R.D.; Freund, N.; Houlihan, G.; Dhaliwal, G.; Holliger, P.; Taylor, A.I. Efficient Synthesis and Replication of Diverse Sequence Libraries Composed of Biostable Nucleic Acid Analogues. RSC Chem. Biol. 2022, 10, 1209–1215. [Google Scholar] [CrossRef]
- Chen, T.; Romesberg, F.E. Polymerase Chain Transcription: Exponential Synthesis of RNA and Modified RNA. J. Am. Chem. Soc. 2017, 139, 9949–9954. [Google Scholar] [CrossRef]
- Taylor, A.I.; Holliger, P. Directed Evolution of Artificial Enzymes (XNAzymes) from Diverse Repertoires of Synthetic Genetic Polymers. Nat. Protoc. 2015, 10, 1625–1642. [Google Scholar] [CrossRef] [PubMed]
- Yang, K.F.; McCloskey, C.M.; Chaput, J.C. Reading and Writing Digital Information in TNA. Acs Synth. Biol. 2020, 9, 2936–2942. [Google Scholar] [CrossRef] [PubMed]
- Date, T.; Suzuki, K.; Imahori, K. Purification and Some Properties of DNA-Dependent RNA Polymerase from an Extreme Thermophile, Thermus thermophilus HB8. J. Biochem. 1975, 78, 845–858. [Google Scholar] [CrossRef] [PubMed]
- Eckert, K.A.; Kunkel, T.A. High Fidelity DNA Synthesis by the Thermus aquaticus DNA Polymerase. Nucleic Acids Res. 1990, 18, 3739–3744. [Google Scholar] [CrossRef] [Green Version]
- Lawyer, F.C.; Stoffel, S.; Saiki, R.K.; Chang, S.Y.; Landre, P.A.; Abramson, R.D.; Gelfand, D.H. High-Level Expression, Purification, and Enzymatic Characterization of Full-Length Thermus aquaticus DNA Polymerase and a Truncated form Deficient in 5′ to 3′ Exonuclease Activity. PCR Methods Appl. 1993, 2, 275–287. [Google Scholar] [CrossRef] [Green Version]
- Choi, J.J.; Jung, S.E.; Kim, H.K.; Kwon, S.T. Purification and Properties of Thermus filiformis DNA Polymerase Expressed in Escherichia coli. Biotechnol. Appl. Biochem. 1999, 30, 19–25. [Google Scholar]
- Dabrowski, S.; Kur, J. Recombinant His-Tagged DNA Polymerase. I. Cloning, Purification and Partial Characterization of Thermus thermophilus Recombinant DNA Polymerase. Acta Biochim. Pol. 1998, 45, 653–660. [Google Scholar] [CrossRef] [Green Version]
- Harrell, R.A.; Hart, R.P. Rapid Preparation of Thermus flavus DNA Polymerase. PCR Methods Appl. 1994, 3, 372–375. [Google Scholar] [CrossRef]
- Park, J.H.; Kim, J.S.; Kwon, S.T.; Lee, D.S. Purification and Characterization of Thermus caldophilus GK24 DNA Polymerase. Eur. J. Biochem. 1993, 214, 135–140. [Google Scholar] [CrossRef]
- Saghatelyan, A.; Panosyan, H.; Trchounian, A.; Birkeland, N.K. Characteristics of DNA Polymerase I from an Extreme Thermophile, Thermus scotoductus Strain K1. MicrobiologyOpen 2021, 10, e1149. [Google Scholar] [CrossRef] [PubMed]
- Ignatov, K.B.; Barsova, E.V.; Fradkov, A.F.; Blagodatskikh, K.A.; Kramarova, T.V.; Kramarov, V.M. A Strong Strand Displacement Activity of Thermostable DNA Polymerase Markedly Improves the Results of DNA Amplification. Biotechniques 2014, 57, 81–87. [Google Scholar] [CrossRef] [PubMed]
- Uemori, T.; Ishino, Y.; Fujita, K.; Asada, K.; Kato, I. Cloning of the DNA Polymerase Gene of Bacillus caldotenax and Characterization of the Gene Product. J. Biochem. 1993, 113, 401–410. [Google Scholar] [CrossRef]
- Sellmann, E.; Schröder, K.L.; Knoblich, I.M.; Westermann, P. Purification and Characterization of DNA Polymerases from Bacillus Species. J. Bacteriol. 1992, 174, 4350–4355. [Google Scholar] [CrossRef] [Green Version]
- Andrianova, M.; Komarova, N.; Grudtsov, V.; Kuznetsov, E.; Kuznetsov, A. Amplified Detection of the Aptamer-Vanillin Complex with the Use of Bsm DNA Polymerase. Sensors 2018, 18, 49. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Oscorbin, I.P.; Boyarskikh, U.A.; Filipenko, M.L. Large Fragment of DNA Polymerase I from Geobacillus sp 777: Cloning and Comparison with DNA Polymerases I in Practical Applications. Mol. Biotechnol. 2015, 57, 947–959. [Google Scholar] [CrossRef]
- Gelfand, D.H.; Lawyer, F.C. DNA Encoding a Thermostable Nucleic Acid Polymerase Enzyme from Thermotoga maritima. U.S. Patent No. 5,374,553, 20 December 1994. [Google Scholar]
- Slater, M.R.; Huang, F.; Hartnett, J.R.; Bolchakova, E.; Storts, D.R.; Otto, P.; Miller, K.M.; Novikov, A.; Velikodvorskaya, G.A. Thermophilic DNA Polymerases from Thermotoga neapolitana. U.S. Patent No. 6,077,664, 20 June 2000. [Google Scholar]
- Yang, S.W.; Astatke, M.; Potter, J.; Chatterjee, D.K. Mutant Thermotoga neapolitana DNA Polymerase I: Altered Catalytic Properties for Non-Templated Nucleotide Addition and Incorporation of Correct Nucleotides. Nucleic Acids Res. 2002, 30, 4314–4320. [Google Scholar] [CrossRef] [Green Version]
- Chang, J.R.; Choi, J.J.; Kim, H.K.; Kwon, S.T. Purification and Properties of Aquifex aeolicus DNA Polymerase Expressed in Escherichia coli. FEMS Microbiol. Lett. 2001, 201, 73–77. [Google Scholar] [CrossRef]
- Mattila, P.; Korpela, J.; Tenkanen, T.; Pitkänen, K. Fidelity of DNA Synthesis by the Thermococcus litoralis DNA Polymerase—An Extremely Heat Stable Enzyme with Proofreading Activity. Nucleic Acids Res. 1991, 19, 4967–4973. [Google Scholar] [CrossRef]
- Takagi, M.; Nishioka, M.; Kakihara, H.; Kitabayashi, M.; Inoue, H.; Kawakami, B.; Oka, M.; Imanaka, T. Characterization of DNA Polymerase from Pyrococcus sp. Strain KOD1 and Its Application to PCR. Appl. Environ. Microbiol. 1997, 63, 4504–4510. [Google Scholar] [CrossRef] [Green Version]
- Southworth, M.W.; Kong, H.; Kucera, R.B.; Ware, J.; Jannasch, H.W.; Perler, F.B. Cloning of Thermostable DNA Polymerases from Hyperthermophilic Marine Archaea with Emphasis on Thermococcus sp. 9 Degrees N-7 and Mutations Affecting 3′-5′ Exonuclease Activity. Proc. Natl. Acad. Sci. USA 1996, 93, 5281–5285. [Google Scholar] [CrossRef]
- Hopfner, K.P.; Eichinger, A.; Engh, R.A.; Laue, F.; Ankenbauer, W.; Huber, R.; Angerer, B. Crystal Structure of a Thermostable Type B DNA Polymerase from Thermococcus gorgonarius. Proc. Natl. Acad. Sci. USA 1999, 96, 3600–3605. [Google Scholar] [CrossRef] [Green Version]
- Cambon-Bonavita, M.A.; Schmitt, P.; Zieger, M.; Flaman, J.M.; Lesongeur, F.; Raguénès, G.; Bindel, D.; Frisch, N.; Lakkis, Z.; Dupret, D.; et al. Cloning, Expression, and Characterization of DNA Polymerase I from the Hyperthermophilic Archaea Thermococcus fumicolans. Extremophiles 2000, 4, 215–225. [Google Scholar] [CrossRef]
- Kim, Y.J.; Lee, H.S.; Bae, S.S.; Jeon, J.H.; Lim, J.K.; Cho, Y.; Nam, K.H.; Kang, S.G.; Kim, S.J.; Kwon, S.T.; et al. Cloning, Purification, and Characterization of a New DNA Polymerase from a Hyperthermophilic Archaeon, Thermococcus sp. NA1. J. Microbiol. Biotechnol. 2007, 17, 1090–1097. [Google Scholar]
- Lee, J.I.; Kim, Y.J.; Bae, H.; Cho, S.S.; Lee, J.H.; Kwon, S.T. Biochemical Properties and PCR Performance of a Family B DNA Polymerase from Hyperthermophilic Euryarchaeon Thermococcus peptonophilus. Appl. Biochem. Biotechnol. 2010, 160, 1585–1599. [Google Scholar] [CrossRef]
- Griffiths, K.; Nayak, S.; Park, K.; Mandelman, D.; Modrell, B.; Lee, J.; Ng, B.; Gibbs, M.D.; Bergquist, P.L. New High Fidelity Polymerases from Thermococcus species. Protein Expr. Purif. 2007, 52, 19–30. [Google Scholar] [CrossRef]
- Cho, S.S.; Kim, K.P.; Lee, K.K.; Youn, M.H.; Kwon, S.T. Characterization and PCR Application of a New High-Fidelity DNA Polymerase from Thermococcus waiotapuensis. Enzym. Microb. Technol. 2012, 51, 334–341. [Google Scholar] [CrossRef]
- Cline, J.; Braman, J.C.; Hogrefe, H.H. PCR Fidelity of pfu DNA Polymerase and Other Thermostable DNA Polymerases. Nucleic Acids Res. 1996, 24, 3546–3551. [Google Scholar] [CrossRef] [Green Version]
- Huang, H.; Keohavong, P. Fidelity and Predominant Mutations Produced by Deep Vent Wild-Type and Exonuclease-Deficient DNA Polymerases during in Vitro DNA Amplification. DNA Cell Biol. 1996, 15, 589–594. [Google Scholar] [CrossRef]
- Dietrich, J.; Schmitt, P.; Zieger, M.; Preve, B.; Rolland, J.L.; Chaabihi, H.; Gueguen, Y. PCR Performance of the Highly Thermostable Proof-Reading B-Type DNA Polymerase from Pyrococcus abyssi. FEMS Microbiol. Lett. 2002, 217, 89–94. [Google Scholar] [CrossRef]
- Ghasemi, A.; Salmanian, A.H.; Sadeghifard, N.; Salarian, A.A.; Gholi, M.K. Cloning, Expression and Purification of Pwo Polymerase from Pyrococcus woesei. Iran. J. Microbiol. 2011, 3, 118–122. [Google Scholar] [PubMed]
- Chien, A.; Edgar, D.B.; Trela, J.M. Deoxyribonucleic Acid Polymerase from the Extreme Thermophile Thermus aquaticus. J. Bacteriol. 1976, 127, 1550–1557. [Google Scholar] [CrossRef] [PubMed]
- Mullis, K.; Faloona, F.; Scharf, S.; Saiki, R.; Horn, G.; Erlich, H. Specific Enzymatic Amplification of DNA In Vitro: The Polymerase Chain Reaction. Cold Spring Harb. Symp. Quant. Biol. 1986, 51, 263–273. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Saiki, R.K.; Gelfand, D.H.; Stoffel, S.; Scharf, S.J.; Higuchi, R.; Horn, G.T.; Mullis, K.B.; Erlich, H.A. Primer-Directed Enzymatic Amplification of DNA with a Thermostable DNA Polymerase. Science 1988, 239, 487–491. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tindall, K.R.; Kunkel, T.A. Fidelity of DNA Synthesis by the Thermus aquaticus DNA Polymerase. Biochemistry 1988, 27, 6008–6013. [Google Scholar] [CrossRef] [PubMed]
- Arezi, B.; Xing, W.; Sorge, J.A.; Hogrefe, H.H. Amplification Efficiency of Thermostable DNA Polymerases. Anal. Biochem. 2003, 321, 226–235. [Google Scholar] [CrossRef]
- Barnes, W.M. The Fidelity of Taq Polymerase Catalyzing PCR Is Improved by an N-Terminal Deletion. Gene 1992, 112, 29–35. [Google Scholar] [CrossRef]
- Grabko, V.I.; Chistyakova, L.G.; Lyapustin, V.N.; Korobko, V.G.; Miroshnikov, A.I. Reverse Transcription, Amplification and Sequencing of Poliovirus RNA by Taq DNA Polymerase. FEBS Lett. 1996, 387, 189–192. [Google Scholar] [CrossRef] [Green Version]
- Bhadra, S.; Maranhao, A.C.; Paik, I.; Ellington, A.D. One-Enzyme Reverse Transcription qPCR Using Taq DNA Polymerase. Biochemistry 2020, 59, 4638–4645. [Google Scholar] [CrossRef]
- Jung, S.E.; Choi, J.J.; Kim, H.K.; Kwon, S.T. Cloning and Analysis of the DNA Polymerase-Encoding Gene from Thermus filiformis. Mol. Cells. 1997, 7, 769–776. [Google Scholar]
- Akhmetzjanov, A.A.; Vakhitov, V.A. Molecular Cloning and Nucleotide Sequence of the DNA Polymerase Gene from Thermus flavus. Nucleic Acids Res. 1992, 20, 5839. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Choi, J.J.; Kim, H.K.; Kwon, S.T. Purification and Characterization of the 5′→3′ Exonuclease Domain-Deleted Thermus filiformis DNA Polymerase Expressed in Escherichia coli. Biotechnol. Lett. 2001, 23, 1647–1652. [Google Scholar] [CrossRef]
- Zheng, W.; Lee, J.E.; Potter, R.J.; Mandelman, D. DNA Polymerase Blends and Mutant DNA Polymerases. U.S. Patent Application No 11/170,762, 28 December 2006. [Google Scholar]
- Aye, S.L.; Fujiwara, K.; Ueki, A.; Doi, N. Engineering of DNA Polymerase I from Thermus thermophilus Using Compartmentalized Self-Replication. Biochem. Biophys. Res. Commun. 2018, 499, 170–176. [Google Scholar] [CrossRef] [PubMed]
- Myers, T.W.; Gelfand, D.H. Reverse Transcription and DNA Amplification by a Thermus thermophilus DNA Polymerase. Biochemistry 1991, 30, 7661–7666. [Google Scholar] [CrossRef] [PubMed]
- Choli, T.; Henning, P.; Wittmann-Liebold, B.; Reinhardt, R. Isolation, Characterization and Microsequence Analysis of a Small Basic Methylated DNA-Binding Protein from the Archaebacterium, Sulfolobus solfataricus. Biochim. Biophys. Acta. 1988, 950, 193–203. [Google Scholar] [CrossRef] [PubMed]
- Sakai, H.D.; Kurosawa, N. Saccharolobus caldissimus Gen. nov., sp nov., a Facultatively Anaerobic Iron-Reducing Hyperthermophilic Archaeon Isolated from an Acidic Terrestrial Hot Spring, and Reclassification of Sulfolobus solfataricus as Saccharolobus solfataricus comb. Nov and Sulfolobus shibatae as Saccharolobus shibatae comb. nov. Int. J. Syst. Evol. Micr. 2018, 68, 1271–1278. [Google Scholar]
- Gao, Y.G.; Su, S.Y.; Robinson, H.; Padmanabhan, S.; Lim, L.; McCrary, B.S.; Edmondson, S.P.; Shriver, J.W.; Wang, A.H. The Crystal Structure of the Hyperthermophile Chromosomal Protein Sso7d Bound to DNA. Nat. Struct. Biol. 1998, 5, 782–786. [Google Scholar] [CrossRef]
- Wang, Y.; Prosen, D.E.; Mei, L.; Sullivan, J.C.; Finney, M.; Vander Horn, P.B. A Novel Strategy to Engineer DNA Polymerases for Enhanced Processivity and Improved Performance in Vitro. Nucleic Acids Res. 2004, 32, 1197–1207. [Google Scholar] [CrossRef]
- Al-Soud, W.A.; Radstrom, P. Purification and Characterization of PCR-Inhibitory Components in Blood Cells. J. Clin. Microbiol. 2001, 39, 485–493. [Google Scholar] [CrossRef] [Green Version]
- Wiedbrauk, D.L.; Werner, J.C.; Drevon, A.M. Inhibition of PCR by Aqueous and Vitreous Fluids. J. Clin. Microbiol. 1995, 33, 2643–2646. [Google Scholar] [CrossRef] [Green Version]
- Kwon, S.T.; Kim, J.S.; Park, J.H.; Kim, H.K.; Lee, D.S. Cloning and Analysis of the DNA Polymerase-Encoding Gene from Thermus caldophilus GK24. Mol. Cells. 1997, 7, 264–271. [Google Scholar] [PubMed]
- Perler, F.B.; Kumar, S.; Kong, H. Thermostable DNA Polymerases. Adv. Protein Chem. 1996, 48, 377–435. [Google Scholar] [PubMed]
- Aliotta, J.M.; Pelletier, J.J.; Ware, J.L.; Moran, L.S.; Benner, J.S.; Kong, H. Thermostable Bst DNA Polymerase I Lacks a 3′→5′ Proofreading Exonuclease Activity. Genet. Anal. Biomol. Eng. 1996, 12, 185–195. [Google Scholar] [CrossRef]
- Nazina, T.N.; Tourova, T.P.; Poltaraus, A.B.; Novikova, E.V.; Grigoryan, A.A.; Ivanova, A.E.; Lysenko, A.M.; Petrunyaka, V.V.; Osipov, G.A.; Belyaev, S.S.; et al. Taxonomic Study of Aerobic Thermophilic Bacilli: Descriptions of Geobacillus subterraneus Gen. nov., sp. nov. and Geobacillus uzenensis sp. nov. from Petroleum Reservoirs and Transfer of Bacillus stearothermophilus, Bacillus thermocatenulatus, Bacillus thermoleovorans, Bacillus kaustophilus, Bacillus thermodenitrificans to Geobacillus as the New Combinations G. stearothermophilus, G. thermocatenulatus, G. thermoleovorans, G. kaustophilus, G. thermoglucosidasius and G. thermodenitrificans. Int. J. Syst. Evol. Microbiol. 2001, 51, 433–446. [Google Scholar]
- Hayashizaki, Y.; Itoh, M.; Benno, Y.; Lezhava, A. Novel DNA Polymerase. U.S. Patent Application No. 20100047862A1, 25 February 2010. [Google Scholar]
- Notomi, T.; Okayama, H.; Masubuchi, H.; Yonekawa, T.; Watanabe, K.; Amino, N.; Hase, T. Loop-Mediated Isothermal Amplification of DNA. Nucleic Acids Res. 2000, 28, e63. [Google Scholar] [CrossRef]
- Oscorbin, I.P.; Belousova, E.A.; Boyarskikh, U.A.; Zakabunin, A.I.; Khrapov, E.A.; Filipenko, M.L. Derivatives of Bst-Like Gss-Polymerase with Improved Processivity and Inhibitor Tolerance. Nucleic Acids Res. 2017, 45, 9595–9610. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kelly, R.M.; Adams, M.W. Metabolism in Hyperthermophilic Microorganisms. Antonie Van Leeuwenhoek 1994, 66, 247–270. [Google Scholar]
- Stetter, K.O. A Brief History of the Discovery of Hyperthermophilic Life. Biochem. Soc. Trans. 2013, 41, 416–420. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gelfand, D.H.; Lawyer, F.C.; Stoffel, S. Mutated Thermostable Nucleic Acid Polymerase Enzyme from Thermotoga maritima. U.S. Patent No. 5,420,029, 30 May 1995. [Google Scholar]
- Diaz, R.S.; Sabino, E.C. Accuracy of Replication in the Polymerase Chain Reaction. Comparison between Thermotoga maritima DNA Polymerase and Thermus aquaticus DNA Polymerase. Brazilian J. Med. Biol. Res. 1998, 31, 1239–1242. [Google Scholar] [CrossRef] [Green Version]
- Davalieva, K.G.; Efremov, G.D. A New Thermostable DNA Polymerase Mixture for Efficient Amplification of Long DNA Fragments. Appl. Biochem. Microbiol. 2010, 46, 230–234. [Google Scholar] [CrossRef]
- Lundberg, K.S.; Shoemaker, D.D.; Adams, M.W.; Short, J.M.; Sorge, J.A.; Mathur, E.J. High-Fidelity Amplification Using a Thermostable DNA Polymerase Isolated from Pyrococcus furiosus. Gene 1991, 108, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Atomi, H.; Fukui, T.; Kanai, T.; Morikawa, M.; Imanaka, T. Description of Thermococcus kodakaraensis sp. nov., a Well Studied Hyperthermophilic Archaeon Previously Reported as Pyrococcus sp. KOD1. Archaea 2004, 1, 263–267. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nishioka, M.; Mizuguchi, H.; Fujiwara, S.; Komatsubara, S.; Kitabayashi, M.; Uemura, H.; Takagi, M.; Imanaka, T. Long and Accurate PCR with a Mixture of KOD DNA Polymerase and Its Exonuclease Deficient Mutant Enzyme. J. Biotechnol. 2001, 88, 141–149. [Google Scholar] [CrossRef]
- Slupphaug, G.; Alseth, I.; Eftedal, I.; Volden, G.; Krokan, H.E. Low Incorporation of dUMP by Some Thermostable DNA Polymerases May Limit Their Use in PCR Amplifications. Anal. Biochem. 1993, 211, 164–169. [Google Scholar] [CrossRef] [PubMed]
- Jannasch, H.W.; Wirsen, C.O.; Molyneaux, S.J.; Langworthy, T.A. Comparative Physiological Studies on Hyperthermophilic Archaea Isolated from Deep-Sea Hot Vents with Emphasis on Pyrococcus Strain GB-D. Appl. Environ. Microbiol. 1992, 58, 3472–3481. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gueguen, Y.; Rolland, J.L.; Lecompte, O.; Azam, P.; Le Romancer, G.; Flament, D.; Raffin, J.P.; Dietrich, J. Characterization of Two DNA Polymerases from the Hyperthermophilic Euryarchaeon Pyrococcus abyssi. Eur. J. Biochem. 2001, 268, 5961–5969. [Google Scholar] [CrossRef]
- Dabrowski, S.; Kur, J. Cloning and Expression in Escherichia coli of the Recombinant His-Tagged DNA Polymerases from Pyrococcus furiosus and Pyrococcus woesei. Protein Expr. Purif. 1998, 14, 131–138. [Google Scholar] [CrossRef]
- Hidajat, R.; McNicol, P. Primer-Directed Mutagenesis of an Intact Plasmid by Using Pwo DNA Polymerase in Long Distance Inverse PCR. Biotechniques 1997, 22, 32–34. [Google Scholar] [CrossRef]
- Coulther, T.A.; Stern, H.R.; Beuning, P.J. Engineering Polymerases for New Functions. Trends Biotechnol. 2019, 37, 1091–1103. [Google Scholar] [CrossRef]
- Romero, P.A.; Arnold, F.H. Exploring Protein Fitness Landscapes by Directed Evolution. Nat. Rev. Mol. Cell Biol. 2009, 10, 866–876. [Google Scholar] [CrossRef] [Green Version]
- Nikoomanzar, A.; Chim, N.; Yik, E.J.; Chaput, J.C. Engineering Polymerases for Applications in Synthetic Biology. Q. Rev. Biophys. 2020, 53, e8. [Google Scholar] [CrossRef] [PubMed]
- McCullum, E.O.; Williams, B.A.; Zhang, J.L.; Chaput, J.C. Random Mutagenesis by Error-Prone PCR. Methods Mol. Biol. 2010, 634, 103–109. [Google Scholar] [PubMed]
- Stemmer, W.P. Rapid Evolution of a Protein in Vitro by DNA Shuffling. Nature 1994, 370, 389–391. [Google Scholar] [CrossRef] [PubMed]
- Stemmer, W.P. DNA Shuffling by Random Fragmentation and Reassembly: In Vitro Recombination for Molecular Evolution. Proc. Natl. Acad. Sci. USA 1994, 91, 10747–10751. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Giver, L.; Shao, Z.; Affholter, J.A.; Arnold, F.H. Molecular Evolution by Staggered Extension Process (StEP) In Vitro Recombination. Nat. Biotechnol. 1998, 16, 258–261. [Google Scholar] [CrossRef]
- Ness, J.E.; Kim, S.; Gottman, A.; Pak, R.; Krebber, A.; Borchert, T.V.; Govindarajan, S.; Mundorff, E.C.; Minshull, J. Synthetic Shuffling Expands Functional Protein Diversity by Allowing Amino Acids to Recombine Independently. Nat. Biotechnol. 2002, 20, 1251–1255. [Google Scholar] [CrossRef]
- Milligan, J.N.; Garry, D.J. Shuffle Optimizer: A Program to Optimize DNA Shuffling for Protein Engineering. Methods Mol. Biol. 2017, 1472, 35–45. [Google Scholar]
- Milligan, J.N.; Shroff, R.; Garry, D.J.; Ellington, A.D. Evolution of a Thermophilic Strand-Displacing Polymerase Using High-Temperature Isothermal Compartmentalized Self-Replication. Biochemistry 2018, 57, 4607–4619. [Google Scholar] [CrossRef] [Green Version]
- Huang, P.S.; Boyken, S.E.; Baker, D. The Coming of Age of De Novo Protein Design. Nature 2016, 537, 320–327. [Google Scholar] [CrossRef]
- Marcos, E.; Silva, D.A. Essentials of De Novo Protein Design: Methods and Applications. Wires Comput. Mol. Sci. 2018, 8, e1374. [Google Scholar] [CrossRef]
- Guerois, R.; Nielsen, J.E.; Serrano, L. Predicting Changes in the Stability of Proteins and Protein Complexes: A Study of More than 1000 Mutations. J. Mol. Biol. 2002, 320, 369–387. [Google Scholar] [CrossRef]
- Rohl, C.A.; Strauss, C.E.M.; Misura, K.M.S.; Baker, D. Protein Structure Prediction Using Rosetta. Methods Enzymol. 2004, 383, 66–93. [Google Scholar]
- Capriotti, E.; Fariselli, P.; Casadio, R. I-Mutant2.0: Predicting Stability Changes upon Mutation from the Protein Sequence or Structure. Nucleic Acids Res. 2005, 33, W306–W310. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wijma, H.J.; Floor, R.J.; Jekel, P.A.; Baker, D.; Marrink, S.J.; Janssen, D.B. Computationally Designed Libraries for Rapid Enzyme Stabilization. Protein Engi. Des. Sel. 2014, 27, 49–58. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goldenzweig, A.; Goldsmith, M.; Hill, S.E.; Gertman, O.; Laurino, P.; Ashani, Y.; Dym, O.; Unger, T.; Albeck, S.; Prilusky, J.; et al. Automated Structure- and Sequence-Based Design of Proteins for High Bacterial Expression and Stability. Mol. Cell 2016, 63, 337–346. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Alley, E.C.; Khimulya, G.; Biswas, S.; AlQuraishi, M.; Church, G.M. Unified Rational Protein Engineering with Sequence-Based Deep Representation Learning. Nat. Methods 2019, 16, 1315–1322. [Google Scholar] [CrossRef]
- Paik, I.; Ngo, P.H.T.; Shroff, R.; Diaz, D.J.; Maranhao, A.C.; Walker, D.J.F.; Bhadra, S.; Ellington, A.D. Improved Bst DNA Polymerase Variants Derived via a Machine Learning Approach. Biochemistry 2021. [Google Scholar] [CrossRef]
- Yang, K.K.; Wu, Z.; Arnold, F.H. Machine-Learning-Guided Directed Evolution for Protein Engineering. Nat. Methods 2019, 16, 687–694. [Google Scholar] [CrossRef]
- O’Maille, P.E.; Bakhtina, M.; Tsai, M.D. Structure-Based Combinatorial Protein Engineering (SCOPE). J Mol Biol. 2002, 321, 677–691. [Google Scholar] [CrossRef]
- Reetz, M.T.; Bocola, M.; Carballeira, J.D.; Zha, D.; Vogel, A. Expanding the Range of Substrate Acceptance of Enzymes: Combinatorial Active-Site Saturation Test. Angew. Chem. Int. Edit. 2005, 44, 4192–4196. [Google Scholar] [CrossRef]
- Reetz, M.T.; Carballeira, J.D. Iterative Saturation Mutagenesis (ISM) for Rapid Directed Evolution of Functional Enzymes. Nat. Protoc. 2007, 2, 891–903. [Google Scholar] [CrossRef] [PubMed]
- Wong, T.S.; Tee, K.L.; Hauer, B.; Schwaneberg, U. Sequence Saturation Mutagenesis (SeSaM): A Novel Method for Directed Evolution. Nucleic Acids Res. 2004, 32, e26. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fox, R.J.; Davis, S.C.; Mundorff, E.C.; Newman, L.M.; Gavrilovic, V.; Ma, S.K.; Chung, L.M.; Ching, C.; Tam, S.; Muley, S.; et al. Improving Catalytic Function by ProSAR-Driven Enzyme Evolution. Nat. Biotechnol. 2007, 25, 338–344. [Google Scholar] [CrossRef] [PubMed]
- Cole, M.F.; Gaucher, E.A. Exploiting Models of Molecular Evolution to Efficiently Direct Protein Engineering. J. Mol. Evol. 2011, 72, 193–203. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, T.; Hongdilokkul, N.; Liu, Z.; Adhikary, R.; Tsuen, S.S.; Romesberg, F.E. Evolution of Thermophilic DNA Polymerases for the Recognition and Amplification of C2′-Modified DNA. Nat. Chem. 2016, 8, 556–562. [Google Scholar] [CrossRef]
- Markel, U.; Essani, K.D.; Besirlioglu, V.; Schiffels, J.; Streit, W.R.; Schwaneberg, U. Advances in Ultrahigh-Throughput Screening for Directed Enzyme Evolution. Chem. Soc. Rev. 2020, 49, 233–262. [Google Scholar]
- Esvelt, K.M.; Carlson, J.C.; Liu, D.R. A System for the Continuous Directed Evolution of Biomolecules. Nature 2011, 472, 499–503. [Google Scholar] [CrossRef] [Green Version]
- Tawfik, D.S.; Griffiths, A.D. Man-Made Cell-Like Compartments for Molecular Evolution. Nat. Biotechnol. 1998, 16, 652–656. [Google Scholar] [CrossRef]
- Ghadessy, F.J.; Ong, J.L.; Holliger, P. Directed Evolution of Polymerase Function by Compartmentalized Self-Replication. Proc. Natl. Acad. Sci. USA 2001, 98, 4552–4557. [Google Scholar] [CrossRef]
- Ong, J.L.; Loakes, D.; Jaroslawski, S.; Too, K.; Holliger, P. Directed Evolution of DNA Polymerase, RNA Polymerase and Reverse Transcriptase Activity in a Single Polypeptide. J. Mol. Biol. 2006, 361, 537–550. [Google Scholar] [CrossRef]
- Ellefson, J.W.; Gollihar, J.; Shroff, R.; Shivram, H.; Iyer, V.R.; Ellington, A.D. Synthetic Evolutionary Origin of a Proofreading Reverse Transcriptase. Science 2016, 352, 1590–1593. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shroff, R.; Ellefson, J.W.; Wang, S.S.; Boulgakov, A.A.; Hughes, R.A.; Ellington, A.D. Recovery of Information Stored in Modified DNA with an Evolved Polymerase. ACS Synth. Biol. 2022, 11, 554–561. [Google Scholar] [CrossRef] [PubMed]
- Ellefson, J.W.; Meyer, A.J.; Hughes, R.A.; Cannon, J.R.; Brodbelt, J.S.; Ellington, A.D. Directed Evolution of Genetic Parts and Circuits by Compartmentalized Partnered Replication. Nat. Biotechnol. 2014, 32, 97–101. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, V.B.; Taylor, A.I.; Cozens, C.; Abramov, M.; Renders, M.; Zhang, S.; Chaput, J.C.; Wengel, J.; Peak-Chew, S.Y.; McLaughlin, S.H.; et al. Synthetic Genetic Polymers Capable of Heredity and Evolution. Science 2012, 336, 341–344. [Google Scholar] [CrossRef] [Green Version]
- Houlihan, G.; Arangundy-Franklin, S.; Porebski, B.T.; Subramanian, N.; Taylor, A.I.; Holliger, P. Discovery and Evolution of RNA and XNA Reverse Transcriptase Function and Fidelity. Nat. Chem. 2020, 12, 683–690. [Google Scholar] [CrossRef] [PubMed]
- Paegel, B.M.; Joyce, G.F. Microfluidic Compartmentalized Directed Evolution. Chem. Biol. 2010, 17, 717–724. [Google Scholar] [CrossRef] [Green Version]
- Larsen, A.C.; Dunn, M.R.; Hatch, A.; Sau, S.P.; Youngbull, C.; Chaput, J.C. A General Strategy for Expanding Polymerase Function by Droplet Microfluidics. Nat. Commun. 2016, 7, 11235. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Price, A.K.; Paegel, B.M. Discovery in Droplets. Anal. Chem. 2016, 88, 339–353. [Google Scholar] [CrossRef] [Green Version]
- Nikoomanzar, A.; Vallejo, D.; Chaput, J.C. Elucidating the Determinants of Polymerase Specificity by Microfluidic-Based Deep Mutational Scanning. ACS Synth. Biol. 2019, 8, 1421–1429. [Google Scholar] [CrossRef]
- Taylor, A.I.; Houlihan, G.; Holliger, P. Beyond DNA and RNA: The Expanding Toolbox of Synthetic Genetics. Cold Spring Harbor Perspect. Biol. 2019, 11, a032490. [Google Scholar] [CrossRef] [Green Version]
- Ohashi, S.; Hashiya, F.; Abe, H. Variety of Nucleotide Polymerase Mutants Aiming to Synthesize Modified RNA. ChemBioChem 2021, 22, 2398–2406. [Google Scholar] [CrossRef] [PubMed]
- Sawai, H.; Ozaki-Nakamura, A.; Mine, M.; Ozaki, H. Synthesis of New Modified DNAs by Hyperthermophilic DNA Polymerase: Substrate and Template Specificity of Functionalized Thymidine Analogues Bearing an sp3-Hybridized Carbon at the C5 Alpha-Position for Several DNA Polymerases. Bioconjugate Chem. 2002, 13, 309–316. [Google Scholar] [CrossRef] [PubMed]
- Kuwahara, M.; Nagashima, J.; Hasegawa, M.; Tamura, T.; Kitagata, R.; Hanawa, K.; Hososhima, S.; Kasamatsu, T.; Ozaki, H.; Sawai, H. Systematic Characterization of 2′-Deoxynucleoside-5′-triphosphate Analogs as Substrates for DNA Polymerases by Polymerase Chain Reaction and Kinetic Studies on Enzymatic Production of Modified DNA. Nucleic Acids Res. 2006, 34, 5383–5394. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mehedi Masud, M.; Ozaki-Nakamura, A.; Kuwahara, M.; Ozaki, H.; Sawai, H. Modified DNA Bearing 5(Methoxycarbonylmethyl)-2′-deoxyuridine: Preparation by PCR with Thermophilic DNA Polymerase and Postsynthetic Derivatization. ChemBioChem 2003, 4, 584–588. [Google Scholar] [CrossRef]
- Hottin, A.; Marx, A. Structural Insights into the Processing of Nucleobase-Modified Nucleotides by DNA Polymerases. Accounts Chem. Res. 2016, 49, 418–427. [Google Scholar] [CrossRef]
- Jager, S.; Rasched, G.; Kornreich-Leshem, H.; Engeser, M.; Thum, O.; Famulok, M. A Versatile Toolbox for Variable DNA Functionalization at High Density. J. Am. Chem. Soc. 2005, 127, 15071–15082. [Google Scholar] [CrossRef]
- Baccaro, A.; Steck, A.L.; Marx, A. Barcoded Nucleotides. Angew. Chem. Int. Edit. 2012, 51, 254–257. [Google Scholar] [CrossRef] [Green Version]
- Pochet, S.; Kaminski, P.A.; Van Aerschot, A.; Herdewijn, P.; Marlière, P. Replication of Hexitol Oligonucleotides as a Prelude to the Propagation of a Third Type of Nucleic Acid in Vivo. C. R. Biol. 2003, 326, 1175–1184. [Google Scholar] [CrossRef]
- Jackson, L.N.; Chim, N.; Shi, C.H.; Chaput, J.C. Crystal Structures of a Natural DNA Polymerase that Functions as an XNA Reverse Transcriptase. Nucleic Acids Res. 2019, 47, 6973–6983. [Google Scholar] [CrossRef]
- Tsai, C.H.; Chen, J.; Szostak, J.W. Enzymatic Synthesis of DNA on Glycerol Nucleic Acid Templates without Stable Duplex Formation between Product and Template. Proc. Natl. Acad. Sci. USA 2007, 104, 14598–14603. [Google Scholar] [CrossRef] [Green Version]
- Kempeneers, V.; Renders, M.; Froeyen, M.; Herdewijn, P. Investigation of the DNA-Dependent Cyclohexenyl Nucleic Acid Polymerization and the Cyclohexenyl Nucleic Acid-Dependent DNA Polymerization. Nucleic Acids Res. 2005, 33, 3828–3836. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chaput, J.C.; Ichida, J.K.; Szostak, J.W. DNA Polymerase-Mediated DNA Synthesis on a TNA Template. J. Am. Chem. Soc. 2003, 125, 856–857. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, C.G.; Damha, M.J. Polymerase-Directed Synthesis of 2′-Deoxy-2′-fluoro-beta-D-arabinonucleic Acids. J. Am. Chem. Soc. 2007, 129, 5310–5311. [Google Scholar] [CrossRef] [PubMed]
- Joyce, C.M. Choosing the Right Sugar: How Polymerases Select a Nucleotide Substrate. Proc. Natl. Acad. Sci. USA 1997, 94, 1619–1622. [Google Scholar] [CrossRef] [Green Version]
- Anosova, I.; Kowai, E.A.; Dunn, M.R.; Chaput, J.C.; Van Horn, W.D.; Egli, M. The Structural Diversity of Artificial Genetic Polymers. Nucleic Acids Res. 2016, 44, 1007–1021. [Google Scholar] [CrossRef] [Green Version]
- Gardner, A.F.; Jackson, K.M.; Boyle, M.M.; Buss, J.A.; Potapov, V.; Gehring, A.M.; Zatopek, K.M.; Corrêa, I.R., Jr.; Ong, J.L.; Jack, W.E. Therminator DNA Polymerase: Modified Nucleotides and Unnatural Substrates. Front. Mol. Biosci. 2019, 6, 28. [Google Scholar] [CrossRef] [Green Version]
- Staiger, N.; Marx, A. A DNA Polymerase with Increased Reactivity for Ribonucleotides and C5-Modified Deoxyribonucleotides. ChemBioChem 2010, 11, 1963–1966. [Google Scholar] [CrossRef] [Green Version]
- Ichida, J.K.; Horhota, A.; Zou, K.; McLaughlin, L.W.; Szostak, J.W. High Fidelity TNA Synthesis by Therminator Polymerase. Nucleic Acids Res. 2005, 33, 5219–5225. [Google Scholar] [CrossRef] [Green Version]
- Fa, M.; Radeghieri, A.; Henry, A.A.; Romesberg, F.E. Expanding the Substrate Repertoire of a DNA Polymerase by Directed Evolution. J. Am. Chem. Soc. 2004, 126, 1748–1754. [Google Scholar] [CrossRef]
- Song, P.; Zhang, R.; He, C.; Chen, T. Transcription, Reverse Transcription, and Amplification of Backbone-Modified Nucleic Acids with Laboratory-Evolved Thermophilic DNA Polymerases. Curr. Protoc. 2021, 1, e188. [Google Scholar] [CrossRef]
- Chen, T.; Romesberg, F.E. Enzymatic Synthesis, Amplification, and Application of DNA with a Functionalized Backbone. Angew. Chem. Int. Edit. 2017, 56, 14046–14051. [Google Scholar] [CrossRef] [PubMed]
- Arangundy-Franklin, S.; Taylor, A.I.; Porebski, B.T.; Genna, V.; Peak-Chew, S.; Vaisman, A.; Woodgate, R.; Orozco, M.; Holliger, P. A Synthetic Genetic Polymer with an Uncharged Backbone Chemistry Based on Alkyl Phosphonate Nucleic Acids. Nat. Chem. 2019, 11, 533–542. [Google Scholar] [CrossRef] [PubMed]
- Dunn, M.R.; Otto, C.; Fenton, K.E.; Chaput, J.C. Improving Polymerase Activity with Unnatural Substrates by Sampling Mutations in Homologous Protein Architectures. ACS Chem. Biol. 2016, 11, 1210–1219. [Google Scholar] [CrossRef] [PubMed]
- Nikoomanzar, A.; Vallejo, D.; Yik, E.J.; Chaput, J.C. Programmed Allelic Mutagenesis of a DNA Polymerase with Single Amino Acid Resolution. ACS Synth. Biol. 2020, 9, 1873–1881. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.; Cozens, C.; Jaziri, F.; Rozenski, J.; Marechal, A.; Dumbre, S.; Pezo, V.; Marlière, P.; Pinheiro, V.B.; Groaz, E.; et al. Phosphonomethyl Oligonucleotides as Backbone-Modified Artificial Genetic Polymers. J. Am. Chem. Soc. 2018, 140, 6690–6699. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoshino, H.; Kasahara, Y.; Kuwahara, M.; Obika, S. DNA Polymerase Variants with High Processivity and Accuracy for Encoding and Decoding Locked Nucleic Acid Sequences. J. Am. Chem. Soc. 2020, 142, 21530–21537. [Google Scholar] [CrossRef] [PubMed]
- Medina, E.; Yik, E.J.; Herdewijn, P.; Chaput, J.C. Functional Comparison of Laboratory-Evolved XNA Polymerases for Synthetic Biology. ACS Synth. Biol. 2021, 10, 1429–1437. [Google Scholar] [CrossRef]
- Ghadessy, F.J.; Ramsay, N.; Boudsocq, F.; Loakes, D.; Brown, A.; Iwai, S.; Vaisman, A.; Woodgate, R.; Holliger, P. Generic Expansion of the Substrate Spectrum of a DNA Polymerase by Directed Evolution. Nat. Biotechnol. 2004, 22, 755–759. [Google Scholar] [CrossRef]
- Cozens, C.; Pinheiro, V.B.; Vaisman, A.; Woodgate, R.; Holliger, P. A Short Adaptive Path from DNA to RNA Polymerases. Proc. Natl. Acad. Sci. USA 2012, 109, 8067–8072. [Google Scholar] [CrossRef]
- Cozens, C.; Mutschler, H.; Nelson, G.M.; Houlihan, G.; Taylor, A.I.; Holliger, P. Enzymatic Synthesis of Nucleic Acids with Defined Regioisomeric 2′-5′ Linkages. Angew. Chem. Int. Edit. 2015, 54, 15570–15573. [Google Scholar] [CrossRef] [Green Version]
- Freund, N.; Taylor, A.I.; Arangundy-Franklin, S.; Subramanian, N.; Peak-Chew, S.Y.; Whitaker, A.M.; Freudenthal, B.D.; Abramov, M.; Herdewijn, P.; Holliger, P. A Two-Residue Nascent-Strand Steric Gate Controls Synthesis of 2′-O-methyl- and 2′-O-(2-methoxyethyl)-RNA. Nat. Chem. 2022. [Google Scholar] [CrossRef] [PubMed]
- Li, Q.; Maola, V.A.; Chim, N.; Hussain, J.; Lozoya-Colinas, A.; Chaput, J.C. Synthesis and Polymerase Recognition of Threose Nucleic Acid Triphosphates Equipped with Diverse Chemical Functionalities. J. Am. Chem. Soc. 2021, 143, 17761–17768. [Google Scholar] [CrossRef] [PubMed]
- Brown, J.A.; Suo, Z. Unlocking the Sugar “Steric Gate” of DNA Polymerases. Biochemistry 2011, 50, 1135–1142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vichier-Guerre, S.; Ferris, S.; Auberger, N.; Mahiddine, K.; Jestin, J.L. A Population of Thermostable Reverse Transcriptases Evolved from Thermus aquaticus DNA Polymerase I by Phage Display. Angew. Chem. Int. Edit. 2006, 45, 6133–6137. [Google Scholar] [CrossRef] [PubMed]
- Blatter, N.; Bergen, K.; Nolte, O.; Welte, W.; Diederichs, K.; Mayer, J.; Wieland, M.; Marx, A. Structure and Function of an RNA-Reading Thermostable DNA Polymerase. Angew. Chem. Int. Edit. 2013, 52, 11935–11939. [Google Scholar] [CrossRef] [Green Version]
- Aschenbrenner, J.; Marx, A. Direct and Site-Specific Quantification of RNA 2′-O-methylation by PCR with an Engineered DNA Polymerase. Nucleic Acids Res. 2016, 44, 3495–3502. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fogg, M.J.; Pearl, L.H.; Connolly, B.A. Structural Basis for Uracil Recognition by Archaeal Family B DNA Polymerases. Nat. Struct. Biol. 2002, 9, 922–927. [Google Scholar] [CrossRef]
- Chim, N.; Shi, C.; Sau, S.P.; Nikoomanzar, A.; Chaput, J.C. Structural Basis for TNA Synthesis by an Engineered TNA Polymerase. Nat. Commun. 2017, 8, 1810. [Google Scholar] [CrossRef] [Green Version]
- Horhota, A.; Zou, K.; Ichida, J.K.; Yu, B.; McLaughlin, L.W.; Szostak, J.W.; Chaput, J.C. Kinetic Analysis of an Efficient DNA-Dependent TNA Polymerase. J. Am. Chem. Soc. 2005, 127, 7427–7434. [Google Scholar] [CrossRef]
- Gardner, A.F.; Jack, W.E. Determinants of Nucleotide Sugar Recognition in an Archaeon DNA Polymerase. Nucleic Acids Res. 1999, 27, 2545–2553. [Google Scholar] [CrossRef] [Green Version]
- Duffy, K.; Arangundy-Franklin, S.; Holliger, P. Modified Nucleic Acids: Replication, Evolution, and Next-Generation Therapeutics. BMC Biol. 2020, 18, 112. [Google Scholar] [CrossRef] [PubMed]
- Chan, J.H.; Lim, S.; Wong, W.S. Antisense Oligonucleotides: From Design to Therapeutic Application. Clin. Exp. Pharmacol. Physiol. 2006, 33, 533–540. [Google Scholar] [CrossRef] [PubMed]
- Eckstein, F. Phosphorothioates, Essential Components of Therapeutic Oligonucleotides. Nucl. Acid Ther. 2014, 24, 374–387. [Google Scholar] [CrossRef] [PubMed]
- Perry, C.M.; Balfour, J.A. Fomivirsen. Drugs 1999, 57, 375–380; discussion 381. [Google Scholar] [CrossRef]
- Liang, X.H.; Sun, H.; Shen, W.; Crooke, S.T. Identification and Characterization of Intracellular Proteins that Bind Oligonucleotides with Phosphorothioate Linkages. Nucleic Acids Res. 2015, 43, 2927–2945. [Google Scholar] [CrossRef] [Green Version]
- Stein, C.A.; Subasinghe, C.; Shinozuka, K.; Cohen, J.S. Physicochemical Properties of Phosphorothioate Oligodeoxynucleotides. Nucleic Acids Res. 1988, 16, 3209–3221. [Google Scholar] [CrossRef]
- Kurreck, J. Antisense Technologies. Improvement through Novel Chemical Modifications. Eur. J. Biochem. 2003, 270, 1628–1644. [Google Scholar] [CrossRef]
- Bennett, C.F.; Swayze, E.E. RNA Targeting Therapeutics: Molecular Mechanisms of Antisense Oligonucleotides as a Therapeutic Platform. Annu. Rev. Pharmacol. Toxicol. 2010, 50, 259–293. [Google Scholar] [CrossRef]
- Geary, R.S.; Baker, B.F.; Crooke, S.T. Clinical and Preclinical Pharmacokinetics and Pharmacodynamics of Mipomersen (Kynamro®): A Second-Generation Antisense Oligonucleotide Inhibitor of Apolipoprotein B. Clin. Pharmacokinet. 2015, 54, 133–146. [Google Scholar] [CrossRef]
- Lok, C.N.; Viazovkina, E.; Min, K.L.; Nagy, E.; Wilds, C.J.; Damha, M.J.; Parniak, M.A. Potent Gene-Specific Inhibitory Properties of Mixed-Backbone Antisense Oligonucleotides Comprised of 2′-Deoxy-2′-fluoro-d-arabinose and 2′-Deoxyribose Nucleotides. Biochemistry 2002, 41, 3457–3467. [Google Scholar] [CrossRef]
- Damha, M.J.; Wilds, C.J.; Noronha, A.; Brukner, I.; Borkow, G.; Arion, D.; Parniak, M.A. Hybrids of RNA and Arabinonucleic Acids (ANA and 2′ F-ANA) Are Substrates of Ribonuclease h. J. Am. Chem. Soc. 1998, 120, 12976–12977. [Google Scholar] [CrossRef]
- Fluiter, K.; Frieden, M.; Vreijling, J.; Rosenbohm, C.; De Wissel, M.B.; Christensen, S.M.; Koch, T.; Ørum, H.; Baas, F. On the in Vitro and in Vivo Properties of Four Locked Nucleic Acid Nucleotides Incorporated into an Anti-H-Ras Antisense Oligonucleotide. ChemBioChem 2005, 6, 1104–1109. [Google Scholar] [CrossRef] [PubMed]
- Kaur, H.; Babu, B.R.; Maiti, S. Perspectives on Chemistry and Therapeutic Applications of Locked Nucleic Acid (LNA). Chem. Rev. 2007, 107, 4672–4697. [Google Scholar] [CrossRef] [PubMed]
- Walter, N.G.; Engelke, D.R. Ribozymes: Catalytic RNAs That Cut Things, Make Things, and Do Odd and Useful Jobs. Biologist 2002, 49, 199–203. [Google Scholar] [PubMed]
- Micura, R.; Höbartner, C. Fundamental Studies of Functional Nucleic Acids: Aptamers, Riboswitches, Ribozymes and DNAzymes. Chem. Soc. Rev. 2020, 49, 7331–7353. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Liu, J. Catalytic Nucleic Acids: Biochemistry, Chemical Biology, Biosensors, and Nanotechnology. iScience 2020, 23, 100815. [Google Scholar] [CrossRef] [Green Version]
- Taylor, A.I.; Pinheiro, V.B.; Smola, M.J.; Morgunov, A.S.; Peak-Chew, S.; Cozens, C.; Weeks, K.M.; Herdewijn, P.; Holliger, P. Catalysts from Synthetic Genetic Polymers. Nature 2015, 518, 427–430. [Google Scholar] [CrossRef] [Green Version]
- Wang, Y.; Ngor, A.K.; Nikoomanzar, A.; Chaput, J.C. Evolution of a General RNA-Cleaving FANA Enzyme. Nat. Commun. 2018, 9, 5067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, Y.; Nguyen, K.; Spitale, R.C.; Chaput, J.C. A Biologically Stable DNAzyme That Efficiently Silences Gene Expression in Cells. Nat. Chem. 2021, 13, 319–326. [Google Scholar] [CrossRef]
- Wilds, C.J.; Damha, M.J. 2′-Deoxy-2′-fluoro-beta-D-arabinonucleosides and Oligonucleotides (2′F-ANA): Synthesis and Physicochemical Studies. Nucleic Acids Res. 2000, 28, 3625–3635. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, Y.; Song, D.; Sun, X.; Zhang, Z.; Li, X.; Li, Z.; Yu, H. A Threose Nucleic Acid Enzyme with RNA Ligase Activity. J. Am. Chem. Soc. 2021, 143, 8154–8163. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Wang, Y.; Song, D.F.; Sun, X.; Li, Z.; Chen, J.Y.; Yu, H. An RNA-Cleaving Threose Nucleic Acid Enzyme Capable of Single Point Mutation Discrimination. Nat. Chem. 2022, 14, 350–359. [Google Scholar] [CrossRef] [PubMed]
- Ran, F.A.; Hsu, P.D.; Wright, J.; Agarwala, V.; Scott, D.A.; Zhang, F. Genome Engineering Using the CRISPR-Cas9 System. Nat. Protoc. 2013, 8, 2281–2308. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rahdar, M.; McMahon, M.A.; Prakash, T.P.; Swayze, E.E.; Bennett, C.F.; Cleveland, D.W. Synthetic CRISPR RNA-Cas9–Guided Genome Editing in Human Cells. Proc. Natl. Acad. Sci. USA 2015, 112, E7110–E7117. [Google Scholar] [CrossRef] [Green Version]
- Ryan, D.E.; Taussig, D.; Steinfeld, I.; Phadnis, S.M.; Lunstad, B.D.; Singh, M.; Vuong, X.; Okochi, K.D.; McCaffrey, R.; Olesiak, M.; et al. Improving CRISPR–Cas Specificity with Chemical Modifications in Single-Guide RNAs. Nucleic Acids Res. 2018, 46, 792–803. [Google Scholar] [CrossRef]
- Mir, A.; Alterman, J.F.; Hassler, M.R.; Debacker, A.J.; Hudgens, E.; Echeverria, D.; Brodsky, M.H.; Khvorova, A.; Watts, J.K.; Sontheimer, E.J. Heavily and Fully Modified RNAs Guide Efficient SpyCas9-Mediated Genome Editing. Nat. Commun. 2018, 9, 2641. [Google Scholar] [CrossRef] [Green Version]
- Cromwell, C.R.; Sung, K.; Park, J.; Krysler, A.R.; Jovel, J.; Kim, S.K.; Hubbard, B.P. Incorporation of Bridged Nucleic Acids into CRISPR RNAs Improves Cas9 Endonuclease Specificity. Nat. Commun. 2018, 9, 1448. [Google Scholar] [CrossRef] [Green Version]
- Kong, H.Y.; Byun, J. Nucleic Acid Aptamers: New Methods for Selection, Stabilization, and Application in Biomedical Science. Biomol. Ther. 2013, 21, 423–434. [Google Scholar] [CrossRef] [Green Version]
- Ng, E.W.; Shima, D.T.; Calias, P.; Cunningham, E.T., Jr.; Guyer, D.R.; Adamis, A.P. Pegaptanib, a Targeted Anti-VEGF Aptamer for Ocular Vascular Disease. Nat. Rev. Drug Discov. 2006, 5, 123–132. [Google Scholar] [CrossRef]
- Liu, Z.; Chen, T.; Romesberg, F.E. Evolved Polymerases Facilitate Selection of Fully 2′-OMe-Modified Aptamers. Chem. Sci. 2017, 8, 8179–8182. [Google Scholar] [CrossRef] [Green Version]
- Rangel, A.E.; Chen, Z.; Ayele, T.M.; Heemstra, J.M. In Vitro Selection of an XNA Aptamer Capable of Small-Molecule Recognition. Nucleic Acids Res. 2018, 46, 8057–8068. [Google Scholar] [CrossRef] [PubMed]
- Rose, K.M.; Alves Ferreira-Bravo, I.; Li, M.; Craigie, R.; Ditzler, M.A.; Holliger, P.; DeStefano, J.J. Selection of 2′-Deoxy-2′-Fluoroarabino Nucleic Acid (FANA) Aptamers that Bind HIV-1 Integrase with Picomolar Affinity. ACS Chem. Biol. 2019, 14, 2166–2175. [Google Scholar] [CrossRef] [PubMed]
- Alves Ferreira-Bravo, I.; Cozens, C.; Holliger, P.; DeStefano, J.J. Selection of 2′-Deoxy-2′-Fluoroarabinonucleotide (FANA) Aptamers That Bind HIV-1 Reverse Transcriptase with Picomolar Affinity. Nucleic Acids Res. 2015, 43, 9587–9599. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Inoue, N.; Shionoya, A.; Minakawa, N.; Kawakami, A.; Ogawa, N.; Matsuda, A. Amplification of 4′-ThioDNA in the Presence of 4′-Thio-dTTP and 4′-Thio-dCTP, and 4′-Thio-DNA-Directed Transcription in Vitro and in Mammalian Cells. J. Am. Chem. Soc. 2007, 129, 15424–15425. [Google Scholar] [CrossRef] [PubMed]
- Pezo, V.; Liu, F.W.; Abramov, M.; Froeyen, M.; Herdewijn, P.; Marlière, P. Binary Genetic Cassettes for Selecting XNA-Templated DNA Synthesis in Vivo. Angew. Chem. Int. Edit. 2013, 125, 8297–8301. [Google Scholar] [CrossRef]
- Nguyen, H.; Abramov, M.; Eremeeva, E.; Herdewijn, P. In Vivo Expression of Genetic Information from Phosphoramidate–DNA. ChemBioChem 2020, 21, 272–278. [Google Scholar] [CrossRef]
- Kukwikila, M.; Gale, N.; El-Sagheer, A.H.; Brown, T.; Tavassoli, A. Assembly of a Biocompatible Triazole-Linked Gene by One-Pot Click-DNA Ligation. Nat. Chem. 2017, 9, 1089–1098. [Google Scholar] [CrossRef]
- Kim, K.R.; Kim, H.Y.; Lee, Y.D.; Ha, J.S.; Kang, J.H.; Jeong, H.; Bang, D.; Ko, Y.T.; Kim, S.; Lee, H.; et al. Self-Assembled Mirror DNA Nanostructures for Tumor-Specific Delivery of Anticancer Drugs. J. Control. Release 2016, 243, 121–131. [Google Scholar] [CrossRef]
- Gamberi, G.; Morandi, L.; Benini, S.; Resca, A.; Cocchi, S.; Magagnoli, G.; Donati, D.M.; Righi, A.; Gambarotti, M. Detection of H3F3A p. G35W and p. G35R in Giant Cell Tumor of Bone by Allele Specific Locked Nucleic Acid Quantitative PCR (ASLNAqPCR). Pathol. Res. Pract. 2018, 214, 89–94. [Google Scholar] [CrossRef]
- Chaput, J.C. Redesigning the Genetic Polymers of Life. Accounts Chem. Res. 2021, 54, 1056–1065. [Google Scholar] [CrossRef]
- Mana, T.; Bhattacharya, B.; Lahiri, H.; Mukhopadhyay, R. XNAs: A Troubleshooter for Nucleic acid Sensing. Acs Omega 2022, 7, 15296–15307. [Google Scholar] [CrossRef] [PubMed]
- Freund, N.; Fürst, M.J.L.J.; Holliger, P. New Chemistries and Enzymes for Synthetic Genetics. Curr. Opin. Biotechnol. 2022, 74, 129–136. [Google Scholar] [CrossRef]
- Taylor, A.I.; Beuron, F.; Peak-Chew, S.Y.; Morris, E.P.; Herdewijn, P.; Holliger, P. Nanostructures from Synthetic Genetic Polymers. ChemBioChem 2016, 17, 1107–1110. [Google Scholar] [CrossRef]
- Pavlov, A.R.; Pavlova, N.V.; Kozyavkin, S.A.; Slesarev, A.I. Recent Developments in the Optimization of Thermostable DNA Polymerases for Efficient Applications. Trends Biotechnol. 2004, 22, 253–260. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, V.B.; Holliger, P. The XNA World: Progress towards Replication and Evolution of Synthetic Genetic Polymers. Curr. Opin. Chem. Biol. 2012, 16, 245–252. [Google Scholar] [CrossRef] [PubMed]
- Pinheiro, V.B.; Holliger, P. Towards XNA Nanotechnology: New Materials from Synthetic Genetic Polymers. Trends Biotechnol. 2014, 32, 321–328. [Google Scholar] [CrossRef] [Green Version]
- Malik, T.N.; Chaput, J.C. XNA Enzymes by Evolution and Design. Curr. Res. Chem. Biol. 2021, 1, 100012. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
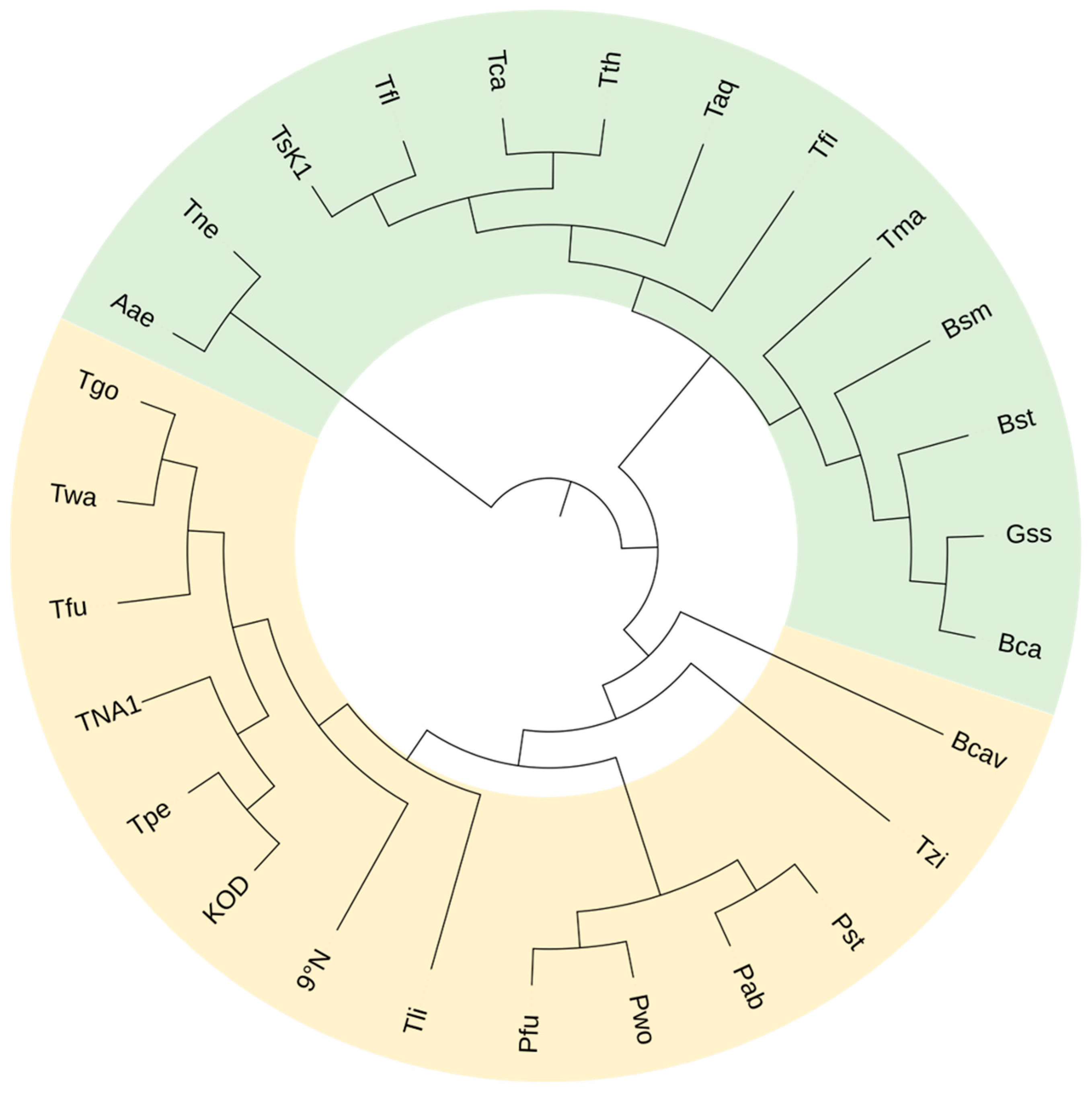
| Family | DNAP | Source | Properties | Ref. | |||
|---|---|---|---|---|---|---|---|
| 5′-3′ Exo | 3′-5′ Exo | Error Rate | Half-Life Time | ||||
| A | Taq | Thermus aquaticus | Yes | No | 1.2 × 10−5–3.3 × 10−6 | 97.5 °C/9 min | [25,26] |
| Tfi | Thermus filiformis | Yes | No | / | 94 °C/40 min | [27] | |
| Tth | Thermus thermophilus | Yes | No | / | 94 °C/20 min | [10,28] | |
| Tfl | Thermus flavus | Yes | No | / | 95 °C/40 min | [9,29] | |
| Tca | Thermus caldophilus | Yes | No | / | 95 °C/70 min | [30] | |
| TsK1 | Thermus scotoductus | Yes | No | / | 95 °C/15 min | [31] | |
| Bst | Bacillus stearothermophilus | Yes | No | / | / | [32] | |
| Bca | Bacillus caldotenax | Yes | No | / | / | [33] | |
| Bcav | Bacillus caldovelox | Yes | No | / | / | [34] | |
| Bsm | Bacillus smithii | Yes | No | / | / | [35] | |
| Gss | Geobacillus sp. 777 | Yes | No | / | / | [36] | |
| Tma | Thermotoga maritima | Yes | Yes | / | / | [37] | |
| Tne | Thermotoga neapolitana | Yes | Yes | 3.4 × 10−5 | / | [38,39] | |
| Aae | Aquifex aeolicus | No | Yes | / | 75 °C/6 h 85 °C/1.7 h | [40] | |
| B | Tli | Thermococcus litoralis | No | Yes | 2.8 × 10−6 | 100 °C/2 h | [41] |
| KOD | Thermococcus kodakaraensis | No | Yes | 2.6 × 10−6 | 95 °C/12 h | [42] | |
| 9°N | Thermococcus sp. 9°N-7 | No | Yes | / | / | [43] | |
| Tgo | Thermococcus gorganarius | No | Yes | 3.3–2.2 × 10−6 | / | [44] | |
| Tfu | Thermococcus fumicolans | No | Yes | 5.3–0.9 × 10−5 | 100 °C/2 h | [45] | |
| TNA1 | Thermococcus sp. NA1 | No | Yes | 2.2 × 10−4 | 95 °C/12.5 h 100 °C/3.5 h | [46] | |
| Tpe | Thermococcus peptonophilus | No | Yes | 3.37 × 10−6 | 90 °C/4 h | [47] | |
| Tzi | Thermococcus zilligii | No | Yes | 2 × 10−6 | / | [48] | |
| Twa | Thermococcus waiotapuensis | No | Yes | 7.4 × 10−6 | 99 °C/4 h | [49] | |
| Pfu | Pyrococcus furiosus | No | Yes | 1.3 × 10−6 | / | [50] | |
| Pst | Pyrococcus GB-D | No | Yes | 2.7 × 10−6 | 95 °C/23 h | [50,51] | |
| Pab | Pyrococcus abyssi | No | Yes | 0.66–1.39 × 10−6 | 100 °C/5 h | [52] | |
| Pwo | Pyrococcus woesei | No | Yes | / | 95 °C/8 h | [10,53] | |
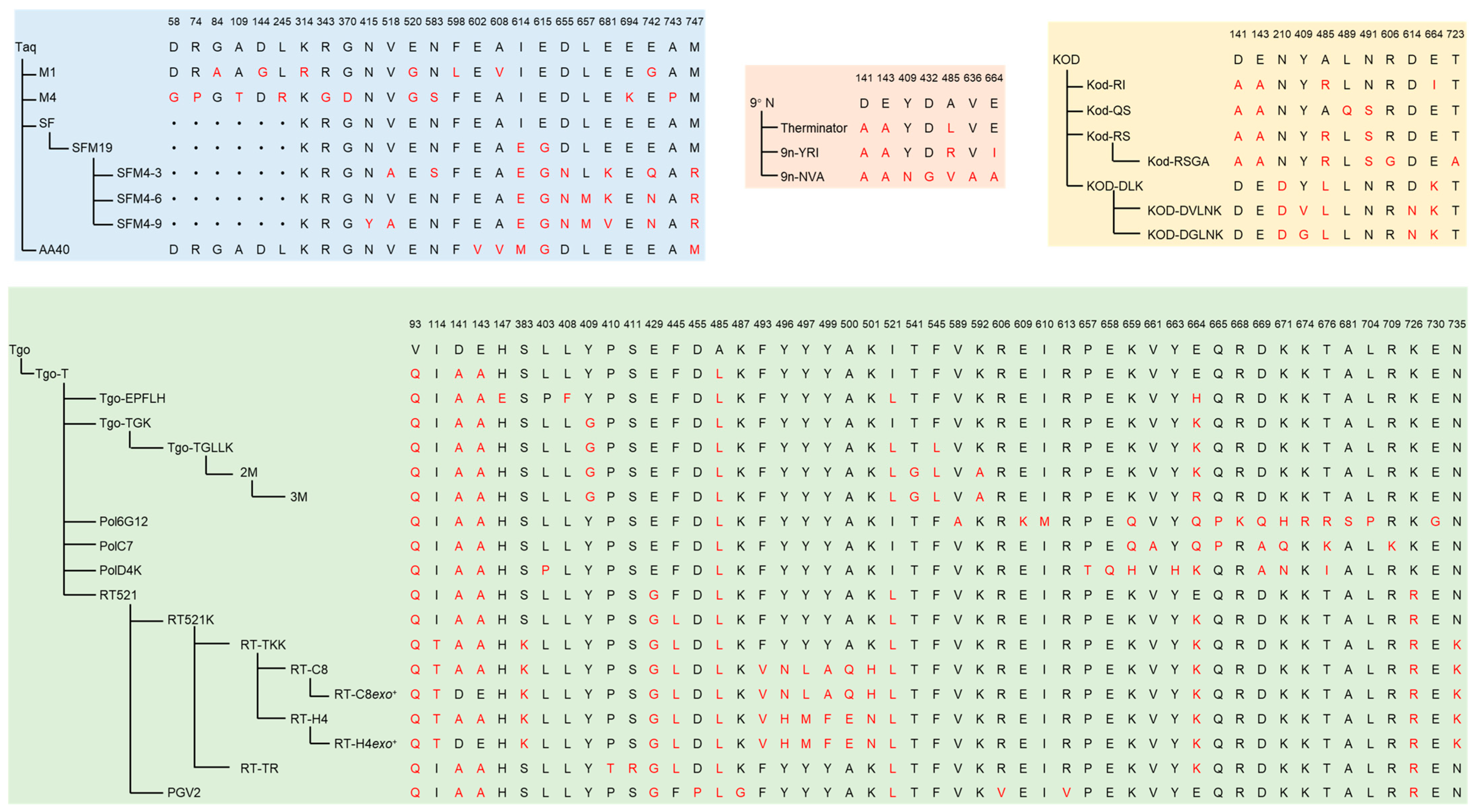
| Parental DNAP | Mutant | Method Employed for Engineering | Mutation Sites | Unnatural Activity | Ref. |
|---|---|---|---|---|---|
| Taq | AA40 | spCSR | E602V, A608V, I614M, E615G | Synthesis of 2′-F, 2′-N3 and 2′-OMe-RNA | [125] |
| SFM19 | Phage display | I614E, E615G | Synthesis of 2′-OMe-modified RNA | [154] | |
| SFM4-3 | Phage display | I614E, E615G, V518A, N583S, D655N, E681K, E742Q, M747R | Synthesis or amplification of 2′-OMe, 2′-F, 2′-Az, 2′-Cl, 2′-Am-modified DNA/RNA and ANA | [120] | |
| SFM4-6 | Phage display | I614E, E615G, D655N, L657M, E681K, E742N, M747R | Synthesis of 2′-F-DNA and 2′-OMe-RNA | [120] | |
| SFM4-9 | Phage display | I614E, E615G, N415Y, V518A, D655N, L657M, E681V, E742N, M747R | Synthesis of DNA from a 2′-F-DNA or 2′-OMe-RNA template | [120] | |
| M1 | CSR | G84A, D144G, K314R, E520G, F598L, A608V, E742G | PCR of phosphorothioate or fluorescent dye-modified DNA | [163] | |
| M4 | CSR | D58G, R74P, A109T, L245R, R343G, G370D, E520G, N583S, E694K, A743P | PCR of phosphorothioate or fluorescent dye-modified DNA | [163] | |
| Tgo | Tgo-RI | SDM * | D141A, E143A, A485R, E664I | Synthesis of TNA | [158] |
| Tgo TGK | SDM * | TgoT: Y409G, E664K | Synthesis of pseudouridine-, 5-methyl-C-, 2′-F-, 2′-Az-modified RNAs, FANA, ANA, HNA and TNA | [162,164] | |
| Tgo TGLLK | SDM * | TgoT: Y409G, I521L, F545L, E664K | Synthesis of 3′-deoxy- or 3′-O-methyl-modified RNA | [165] | |
| RT521 | CST | TgoT: E429G, I521L, K726R | Synthesis of DNA from an HNA, ANA, FANA or tPhoNA template | [129] | |
| RT521K | CST | RT521: F445L, E664K | Synthesis of DNA from an LNA or CeNA template | [129] | |
| RT-TKK | CBL | RT521K: I114T, S383K, N735K | Synthesis of DNA from a 2′-OMe-RNA or AtNA template | [130] | |
| RT-C8 | CBL | RT-TKK: F493V, Y496N, Y497L, Y499A, A500Q, K501H | Synthesis of DNA from a 2′-OMe-RNA, HNA, AtNA, 2′-MOE-RNA or PS 2′-MOE-RNA template | [130] | |
| RT-C8exo+ | SDM * | RT-TKK: A141D, A143E, F493V, Y496N, Y497L, Y499A, A500Q, K501H | Synthesis of DNA from a 2′-OMe-RNA, HNA, AtNA, 2′-MOE-RNA or PS 2′-MOE-RNA template | [130] | |
| RT-H4 | CBL | RT-TKK: F493V, Y496H, Y497M, Y499F, A500E, K501N | Synthesis of DNA from an HNA template | [130] | |
| RT-H4exo+ | SDM * | RT-TKK: A141D, A143E, F493V, Y496H, Y497M, Y499F, A500E, K501N | Synthesis of DNA from an HNA template | [130] | |
| RT-TR | CBL | RT521K: P410T, S411R | Synthesis of DNA from a 2′-OMe-RNA, HNA, AtNAs, 2′-MOE-RNA or PS 2′-MOE-RNA template with enhanced fidelity | [130] | |
| PolC7 | CST | TgoT: K659Q, V661A, E664Q, Q665P, D669A, K671Q, T676K, R709K | Synthesis of CeNA and LNA | [129] | |
| PolD4K | CST | TgoT: L403P, P657T, E658Q, K659H, Y663H, E664K, D669A, K671N, T676I | Synthesis of FANA, ANA, TNA, HNA, and PMT | [129,162] | |
| Pol6G12 | CST | TgoT: V589A, E609K, I610M, K659Q, E664Q, Q665P, R668K, D669Q, K671H, K674R, T676R, A681S, L704P, E730G | Synthesis of HNA and FANA | [129,162] | |
| 6G12-I521L | SDM * | Pol6G12: I521L | Synthesis of HNA and FANA | [162] | |
| Tgo EPFLH | SDM * | V93Q, D141A, E143A, H147E, L403P, L408F, A485L, I521L, E664H | Synthesis of PMT, ANA, TNA, FANA and tPhoNA | [160,162] | |
| 2M | SDM * | TGLLK: T541G, K592A | Synthesis of 2′-MOE-RNA and 2′-OMe-RNA | [166] | |
| 3M | SDM * | TGLLK: T541G, K592A, K664R | Synthesis of 2′-MOE-RNA and 2′-OMe-RNA | [166] | |
| KOD | KOD DGLNK | SDM * | N210D, Y409G, A485L, D614N, E664K | Synthesis of 2′-OMe-RNA and LNA | [161] |
| KOD DLK | SDM * | N210D, A485L, E664K | Synthesis of DNA from an LNA template | [161] | |
| Kod RI | SDM * | D141A, E143A, A485R, E664I | Synthesis of TNA | [158] | |
| Kod RS | DrOPS | D141A, E143A, A485R, N491S | Synthesis of TNA | [134] | |
| Kod QS | DrOPS | D141A, E143A, L489Q, N491S | Synthesis of TNA | [134] | |
| Kod RSGA | DrOPS | D141A, E143A, A485R, N491S, R606G, T723A | Synthesis of FANA, ANA, HNA, TNA, C5-modified TNA, and PMT | [159,162,167] | |
| KOD RTX | RT-CSR | F38L, R97M, K118I, M137L, R381H, Y384H, V389I, K466R, Y493L, T514I, I521L, F587L, E664K, G711V, N735K, W768R | Synthesis of DNA from a 2′-OMe-RNA template | [126] | |
| KOD RTX-Ome v6 | RT-CSR | RTX: A40V, E251K, S340P, G350V, V353L, H381R, H384Y, K468N, I488L, G498A, K664R | Synthesis of DNA from a 2′-OMe-RNA template | [127] | |
| KOD RT521K | SDM * | V93E, D141A, E143A, A485L, I521L, E664K | Synthesis of DNA from a tPhoNA template | [160] | |
| 9°N | 9°N Therminator | SDM * | D141A, E143A, A485L | Synthesis of TNA | [153] |
| 9n-YRI | DrOPS | D141A, E143A, A485R, E664I | Synthesis of TNA | [132] | |
| 9n- NVA | DrOPS | D141A, E143A, V409N, A485V, E664A, D432G, V636A | Synthesis of TNA | [132] | |
| Deep Vent | Deep Vent RI | SDM * | D141A, E143A, A485R, E664I | Synthesis of TNA | [158] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, G.; Du, Y.; Ma, X.; Ye, F.; Qin, Y.; Wang, Y.; Xiang, Y.; Tao, R.; Chen, T. Thermophilic Nucleic Acid Polymerases and Their Application in Xenobiology. Int. J. Mol. Sci. 2022, 23, 14969. https://doi.org/10.3390/ijms232314969
Wang G, Du Y, Ma X, Ye F, Qin Y, Wang Y, Xiang Y, Tao R, Chen T. Thermophilic Nucleic Acid Polymerases and Their Application in Xenobiology. International Journal of Molecular Sciences. 2022; 23(23):14969. https://doi.org/10.3390/ijms232314969
Chicago/Turabian StyleWang, Guangyuan, Yuhui Du, Xingyun Ma, Fangkai Ye, Yanjia Qin, Yangming Wang, Yuming Xiang, Rui Tao, and Tingjian Chen. 2022. "Thermophilic Nucleic Acid Polymerases and Their Application in Xenobiology" International Journal of Molecular Sciences 23, no. 23: 14969. https://doi.org/10.3390/ijms232314969