
The Entropy Gain of Linear Systems and Some of Its Implications


1
Department of Electronic Engineering, Universidad Técnica Federico Santa María, Av. España 1680, Valparaíso 2390123, Chile
2
Department of Electronic Systems, Aalborg University, 9220 Aalborg, Denmark
*
Authors to whom correspondence should be addressed.
Entropy 2021, 23(8), 947; https://doi.org/10.3390/e23080947
Submission received: 23 May 2021
/
Revised: 12 July 2021
/
Accepted: 20 July 2021
/
Published: 24 July 2021
(This article belongs to the Section Information Theory, Probability and Statistics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
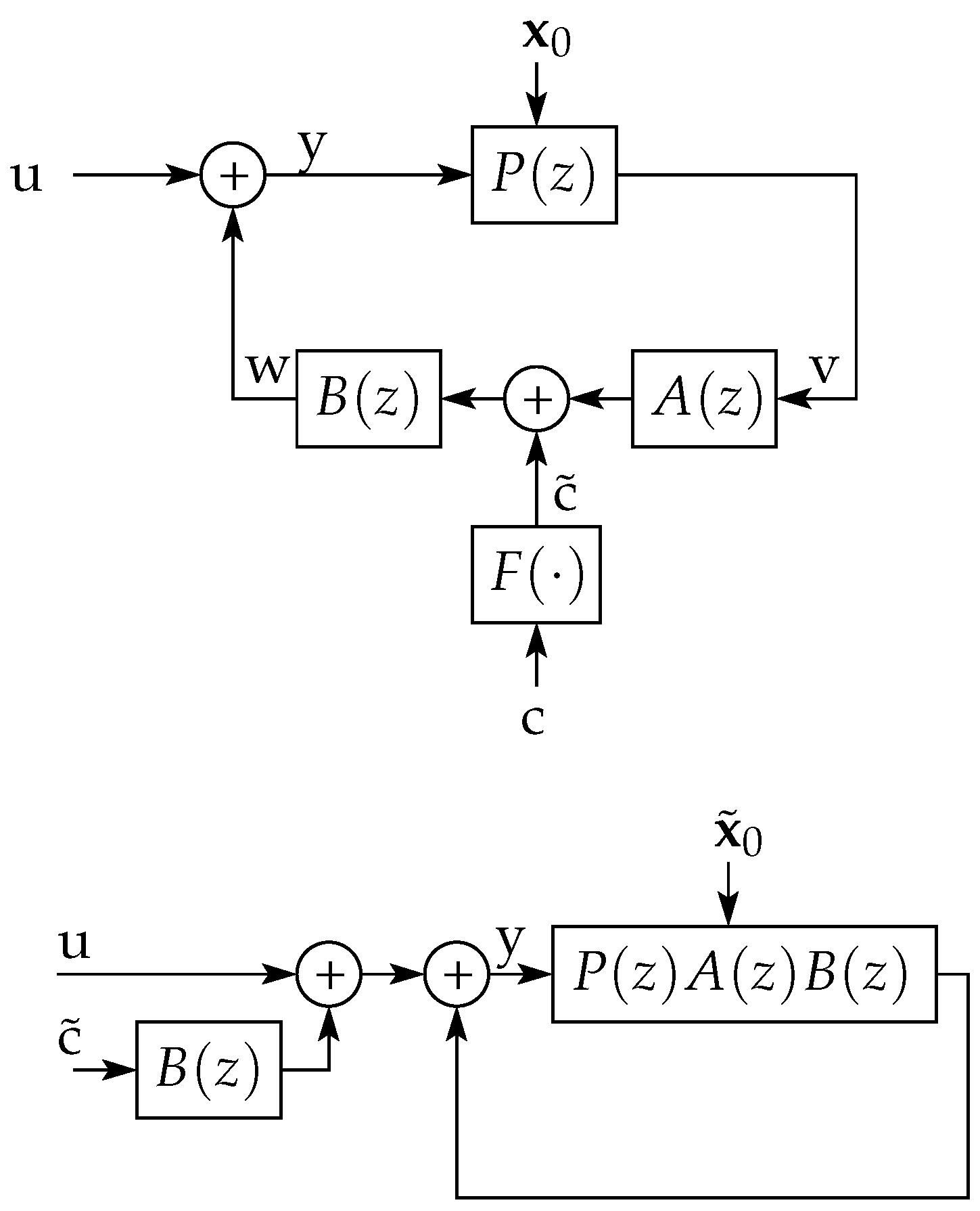{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We study the increase in per-sample differential entropy rate of random sequences and processes after being passed through a non minimum-phase (NMP) discrete-time, linear time-invariant (LTI) filter G. For LTI discrete-time filters and random processes, it has long been established by Theorem 14 in Shannon’s seminal paper that this entropy gain, , equals the integral of . In this note, we first show that Shannon’s Theorem 14 does not hold in general. Then, we prove that, when comparing the input differential entropy to that of the entire (longer) output of G, the entropy gain equals . We show that the entropy gain between equal-length input and output sequences is upper bounded by and arises if and only if there exists an output additive disturbance with finite differential entropy (no matter how small) or a random initial state. Unlike what happens with linear maps, the entropy gain in this case depends on the distribution of all the signals involved. We illustrate some of the consequences of these results by presenting their implications in three different problems. Specifically: conditions for equality in an information inequality of importance in networked control problems; extending to a much broader class of sources the existing results on the rate-distortion function for non-stationary Gaussian sources, and an observation on the capacity of auto-regressive Gaussian channels with feedback.
1. Introduction
We study the difference between the differential entropy rate of a random process entering a discrete-time linear time-invariant (LTI) system G and the differential entropy rate of its (possibly noisy) output , as depicted in Figure 1.
Recall that the differential entropy rate of a random process is given by , provided the limit exists, where is the differential entropy of the ensemble with probability density function (PDF) f [1]. The system G is supposed to satisfy the following:
Assumption 1.
The LTI system G in Figure 1 is causal and stable and such that
- 1.
- G has a rational p-th order transfer function with m zeros outside the unit circle, i.e., non-minimum-phase (NMP) zeros, where , indexed in non-increasing magnitude order, i.e., .
- 2.
- The unit-impulse response of G, say, satisfies .
In this general setup, G may have a random initial state vector , , and a real-valued random output disturbance . Our main purpose is to characterize the limit
evaluating the possible effect produced by and . This difference can be interpreted as the entropy gain (entropy amplification or entropy boost) introduced by the filter G and (as apparent from the other variables in the argument of ) the statistics of . We shall refer to the special case in which and are both zero (or deterministic) as the noise-less case, and write accordingly.
The earliest reference related to this problem corresponds to a noise-less continuous-time counterpart considered by Shannon. In his seminal 1948 paper [2], Shannon gave a formula for the change in differential entropy per degree of freedom that a continuous-time random process , band-limited to a frequency range (in Hz), experiences after passing through an LTI continuous-time filter (without considering a random initial state or an output disturbance). Such entropy per degree of freedom is defined in terms of uniformly taken samples as
with . In this formula, if the LTI filter has frequency response (with in Hz), then the resulting differential entropy rate of the output process is given by the following theorem:
Theorem 1
(Reference [2], Theorem 14). If an ensemble having an entropy per degree of freedom in band B is passed through a filter with characteristic the output ensemble has an entropy
Shannon arrived at (3) by arguing that an LTI filter can be seen as a linear operator that selectively scales its input signal along infinitely many frequencies, each of them representing an orthogonal component of the source. He then obtained the result by writing down the determinant of the Jacobian of this operator as the product of the squared frequency response magnitude of the filter over n frequency bands, applying logarithm, dividing by n, and then taking the limit as n tends to infinity.
Remark 1.
There is a factor of two in excess in the integral on the right-hand side (RHS) of (3). To see this, consider a filter with a constant gain a over (i.e., a simple multiplicative factor). In such case, the entropy rate of should exceed that of by [1]. However, (3) yields an entropy gain equal to . This error arises because the determinant of the Jacobian of the transformation is actually the product of over the n frequency bands considered in Shannon’s argument. Such excess factor of two is also present in the entropy losses appearing in Reference [2], Table 1.
Theorem 14 in Reference [2] has found application in works ranging from traditional themes, such as linear prediction [3] and source coding [4], to molecular communication systems [5,6].
The available literature treating the phenomenon itself of the entropy gain (loss, boost, or amplification) induced by LTI systems seems to be rather scarce. This is not surprising given that (3) was published in Reference [2], Theorem 14, the work which gave birth to Information Theory.
The following publication concerned with this problem is Reference [7], following a time-domain analysis for the corresponding discrete-time problem. In this approach, one can obtain as a function of , for every , and evaluate the difference between the limits and , obtained by letting . More precisely, for an LTI discrete-time filter G with impulse response , we can write
where we adopt the notation for column vectors to avoid the abuse of notation incurred by treating the sequence as a vector, and because, by writing , it is easier to remember that its samples are ordered from top to bottom. and the random vector is defined likewise. From this, it is clear (see, e.g., the corollary after Theorem 8.6.4 in Reference [1]) that
where (or simply ) stands for the determinant of . This result is utilized in Reference [7] to show that no entropy gain is produced by a stable minimum phase LTI system G if and only if the first sample in its impulse response has unit magnitude.
In Reference [8], p. 568, the entropy gain of a discrete-time LTI system G (the noise-less version of the setup depicted in Figure 1) is found to be
where is the filter’s discrete-time output process (without the effect of random initial state or an output disturbance) and
This result was obtained starting from the fact that, for a Gaussian stationary process with power spectral density (PSD) , . If enters a discrete-time LTI system with frequency response , then the PSD of its output is ; thus, it is argued that (6) follows for Gaussian stationary inputs. Then, Reference [8] extends the result for non-Gaussian inputs with a proof sketch which uses a time-domain relation, like (4), to point out that the filter is a linear operator and, as such, the differential entropy of its output exceeds that of its input by a quantity that is independent of the input distribution. (It is worth noting that (6) is the discrete-time equivalent of (3) (without its wrong factor of 2), which follows directly from the correspondence between sampled band-limited continuous-time systems and discrete-time systems.)
It is in Reference [9], Section II-C, where, for the first time, it is shown that, for a stationary Gaussian input , the full entropy gain predicted by (6) takes place if the system output is contaminated by an additive output disturbance of length p and positive definite covariance matrix, where p is the order of .
The integral can be related to the structure of the filter G. It is well known (from Jensen’s formula) that if G has a causal and stable rational transfer function and an impulse response with its first sample , then
where are the zeros of (see, e.g., References [10,11]). This provides a straightforward formula to evaluate of a given LTI filter with rational transfer function . When combined with (6), this equation also reveals that if the entropy gain is negative (i.e., if it corresponds to an entropy loss), then (with the corresponding change of variables, this is the case in all the examples given by Shannon in Reference [2], Table 1). More importantly, (8) allows us to concentrate, without loss of generality, on LTI systems , whose first impulse-response sample has unit magnitude, as required by Assumption 1. Under the latter condition, (8) shows that the entropy gain is greater than zero if and only if has zeros outside the unit disk . A system with the latter property is said to be non-minimum phase (NMP); conversely, a system with all its zeros inside is said to be minimum phase (MP) [11].
1.1. Main Contributions of this Paper
The main contributions of this paper can be summarized as follows:
- Our first main result is showing that (6) and (3) do not hold for a large class of continuous-time filters and inputs. To see this, notice thatwhich, in view of (5), is equivalent to . In turn, this implies that , regardless of whether (i.e., the polynomial ) has zeros with magnitude greater than one (choose, for example, , and for ). This reveals that (4) holds if and only is MP. But (6) and (3) are equivalent (correcting for the in excess factor of 2 discussed in Remark 1); thus, Theorem 14 in Reference [2] also does not hold for a class of continuous-time filters. However, the transfer function of a band-limited continuous-time filter is defined only for imaginary values of s (because the bilateral Laplace transform of converges only on the imaginary axis), so one cannot classify such filters as MP or NMP. Instead, we consider a class of continuous-time filters limited to the frequencies in the band , where is in [Hz], defined by having a unit-impulse response of the formfor some absolutely summable sequence of real-valued coefficients , , where the sinc functionsSince every such g satisfies for , it makes sense to refer to such filters as “sample-wise causal”. For this class of band-limited filters, we show that Theorem 14 holds if and only if the z-transform of is MP:
Theorem 2.
- 2.
- We show that actually corresponds to the entropy gain introduced by G but considering the new notion of effective differential entropy rate of proposed in this paper, defined next.Definition 1(The Effective Differential Entropy). Let be a random vector. If can be written as a linear transformation , for some () with bounded differential entropy, , then the effective differential entropy of is defined aswhere is an SVD for , with .We can now state our second main result, the proof of which is in Appendix A:Theorem 3.Let be the input of an LTI system G with transfer function without zeros on the unit circle and with an absolutely summable unit impulse response , with if G has an infinite impulse response. Denote the output of G as . Suppose for every finite n. Then,where denotes the entire response of G to the input .Theorem 3 states that, when considering the full-length output of a system, the effective entropy gain is introduced by the system itself.Section 4 provides a geometrical description of the phenomenon behind Definition 1 and Theorem 3.
- 2.
- We show that is a tight upper bound to the entropy gain of G (as defined in (1)), when the output is contaminated by some additional additive signal, such as a random initial state (represented by in Figure 1) or an output disturbance (such as in Figure 1), with sufficiently many degrees of freedom (a condition formally stated in Assumption 2 below). Moreover, we show that an entropy gain equal to the latter upper bound can appear even when these disturbances or random initial state have infinitesimally small variances. To the best of our knowledge, the latter phenomenon has been discussed in the literature first (and only) in Reference [9], Section II-C, for Gaussian stationary inputs and an LTI filter. We go beyond the latter result by explicitly and fully characterizing the entropy gain of LTI systems for a large class of not necessarily Gaussian nor stationary random input. We refer to this class as entropy-balanced processes, formally specified in the following definition:Definition 2.A random process is said to be entropy balanced if the following two conditions are satisfied:
- (i)
- Its sample variances are finite for finite n and
- (ii)
- For every and for every sequence of matrices , with orthonormal rows,
The second condition guarantees that projecting an entropy-balanced process onto any subspace having finitely fewer dimensions yields a process with the same differential entropy rate.The entropy gain induced by finite-length output disturbances is characterized by our next theorem.Theorem 4.In the system of Figure 1, let G satisfy Assumption 1 and suppose that is entropy balanced. Suppose the random output disturbance is such that , and that . Let , where m is the number of NMP zeros of . Then,with equality in if and only if .The proof is presented in Section 6.4, and we provide geometrical insight explaining the phenomenon underlying Definition 2 and Theorem 4 in Section 5.1. - 2.
- We illustrate the relevance of the results summarized above by applying them to three problems in three areas, namely:
- (a)
- Networked Control: We show that equality holds in the inequality stated in Reference [12], Lemma 3.2 (a fundamental piece for the performance limitation results further developed in Reference [13]), under very general conditions. In addition, we extend the validity of a related equality for the perfect-feedback case, given by Reference [14], Theorem 14, for Gaussian signals, to the much larger class of entropy-balanced processes.
- (b)
- The rate-distortion function for non-stationary Gaussian sources: This problem has been previously solved in References [15,16,17]. We provide a simpler proof based upon the results described above. This proof extends the result stated in References [16,17] to a broader class of non-stationary sources.
- (c)
- Gaussian channel capacity with feedback: We show that capacity results based on using a short random sequence as channel input and relying on a feedback filter which boosts the entropy rate of the end-to-end channel noise (such as the one proposed in Reference [9]), crucially depend upon the complete absence of any additional disturbance anywhere in the system. Specifically, we show that the information rate of such capacity-achieving schemes drops to zero in the presence of any such additional disturbance. As a consequence, the relevance of characterizing the robust (i.e., in the presence of disturbances) feedback capacity of Gaussian channels, which appears to be a fairly unexplored problem, becomes evident.
1.2. Paper Outline
The remainder of this paper begins with some necessary definitions and preliminary results in Section 2. It continues with our detailed exposition in Section 3 of why Shannon’s reasoning fails to yield the right expression for the entropy gain. We present an intuitive discussion leading to the definition of effective differential entropy in Section 4, which is ended by the proof of Theorem 3. Section 5 gives a geometric interpretation of how an arbitrarily small additive perturbation is able to boost the differential entropy rate of the process coming out of an NMP LTI filter. This exposition helps understanding and justifies the introduction of entropy-balanced random processes, which are also characterized there. Section 6 and Section 7 contain our results for the entropy gain produced by an output disturbance and a random initial state, respectively. Our illustrative application results are presented in Section 8, followed by our conclusions in Section 9. Except when presented right after a statement or in its own section, all proofs are given in Appendix B.
2. Preliminaries
2.1. Notation
The sets of natural, real and complex numbers are denoted , , and , respectively. For a complex x, is the real part of x. For a set , the indicator function equals 1 if and 0 otherwise. For any LTI system G, the transfer function corresponds to the z-transform of the impulse response , i.e., . For a transfer function , we denote by the lower triangular Toeplitz matrix having as its first column. We write as a shorthand for the sequence , and, when convenient, we write in vector form as , where denotes transposition. Random scalars (vectors) are denoted using non-italic characters, such as x (non-italic and boldface characters, such as ). The notation means and y are independent. If x and z are conditionally independent given y, we write . For matrices, we use upper-case boldface symbols, such as . We write to denote the i-th eigenvalue of sorted in increasing magnitude. If , is its conjugate transpose, and , if , and , if . We define and . The term denotes the entry in the intersection between the i-th row and the j-th column. If , then and denote the transpose and conjugate transpose of , respectively. We write , with , to refer to the matrix formed by selecting the rows to of . Likewise, for , is the matrix built with columns to of . The expression corresponds to the square sub-matrix along the main diagonal of , with its top-left and bottom-right corners on and , respectively. A diagonal matrix whose entries are the elements in a set (wherein elements may be repeated) is denoted as . If and , we write to denote the augmented matrix built by placing the columns of followed by those of .
2.2. Mutual Information and Differential Entropy
Let , y, and z be random variables with joint PDF , and marginal PDFs , , and , respectively. The mutual information between x and y is defined as . The conditional mutual information between x and y given z is defined as , where is the joint PDF of x and y given z, and , are defined likewise. The conditional differential entropy of x given y is defined as .
From these definitions, it is easy to verify the following properties Reference [1], Sections 2.4–2.6 and 8.4–8.6:
- Shift invariance: for every deterministic function f,
- Non-negativity:with equality if and only if x and y are independent.
- Chain Rule:
- Relationship with entropy:
2.3. System Model and Assumptions
Consider the discrete-time system depicted in Figure 1. In this setup, the block G satisfies Assumption 1.
It is worth noting that there is no loss of generality in considering , since one can otherwise write as ; thus, the entropy gain introduced by would be plus the entropy gain due to (in agreement with (6)), which has an impulse response with its first sample equal to 1.
The following assumption is made about the output disturbance :
Assumption 2.
The disturbance is independent of and belongs to a κ-dimensional linear subspace, for some finite . This subspace is spanned by the κ orthonormal columns of a matrix (where stands for the countably infinite size of ), such that . Moreover, , where the random vector has finite differential entropy, its covariance matrix satisfies , and it is independent of .
3. Revisiting Theorem 14 in Reference Shannon et al.
In this section, after presenting the proof of Theorem 2, we develop Shannon’s approach into a more detailed and formal exposition. This allows us to explain why, for part of the continuous-time filters considered in Theorem 2, the approach chosen by Shannon to prove Theorem 14 in Reference [2] is unable to predict the correct value for the entropy gain.
3.1. Proof of Theorem 2
To begin with, the Fourier transform of is
It is easy to verify that the functions satisfy the following orthogonality property:
and
Notice that , .
The output of sampled at time , , is
with for . This means that the output samples are the discrete-time convolution between and the filter coefficients . Therefore, the matrix relation (4) holds. We then obtain that .
The frequency response of is given by
where is in [Hz]. This means that
where the last equality holds because is conjugate symmetric. Thus, the entropy gain introduced by is the right-hand side of (13), concluding the proof. □
3.2. Formalizing Shannon’s Argument
In the approach followed by Shannon, it is argued that the entropy gain is the limit as of over uniformly spaced frequencies . Here, we show that this summation corresponds to , where is an n-by-n Toeplitz circulant matrix. Moreover, the sequences of Hermitian matrices and are asymptotically equivalent (as defined in Reference [18], Section 2.3), which would yield if the eigenvalues of were bounded between constants for all . However, if (the z-transform of ) has NMP zeros, then has eigenvalues tending to zero exponentially as , which precludes these two limits to coincide.
To prove the above claims, we first apply the change of variable , with which (30) becomes
where is the frequency response of the discrete-time filter G with unit-impulse response and is in radians per second. Now, following Shannon’s approach, we uniformly sample at n frequencies
which, from (32), yields the spectral samples
We will cast the reason why (3) fails to coincide with the correct expression for the entropy gain provided by (5) as a disagreement between the asymptotic behavior of the logarithm of the determinant of two sequences of asymptotically equivalent matrices. For that purpose, since (34) coincides with Reference [18], Equation 4.34, we have that the spectral samples are the eigenvalues of the Toeplitz circulant matrix (Reference [18], Chapter 3)
where is the n-point discrete Fourier transform (DFT) matrix, defined as
From Reference [18], Lemma 4.5, , corresponding to the (possibly) aliased impulse response as a result of sampling in frequency.
We can now see that the discrepancy between the entropy gain predicted by (3) and (5) is the disagreement between the following limits:
where, due to (8), the expressions on both right-hand sides differ if and only if has NMP zeros. According to Reference [18], Lemma 4.6, the sequences and are asymptotically equivalent, which is written as . Then, from Reference [18], Theorem 2.1, the Hermitian matrices , which, from Reference [18], Theorem 2.4, implies that
for any function f continuous over a finite interval such that
However, when has m NMP zeros, Lemma 7 (in Section 6.3) establishes that there are exactly m eigenvalues of that tend to zero exponentially as . Crucially, is discontinuous at 0, which precludes the limits in (37) from coinciding.
4. The Effective Differential Entropy
Theorem 3 establishes that the effective differential entropy rate of the entire or complete output of an LTI system exceeds that of the (shorter) input sequence by the RHS of (15). This section provides a geometrical interpretation of this problem and intuition about the effective differential entropy already introduced in Definition 1.
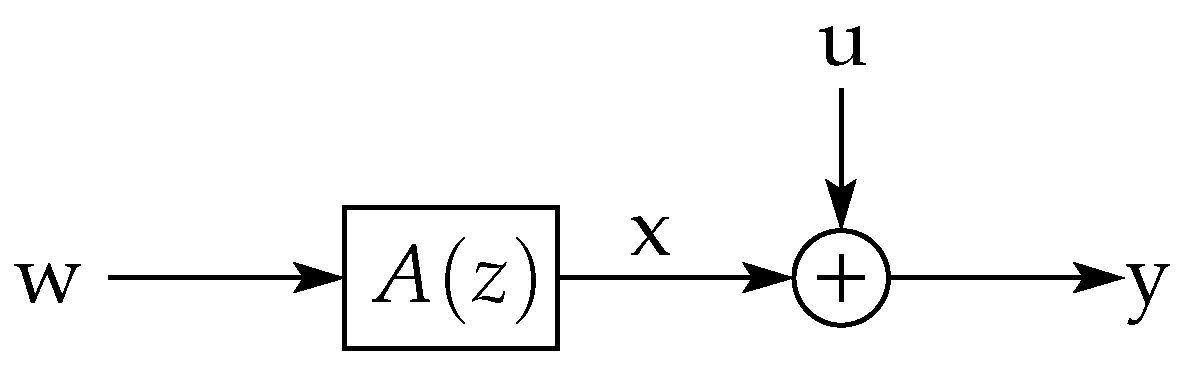
Consider the random vectors and related via
Suppose is uniformly distributed over . Applying the conventional definition of differential entropy of a random sequence, we would have that
because is a deterministic function of and :
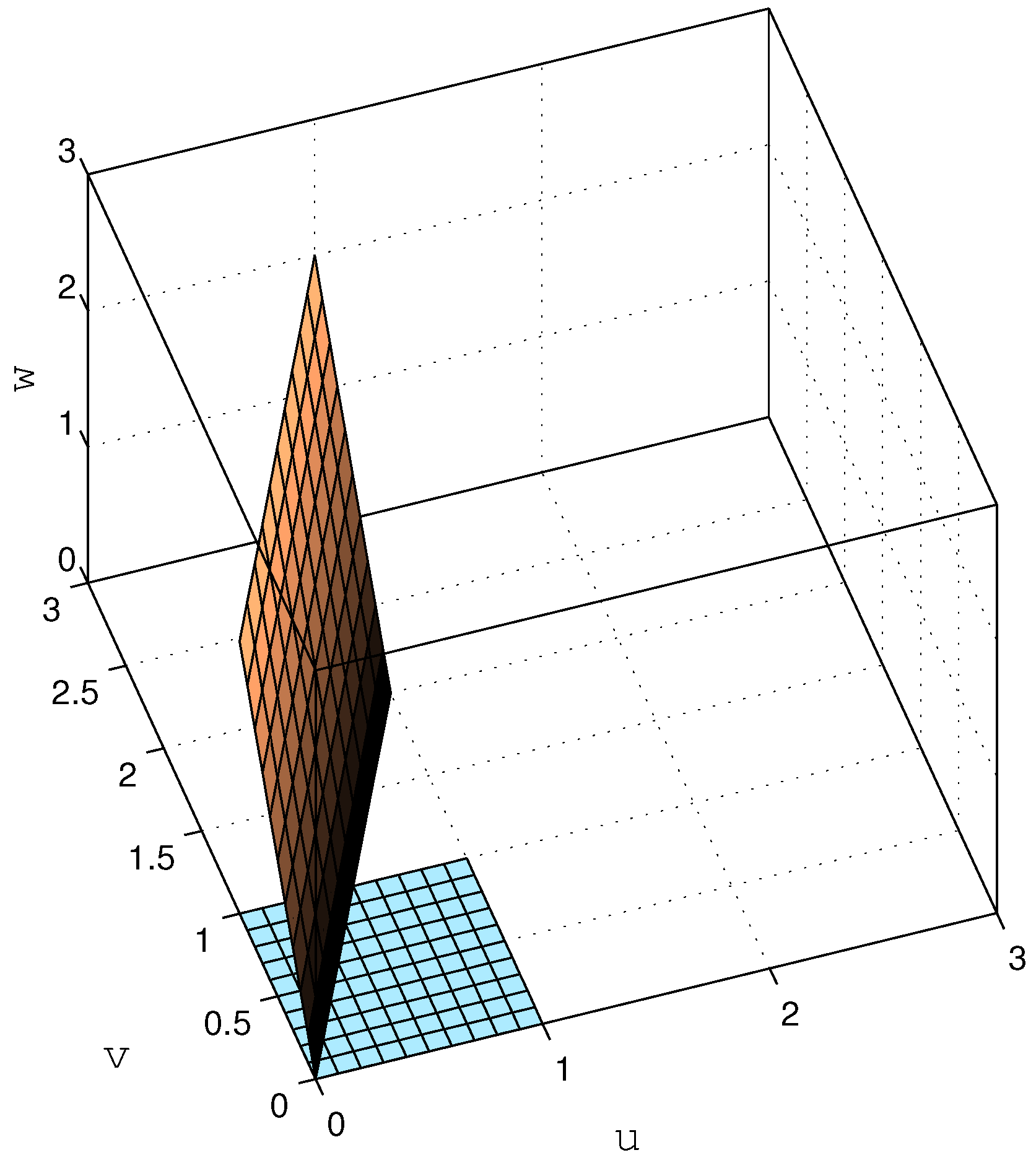
In other words, the problem lies in that, although the output is a three-dimensional vector, it only has two degrees of freedom, i.e., it is restricted to a 2-dimensional subspace of . This is illustrated in Figure 2, where the set is shown (coinciding with the u-v plane), together with its image through (as defined in (40)).
As can be seen in this figure, the image of the square through is a 2-dimensional rhombus over which distributes uniformly. Since the intuitive notion of differential entropy of an ensemble of random variables relates to the size of the region spanned by the associated random vector (and determines how difficult it is to compress it in a lossy fashion with a given precision), one could argue that the differential entropy of , far from being , should be somewhat larger than that of (since the rhombus has a larger area than ). So, what does it mean that (and why should) ? Simply put, the differential entropy relates to the volume spanned by the support of the probability density function. For in our example, the latter (three-dimensional) volume is clearly zero.
From the above discussion, the comparison between the differential entries of and of our previous example should take into account that actually lives in a two-dimensional subspace of . Indeed, since the multiplication by a unitary matrix does not alter differential entries, we could consider the differential entropy of
where is the matrix with orthonormal rows in the SVD of
and is a unit-norm vector orthogonal to the rows of (and thus orthogonal to , as well). We are now able to compute the differential entropy in for , corresponding to the rotated version of such that its support is now aligned with .
The preceding discussion motivates the use of a modified version of the notion of differential entropy for a random vector which considers the number of dimensions actually spanned by instead of its length.
It is worth mentioning that Shannon’s differential entropy of a vector , whose support’s ℓ-volume is greater than zero, arises from considering it as the difference between its (absolute) entropy and that of a random variable uniformly distributed over an ℓ-dimensional, unit-volume region of . More precisely, if in this case the probability density function (PDF) of is Riemann integrable, then [1], Thm. 9.3.1,
where is the discrete-valued random vector resulting when is quantized using an ℓ-dimensional uniform quantizer with ℓ-cubic quantization cells with volume . However, if we consider a variable whose support belongs to an n-dimensional subspace of , (i.e., , as in Definition 1), then the entropy of its quantized version in , say , is distinct from , the entropy of in . Moreover, it turns out that, in general,
despite the fact that has orthonormal rows. Thus, the definition given by (44) does not yield consistent results for the case wherein a random vector has a support’s dimension (i.e., its number of degrees of freedom) smaller that its length (The mentioned inconsistency refers to (45).), which reveals that the asymptotic behavior changes if is rotated. (If this were not the case, then we could redefine (44) replacing ℓ by n, in a spirit similar to the one behind Renyi’s d-dimensional entropy [19].) To see this, consider the case in which distributes uniformly over and . Clearly, distributes uniformly over the unit-length segment connecting the origin with the point . Then,
On the other hand, since, in this case, , we have that
Thus, the d-dimensional entropy would not generally be equal to the effective differential entropy, that is:
The latter example further illustrates why the notion of effective entropy is appropriate in the setup considered in this section, where the effective dimension of the random sequences does not coincide with their length (it is easy to verify that the effective entropy of does not change if one rotates in ).
We finish this section with an example to illustrate the usefulness of the notion of effective differential entropy beyond the context of entropy gain.
Application Example: Shannon Lower Bound
The rate-distortion function (RDF) is the infimum, among all codes, of the expected number of bits per sample necessary to reconstruct a given random source with distortion not greater than D [1]. Let the source and reconstruction be the vectors and , respectively, and suppose the distortion is assessed using the mean-squared error (MSE) . Then, restricting our attention to uniquely-decodable codes Reference [1], p. 105), the Shannon Lower Bound (SLB) [20] establishes that
provided is bounded. Therefore, if is the entire forced response of an FIR filter G of order p to an input , then and is minus infinity, which precludes one from using (49). We will show next that, in this case, the SLB can still be stated by using the effective differential entropy instead of . Following Definition 1, we can write the source vector as , where has orthonormal rows, is diagonal with non-negative entries, and is unitary. Let be a unitary matrix, which means that . Then,
where stems from Reference [1], Theorems 5.4.1 and 5.5.1 and Equations (10).58-10.61, holds because conditioning does not increase entropy and is from the definition of effective differential entropy.
5. Entropy-Balanced Processes: Geometric Interpretation and Properties
In the first part of this section, we provide a geometric interpretation of the effect that a non-minimum phase LTI system has on its input random process. This will give an intuitive meaning to the notion of an entropy-balanced random process (introduced in Definition 2 above) and provide insights into why and how the entropy gain defined in (1) arises as a consequence of an output random disturbance or a random initial state (the themes of Section 6 and Section 7, respectively).
The second part of this section identifies several entropy-balanced processes and establishes two properties satisfied by this class of processes.
5.1. Geometric Interpretation
We begin our discussion with a simple example.
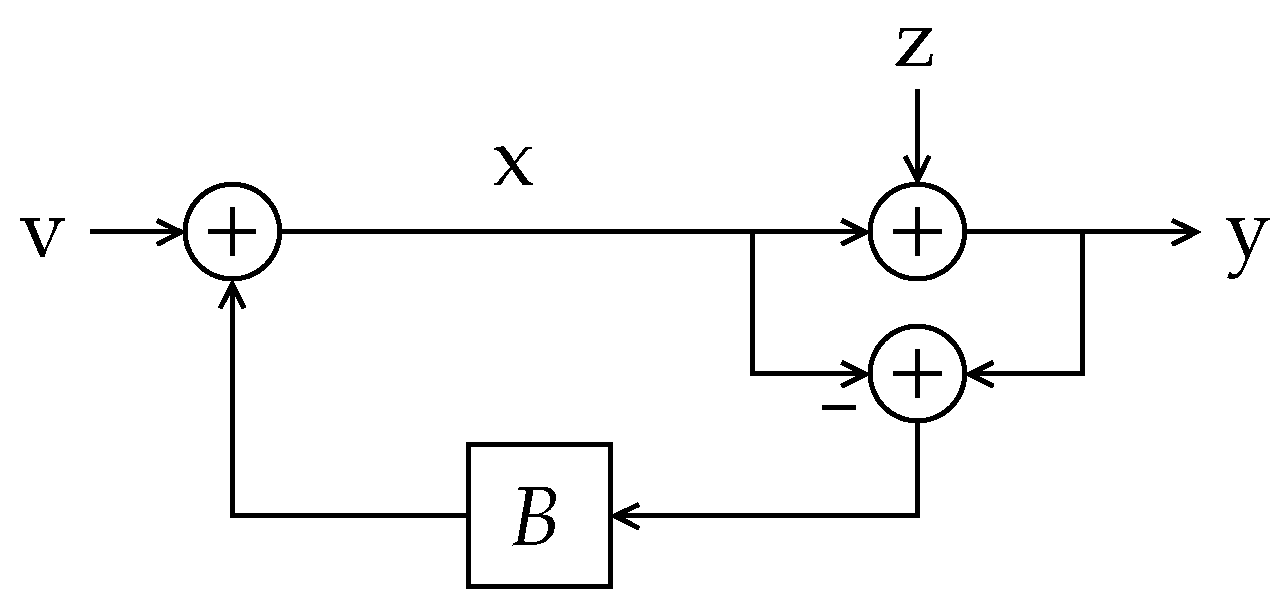
Example 1.
Suppose that G in Figure 1 is a finite impulse response (FIR) filter with impulse response . Notice that this choice yields ; thus, has one non-minimum phase zero, at . The associated matrix for is
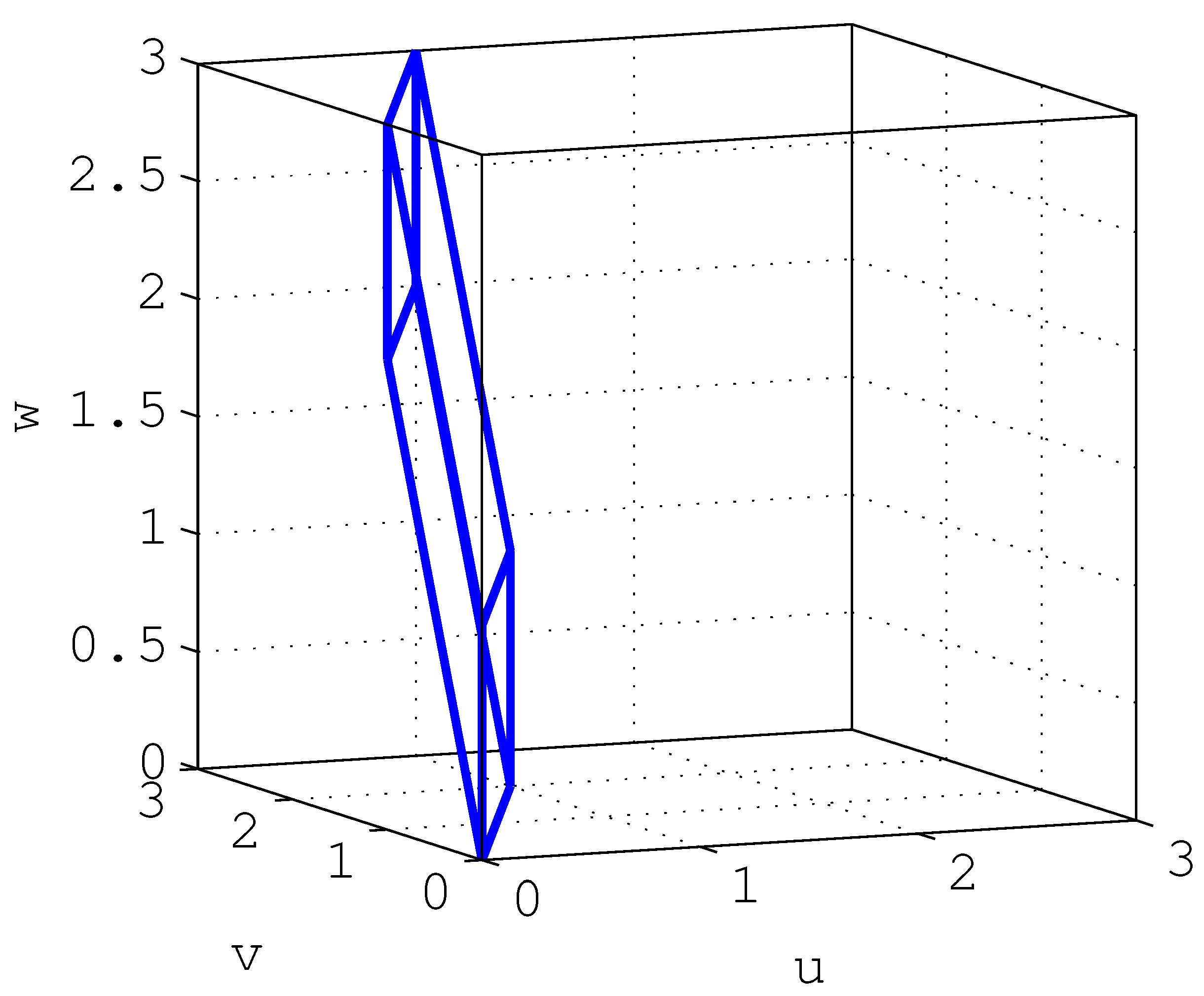
whose determinant is clearly one (indeed, all its eigenvalues are 1). Hence, as discussed in the introduction, ; thus, (and , in general) does not introduce an entropy gain by itself. However, an interesting phenomenon becomes evident by looking at the SVD of , given by , where and are unitary matrices, and . In this case, ; thus, one of the singular values of is much smaller than the others (although the product of all singular values yields 1, as expected). As will be shown in Section 6, for a stable , such uneven distribution of singular values arises only when has non-minimum phase zeros. The effect of this can be visualized by looking at the image of the cube through , shown in Figure 3.
If the input were uniformly distributed over this cube (of unit volume), then would distribute uniformly over the unit-volume parallelepiped depicted in Figure 3; hence, .
Now, if we add to a disturbance , with scalar s uniformly distributed over independent of , and with , the effect would be to “thicken” the support over which the resulting random vector is distributed, along the direction pointed by . If is aligned with the direction along which the support of is thinnest (given by , the first row of ), then the resulting support would have its volume significantly increased, which can be associated with a large increase in the differential entropy of with respect to . Indeed, a relatively small variance of s and an approximately aligned would still produce a significant entropy gain.
The above example suggests that the entropy gain from to appears as a combination of two factors. The first of these is the uneven way in which the random vector is distributed over . The second factor is the alignment of the disturbance vector with respect to the span of the subset of columns of , associated with the smallest singular values of , indexed by the elements in the set . As we shall discuss in the next section, if G has m non-minimum phase zeros, then, as n increases, there will be m singular values of going to zero exponentially. Since the product of the singular values of equals 1 for all n, it follows that must grow exponentially with n, where is the i-th diagonal entry of . This implies that expands with n along the span of , compensating its shrinkage along the span of , thus keeping for all n. Thus, as n grows, any small disturbance distributed over the span of , added to , will keep the support of the resulting distribution from shrinking along this subspace. Consequently, the expansion of with n along the span of is no longer compensated, yielding an entropy increase proportional to .
The above analysis allows one to anticipate a situation in which no entropy gain would take place even when some singular values of tend to zero as . Since the increase in entropy is made possible by the fact that, as n grows, the support of the distribution of shrinks along the span of , no such entropy gain should arise if the support of the distribution of the input expands accordingly along the directions pointed by the rows of .
An example of such situation can be easily constructed as follows: Let in Figure 1 have non-minimum phase zeros and suppose that is generated as , where is an i.i.d. random process with bounded entropy rate. Since the determinant of equals 1 for all n, we have that , for all n. On the other hand, . Since for some finite (recall Assumption 2), it is easy to show that ; thus, no entropy gain appears.
The preceding discussion reveals that the entropy gain produced by G in the situation shown in Figure 1 depends on the distribution of the input and on the support and distribution of the disturbance. This stands in stark contrast with the well known fact that the increase in differential entropy produced by an invertible linear operator depends only on its Jacobian, and not on the statistics of the input [2]. We have also seen that the distribution of a random process along the different directions within the Euclidean space which contains it plays a key role, as well. This motivates the need to specify a class of random processes which distribute more or less evenly over all directions. This is precisely the intuitive meaning of an entropy-balanced process.
The following section identifies a large family of processes belonging to this class, as well as two properties which greatly expands this family.
5.2. Characterization of Entropy-Balanced Processes
We have defined the notion of an “entropy-balanced” process in Section 1.1. In words, the first condition in this definition allows one to guarantee that the orthogonal projection of an entropy-balanced process onto any -dimensional linear subspace has a differential entropy whose magnitude remains bounded or grows at most sub-linearly with n. The second condition states that the projection of an entropy-balanced process onto any linear subspaces having fewer dimensions has the same differential entropy rate as the original process. This condition is equivalent to requiring that every unitary transformation on yields a random sequence such that . This property of the resulting random sequence means that one cannot predict its last samples with arbitrary accuracy by using its previous samples, even if n goes to infinity.
We now characterize a large family of entropy-balanced random processes and establish some of their properties. Although intuition may suggest that most random processes (such as i.i.d. or stationary processes) should be entropy balanced, that statement seems rather difficult to prove. In the following, we show that the entropy-balanced condition is met by i.i.d. processes with per-sample probability density function (PDF) being uniform, piece-wise constant or Gaussian. It is also shown that adding to an entropy-balanced process an independent random processes independent of the former yields another entropy-balanced process, and that filtering an entropy-balanced process by a stable and minimum phase filter yields an entropy-balanced process, as well. The proofs can be found in Appendix B.
Lemma 1.
Let be a Gaussian random process with independent elements having positive and bounded variance, i.e., there exist such that , . Then, is entropy balanced.
Lemma 2.
Let be a random process with independent elements satisfying Condition i) in Definition 2, in which each is distributed according to a (possibly different) piece-wise constant PDF such that each interval where this PDF is constant has measure less than θ and greater than ϵ, for some constants . Then, is entropy balanced.
Lemma 3.
Let and be mutually independent random processes. If is entropy balanced, and satisfies for finite n and , then is also entropy balanced.
The proof of Lemma 3 is on page 33. The working behind this lemma can be interpreted intuitively by noting that adding to a random process another independent random process can only increase the “spread” of the distribution of the former, which tends to balance the entropy of the resulting process along all dimensions in Euclidean space. In addition, it follows from Lemma 3 that all i.i.d. processes having a per-sample PDF which can be constructed by convolving uniform, piece-wise constant or Gaussian PDFs as many times as required are entropy balanced. It also implies that one can have non-stationary processes which are entropy balanced, since Lemma 3 imposes no requirements for the process .
The next lemma related to the properties of entropy-balanced processes shows that filtering by a stable and minimum phase LTI filter preserves the entropy balanced condition of its input.
Lemma 4.
Let be an entropy-balanced process and G an LTI stable and minimum-phase filter. Then, the output is also an entropy-balanced process.
This result implies that any stable moving-average auto-regressive process constructed from entropy-balanced innovations is also entropy balanced, provided the coefficients of the averaging and regression correspond to a stable MP filter.
The last lemma of this section states a crucial property of entropy-balanced processes (the proof is in Appendix B, page 34).
Lemma 5.
Let be an entropy balanced process. Consider a disturbance satisfying Assumption 2 and define . Then, .
We finish this section by pointing out two examples of processes which are non-entropy-balanced, namely the output of a NMP-filter to an entropy-balanced input and the output of an unstable filter to an entropy-balanced input. The first of these cases plays a central role in the next section.
6. Entropy Gain Due to External Disturbances
In this section, we formalize the ideas which were qualitatively outlined in the previous section. Specifically, for the system shown in Figure 1 we will characterize the entropy gain defined in (1) for the case in which the initial state is zero (or deterministic) and there exists a random disturbance of (possibly infinite length) which satisfies Assumption 2.
6.1. Input Disturbances Do Not Produce Entropy Gain
In this section, we show that random disturbances satisfying Assumption 2, when added to the input (i.e., before G), do not introduce entropy gain. This result can be obtained from Lemma 6, as stated in the following theorem:
Theorem 5
(Input Disturbances do not Introduce Entropy Gain). Let G and satisfy Assumptions 1 and 2, respectively. Suppose that is entropy balanced and consider the output
Then,
Proof.
From Lemma 5, the differential entropy rate of equals that of . The proof is completed by recalling that G yields no entropy gain for its input because it corresponds to the noise-less scenario. □
6.2. The Entropy Gain Introduced by Output Disturbances when G is MP is Zero
The results from the previous section yield the following corollary, which states that an LTI system with transfer function without zeros outside the unit circle (i.e., an MP transfer function) cannot introduce entropy gain.
Corollary 1
(Minimum Phase Filters do not Introduce Entropy Gain). Consider the system shown in Figure 1 wherein the input is an entropy-balanced random process and the output disturbance satisfies Assumption 2. Besides Assumption 1, suppose that is minimum phase. Then,
Proof.
Since is minimum phase and stable, the result follows directly from Lemmas 4 and 5. □
6.3. The Entropy Gain Introduced by Output Disturbances when is NMP
We show here that the entropy gain of an LTI system with transfer function and an output disturbance is at most the sum of the logarithm of the magnitude of the zeros of outside the unit circle.
The following lemma will be instrumental for that purpose.
Lemma 6.
Consider the system in Figure 1, and suppose satisfies Assumption 2, and that the input process is entropy balanced. Let be the SVD of , where are the singular values of , with , such that . Let m be the number of these singular values which tend to zero exponentially as . Then,
The proof of this lemma can be found on page 34, in Appendix B.
Lemma 6 leaves the need to characterize the asymptotic behavior of the singular values of . This is accomplished in the following lemma, which relates these singular values to the zeros of . It is a generalization of the unnumbered lemma in the proof of Reference [16], Theorem 1 (restated in Appendix C as Lemma A3), which holds for FIR transfer functions, to the case of infinite-impulse response (IIR) transfer functions (i.e., transfer functions having poles).
Lemma 7.
For a transfer function satisfying Assumption 1, where its zeros satisfy . Then,
where the elements in the sequence are positive and increase or decrease at most polynomially with n.
(The proof of this lemma can be found in Appendix B, page 36).
Lemma 6 also precisely formulates the geometric idea outlined in Section 5.1. To see this, notice that no entropy gain is obtained if the output disturbance vector becomes orthogonal (with probability 1) to the space spanned by the first m columns of sufficiently fast as . Recalling from Assumption 2 that
where the matrix has orthonormal columns of infinite length, such orthogonality condition can be formally stated by defining
as .
If this were the case, then the disturbance would not be able fill the subspace along which is shrinking exponentially. Indeed, if for all n, then , and the latter sum cancels out the one on the RHS of (64), while since is entropy balanced. On the contrary (and loosely speaking), if the projection of the support of onto the subspace spanned by the first m rows of is of dimension m (i.e., if ) for all n, then remains bounded for all n, and the entropy limit of the sum on the RHS of (64) yields the largest possible entropy gain. Notice that (because ); thus, this entropy gain stems from the uncompensated expansion of along the space spanned by the rows of . Beyond these extreme cases (i.e., for general values of and ), the following theorem provides tight bounds on the entropy gain.
Theorem 6.
In the system of Figure 1, suppose that is entropy balanced, and that and satisfy Assumptions 1 and 2, respectively, where the zeros of satisfy . For each , let be the unitary matrix holding the left singular vectors of (as in Lemma 6), where is as defined in (4).
- 1.
- Then,The bounds on both extremes are tight. Moreover, the lower bound is reached if .
- 2.
- If , thenThus, the rightmost upper bound in (70) is achieved if .
Proof.
See Appendix B, page 37. □
The next technical result is very useful for finding conditions under which the requirements of point 2 in Theorem 6 are satisfied (the proof is in Appendix B, page 39).
Lemma 8.
Let F be an FIR LTI causal system of order m such that the m zeros of are NMP, and be an SVD for , for every . For each , define
and . Then,
and .
Now, we can prove Theorem 4.
6.4. Proof of Theorem 4
Factorize as , where is stable and minimum phase and is a stable FIR transfer function with all the m non-minimum-phase zeros of . Letting , we have that , , and that is entropy balanced (from Lemma 4). Thus,
This means that the entropy gain of G due to the output disturbance corresponds to the entropy gain of F due to the same output disturbance.
Clearly, , , and satisfy the assumptions of Theorem 6 with (see Assumption 2). Therefore,
7. Entropy Gain Due to a Random Initial State
Here, we analyze the scenario illustrated by Figure 1 for the case in which there exists a random initial state independent of the input , and zero (or deterministic) output disturbance.
The treatment of an initial state of the LTI system G requires one to first define an internal model for it. For this purpose, in this section, we consider the state-space realization of G in the Kalman canonical form, given by
(see, e.g., Reference [21] or Reference [22], Chapter 6) where the column state vectors , , , are, respectively, controllable and observable, non-controllable and observable, controllable and non-observable, and non-controllable and non-observable. There is no loss of generality in choosing this state-space representation, because every state-space representation consistent with a rational transfer function can be written in this form (Reference [22], Theorem 6.7).
Since our interest is on the effect of the random initial state of G on its output, we only need to consider the observable subsystem within (76) and without its input, given by
where is the natural response of G to its initial state and and . We shall decompose as
where and are the natural responses of G to initial states and , respectively. The natural response component can be generated by the following minimal state-space representation of , without the effect of its input u:
Now, we can state and prove the main result of this section:
Theorem 7.
Suppose G satisfies Assumption 1 and is entropy balanced. Assume that (the observable part of the initial state of G) is independent of the input , and that . Then,
Proof.
Both G and satisfy the conditions of Theorem 6. Thus, as in its statement, we write , where is stable and minimum phase and is a stable FIR transfer function with only the m non-minimum-phase zeros of .
Defining , we have
and . In addition, the fact that G is stable guarantees that the sample second moment of decays exponentially, which means that satisfies Assumption 2. Thus, the conditions of Lemma 6 are met considering , where now is the SVD for , and . Consequently, the proof would be completed if we can show that . But all the involved variables have bounded variance, while is unitary, has orthonormal rows and the entries of decay exponentially with n. This implies that . Therefore, it is only left to prove that
Recalling (78), let us decompose so that
where , the sequences and , respectively, are the natural responses of and F to the controllable and observable initial state , and is the natural response of G to the non-controllable and observable initial state . Then,
where is from the entropy-power inequality [1] and holds because conditioning does not increase entropy and is a deterministic function of . Let the SVD of be
where is unitary, holds the singular values of and has orthonormal rows. Substituting this SVD into (87) we obtain
This last differential entropy is bounded because and , which implies (thanks to Proposition A1) that , and by the chain rule of entropy,
so because (again from Proposition A1). Thus, in view of (89) and (84), all that remains to prove is that
For that purpose, notice that . Therefore, from Lemma A4 (in Appendix C), it follows that (91) holds if
and
To prove (93), recall that the entries in the diagonal matrix decay exponentially with n. On the other hand, the rows of are orthonormal. Finally, the fact that is stable implies that the columns of have norms which are bounded for all n. These three observations readily yield that (93) holds.
To prove that (92) holds, write the rational transfer function of G (described by (80)) as
where . The coefficients in the numerator of are related to those of and by the convolution
where .
Denote the natural response of F (up to time n) to its initial state (which is a linear function of ) as
Let be the natural response of to its initial state . Following the structure of (80), can be written as
where satisfies (79). Considering the following minimal state-space representation of F
it can be seen that the natural response of F to its own initial state can be written as
But, from (80) and (95),
where , and
![Entropy 23 00947 i001]() therefore,
with for . Therefore,
where and is a lower anti-triangular Toeplitz matrix with along its main anti diagonal.
therefore,
with for . Therefore,
where and is a lower anti-triangular Toeplitz matrix with along its main anti diagonal.

This implies that and
Thus, resuming the reasoning before (94), we have that
It then follows from (110) and Lemma 8 that
Hence, (91) is satisfied. Substituting (91) into (89) and the latter into (84) yields
The proof is completed by invoking Lemma (6). □
Theorem 7 allows us to formalize the effect that the presence or absence of a random initial state has on the entropy gain using arguments similar to those utilized in Section 6.
8. Some Implications
The purpose of this section is to illustrate how the results obtained in the previous section can be applied to other problems. To do so, we present next some of the implications of these results on three different problems previously addressed in the literature, namely finding the rate-distortion function for non-stationary processes, an inequality in networked control theory, and the feedback capacity of Gaussian stationary channels. The common feature in these three problems is that, in all of them, non-minimum phase transfer functions play a role (either explicitly or implicitly).
8.1. Networked Control
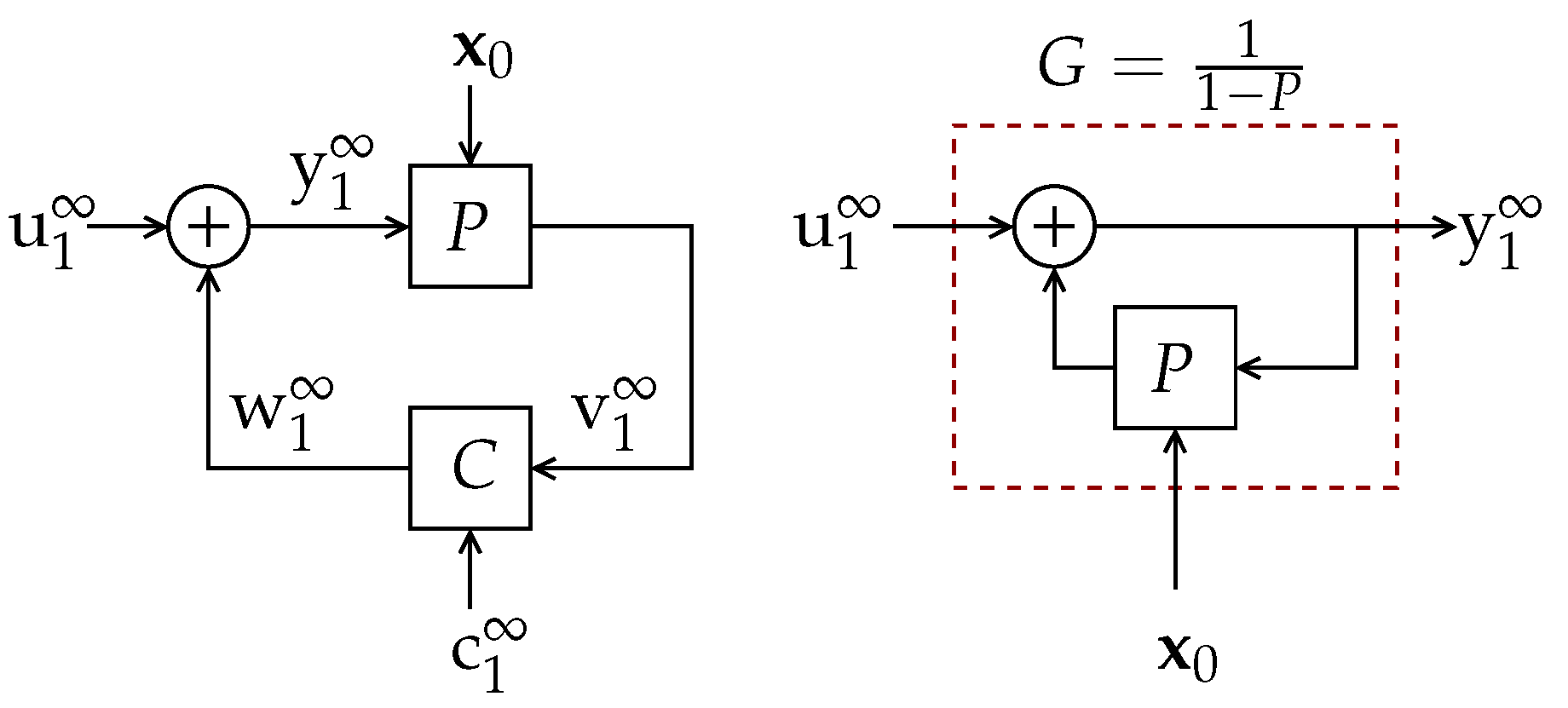
The analysis developed in Reference [13] considers an LTI system P within a noisy feedback loop, as the one depicted in Figure 4. In this scheme, C represents a causal feedback channel which combines the output of P with an exogenous (noise) random process to generate its output. The process is assumed independent of the initial state of P, represented by the random vector , which has finite differential entropy.
For this system, it is shown in Reference [13], Theorem 4.2, that
where is the mutual information (see Reference [1], Section 8.5) between and , with equality if w is a deterministic function of v. Furthermore, it is shown in Reference [12], Lemma 3.2, that, if and the steady state variance of system P remains asymptotically bounded as , then
where are the poles of P. Thus, for the (simplest) case in which , the output is the result of filtering by a filter (as shown in Figure 4 right), and the resulting entropy rate of will exceed that of only if there is a random initial state with bounded differential entropy (see (114a)). Moreover, if and is stable, (114) (as well as Reference [13], Lemma 4.3) implies that this entropy gain is lower bounded by the right-hand side (RHS) of (8), which is greater than zero if and only if G is NMP. However, both [12,13] do not provide conditions under which this lower bound is reached.
In Reference [14], Theorem 14, it is shown that, when there is perfect feedback (i.e., when ), as in Figure 4 right, with P being the concatenation of a stabilizing LTI controller and an LTI plant, and assuming is Gaussian i.i.d. and a Gaussian initial state, then
Notice that this implies reaching equality in both (114a) and (114b).
By using the results obtained in Section 7 we show next that equality holds in (114b) provided the feedback channel satisfies the following assumption:
Assumption 3.
- 1.
- A and B are stable rational transfer functions such that is biproper, has the same unstable poles as P, and the feedback stabilizes the plant P.
- 2.
- F is any (possibly non-linear) operator such that has finite variance for finite n, , and
- 3.
- .
We also extend Reference [14], Theorem 14, to situations including a feedback channel satisfying Assumption 3. For the perfect-feedback case, this extends the validity of (115) to a much larger class of distributions for .
An illustration of the class of feedback channels satisfying this assumption is depicted on top of Figure 5. Trivial examples of channels satisfying Assumption 5 are a Gaussian additive channel preceded and followed by linear operators [23]. Indeed, when F is an LTI system with a strictly causal transfer function, the feedback channel that satisfies Assumption 3 is widely known as a noise shaper with input pre and post filter, used in, e.g., References [24,25,26,27].
Theorem 8.
In the networked control system of Figure 4, suppose that the feedback channel satisfies Assumption 3, that the plant has poles , and that the input is entropy balanced. If the random initial states of and P, namely and , respectively, are independent, have finite variance and , then
Proof.
Let and . We will first show that the output can be written as
where is the stable LTI system with biproper and MP transfer function
with , and being the random initial states of T, G, and , respectively, and
(see Figure 5 bottom). The matrices and . From Figure 5, it is clear that the transfer function from to y is , validating the first term on the RHS of (118). In addition, it is evident that the initial state of is a linear combination of and , justifying the term as the natural response of . Thus, it is only left to prove that the initial state of G is . For that purpose, let and . Define the following variables:
Then, the recursion corresponding to is
This reveals that the initial state of corresponds to
But, from (121), o is also the output of to the input , and
which means that the initial state of G is .
Now, using (118), we have that
where the first equality is because and . The last equality holds since the first sample of the unit-impulse response of G is 1. Since is entropy balanced, is biproper, stable, and MP, and both and have finite variance, it follows from Lemmas 3 and 4 that is entropy balanced, as well. Thus, the proof of the first claim is completed by direct application of Theorem 7.
For the second claim,
where holds because the first sample of the unit-impulse response of is . Then,
where holds because is entropy balanced (from Lemma 4), and has finite variance, allowing us to apply Proposition A3. In turn, follows from (128) and (117a). This completes the proof. □
Remark 2.
If had poles outside the unit circle, then Theorem 8 can still be applied by associating those poles to P.
Remark 3.
Under the conditions of Theorem 8, one has that if either or exists, then the other entropy rate exists too. In that case, if and defining , (117) yields
revealing that the gap in (114a) is exactly . In addition, in the perfect-feedback scenario, Theorem 8 extends the validity of (115) from the Gaussian i.i.d. u and Gaussian considered in Reference [14], Theorem 14, to an entropy-balanced u and an with finite variance and finite differential entropy.
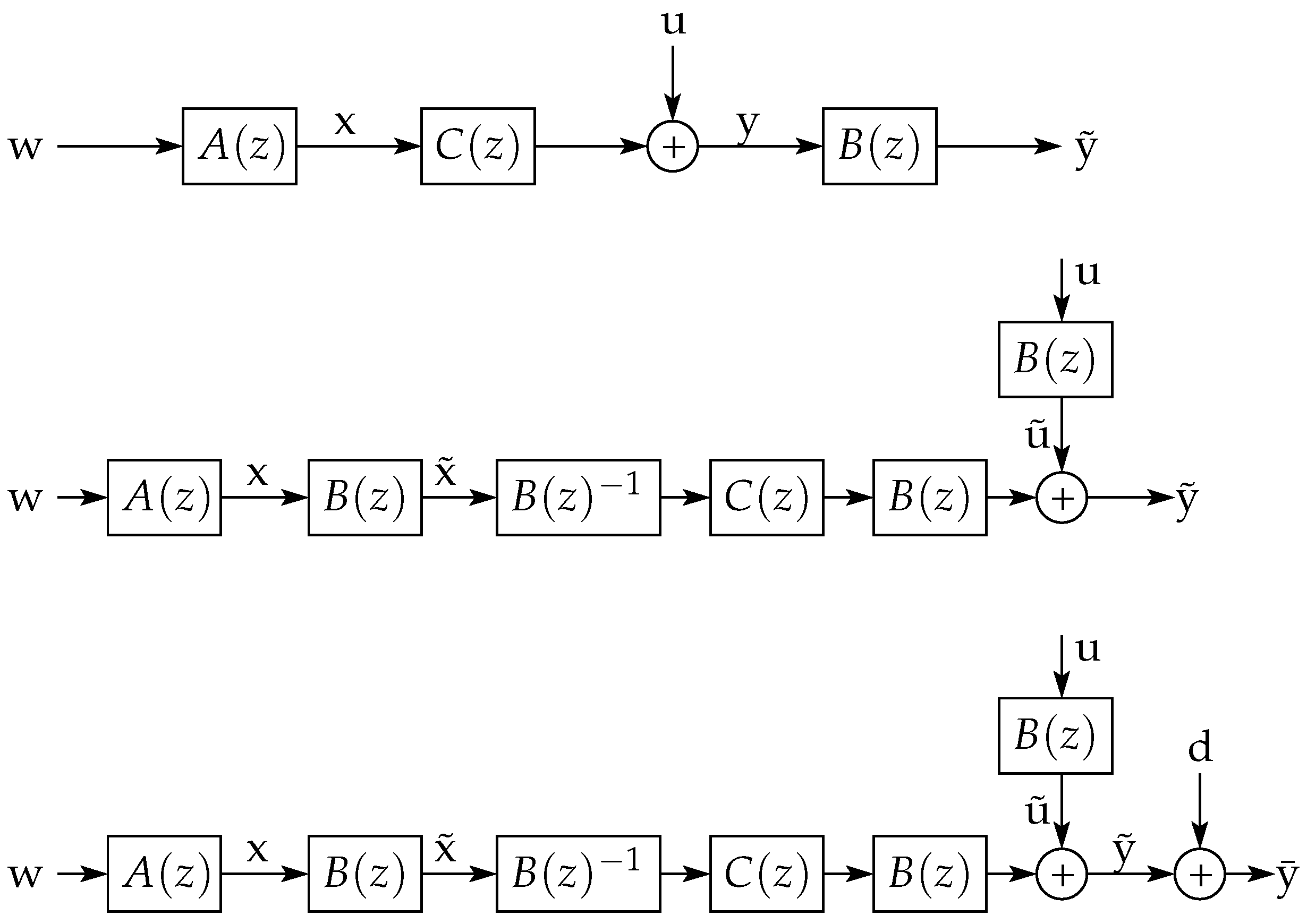
8.2. Rate Distortion Function for Non-Stationary Processes
In this section, we obtain a simpler proof of a result by Gray, Hashimoto and Arimoto [15,16,17], which compares the rate distortion function (RDF) of a non-stationary auto-regressive Gaussian process (of a certain class to be defined shortly) to that of a corresponding stationary version, under MSE distortion. Our proof is based upon the ideas developed in the previous sections, and extends the class of non-stationary sources for which the results in References [15,16,17] are valid.
To be more precise, let and be, respectively, the impulse responses of two linear time-invariant filters A and with rational transfer functions
where , . From these definitions, it is clear that is unstable, is stable, and
Notice also that and ; thus,
Consider the non-stationary random sequence (source) and the asymptotically stationary source generated by passing a stationary Gaussian process through and , respectively, which can be written as
(A block-diagram associated with the construction of x is presented in Figure 6.)
Define the rate-distortion functions for these two sources as
where, for each n, the minima are taken over all the conditional probability density functions and yielding and , respectively.
The above rate-distortion functions have been characterized in References [15,16,17] for the case in which is an i.i.d. Gaussian process. In particular, it is explicitly stated in References [16,17] that, for that case,
We will next provide an alternative and simpler proof of this result, and extend its validity for general (not-necessarily stationary) Gaussian , using the entropy gain properties of non-minimum phase filters established in Section 6. Indeed, the approach in References [15,16,17] is based upon asymptotically-equivalent Toeplitz matrices in terms of the signals’ covariance matrices. This restricts to be Gaussian and i.i.d. and to be an all-pole unstable transfer function, and then, the only non-stationarity allowed is that arising from unstable poles. For instance, a cyclo-stationary innovation followed by an unstable filter would yield a source which cannot be treated using Gray and Hashimoto’s approach. By contrast, the reasoning behind our proof lets be any entropy-balanced Gaussian process with bounded differential entropy rate, and then let the source be , with having unstable poles (and possibly zeros and stable poles, as well).
The statement is as follows:
Theorem 9.
Let be any Gaussian entropy-balanced process with bounded differential entropy rate, and let and be as defined in (138) and (139), respectively. Then, (142) holds.
Thanks to the ideas developed in the previous sections, it is possible to give an intuitive outline of the proof of this theorem (given in Appendix B, page 40) by using a sequence of block diagrams. More precisely, consider the diagrams shown in Figure 7.
In the top diagram in this figure, suppose that realizes the RDF for the non-stationary source x. The sequence u is independent of , and the linear filter is such that the error (a necessary condition for minimum MSE optimality). The filter is the Blaschke product of (see (A83) in Appendix B) (a stable, NMP filter with unit frequency response magnitude such that ).
If one moves the filter towards the source, then the middle diagram in Figure 7 is obtained. By doing this, the stationary source appears with an additive error signal that has the same asymptotic variance as u, reconstructed as . From the invertibility of , it also follows that the mutual information rate between and equals that between x and y. Thus, the channel has the same rate and distortion as the channel .
However, if one now adds a short disturbance d to the error signal (as depicted in the bottom diagram of Figure 7), then the resulting additive error term will be independent of and will have the same asymptotic variance as . Nonetheless, the differential entropy rate of will exceed that of by the RHS of (142). This will make the mutual information rate between and to be less than that between and by the same amount. Hence, is at most . A similar reasoning can be followed to prove that .
8.3. The Feedback Channel Capacity of (Non-White) Gaussian Channels
Consider a non-white additive Gaussian channel of the form
where the input x is subject to the power constraint
and is a stationary Gaussian process.
The feedback information capacity of this channel is realized by a Gaussian input x, and is given by
where is the covariance matrix of , and, for every , the input is allowed to depend upon the channel outputs (since there exists a causal, noise-less feedback channel with one-step delay).
In Reference [9], it was shown that if z is an auto-regressive moving-average process of M-th order, then can be achieved by the scheme shown in Figure 8. In this system, B is a strictly causal and stable finite-order filter and is Gaussian with for all and such that is Gaussian with a positive-definite covariance matrix .
Here, we use the ideas developed in Section 6 to show that the information rate achieved by the capacity-achieving scheme proposed in Reference [9] drops to zero if there exists any additive disturbance of length at least M and finite differential entropy affecting the output, no matter how small.
To see this, notice that, in this case, and for all ,
since . From Theorem 4, this gap between differential entries is precisely the entropy gain introduced by to an input when the output is affected by the disturbance . Thus, from Theorem 4, the capacity of this scheme will correspond to , where are the zeros of , which is precisely the result stated in Reference [9], Theorem 4.1.
However, if the output is now affected by an additive disturbance not passing through such that , and , with , then we will have
In this case,
But which follows directly from applying Theorem 4 to each of the differential entries. Notice that this result holds irrespective of how small the power of the disturbance may be.
Thus, the capacity-achieving scheme proposed in Reference [9] (and further studied in Reference [28]), although of groundbreaking theoretical importance, would yield zero rate in any practical situation, since in every physically implemented scheme, signals are unavoidably affected by some amount of noise.
9. Conclusions
We have provided an intuitive explanation and a rigorous characterization of the entropy gain of a linear time-invariant (LTI) system, defined as the difference between the differential entropy rates of its output and input random signals. The continuous-time version of this problem, considered by Shannon in Theorem 14 of his 1948 landmark paper, involves an LTI system band limited to B [Hz]. For this scenario, we restricted our attention to systems such that the samples of its unit-impulse response, taken seconds apart, correspond to the unit-impulse response of a causal and stable discrete-time system G. We show that the entropy gain in this case is , which implies that, for this class of systems, Shannon’s Theorem 14 holds if and only if has a corresponding discrete-time G that is minimum phase (MP).
For the discrete-time case, we introduced a new notion referred to as effective differential entropy, which quantifies the amount of uncertainty in vector signals that are confined to subspaces of lower dimensionality than that of the signals themselves. (Note that this is not possible by the conventional notion of differential entropy, which simply diverges to minus infinity.) It turns out that the difference in effective differential entropy rate between an n-length input to an LTI discrete-time system with frequency response , and its full length output, as n tends to infinity, equals .
When comparing input and output sequences of equal length, our analysis revealed that, in the absence of external random disturbances, the entropy gain of a discrete-time LTI system G with unit-impulse response is simply . An entropy gain greater than can be obtained only if a random signal is added to the output of G and if such output process has statistical properties that make it susceptible to the added random signal. In order to characterize the role of G, its input has been assumed to be entropy balanced (EB), a notion introduced herein. Crucially, the differential entropy rate of an EB process is not susceptible to random signals. EB processes constitute a large family that includes Gaussian processes with bounded, non-vanishing variance. We also show that (i) the sum of an EB process and any bounded variance process is EB, too, and (ii) passing an EB process by a stable MP filter yields an EB process. When the input is EB, we show that if G has NMP zeros , then the largest possible entropy gain is , which equals . This upper bound is achieved by adding a finite-length output disturbance with finite variance and bounded differential entropy if and only if its length is at least m, no matter how tiny its variance may be. The same entropy gain is also obtained if G has a random initial state with bounded differential entropy and finite variance.
We used these fundamental insights about when the entropy gain occurs in order to establish a new and more general proof of the quadratic rate-distortion function for non-stationary Gaussian sources. Moreover, we demonstrated that the information rate of the capacity-achieving scheme proposed in Reference [9] for the auto regressive Gaussian channel with feedback drops to zero in the presence of any additive disturbance in the channel input or output of sufficient (finite) length, no matter how small it may be. This has crucial implications in any physical setup, where noise is unavoidable.
Author Contributions
Conceptualization, M.S.D. and M.M.; Investigation, M.S.D., M.M. and J.Ø.; Writing—original draft, M.S.D.; Writing—review and editing, M.M. and J.Ø. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Comisión Nacional de Investigación Científica y Tecnológica grant number FB0008.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proof of Theorem 3
The total length of the output ℓ, will grow with the length n of the input, if G is FIR, and will be infinite, if G is IIR. Letting be the length of the impulse response of G in the FIR case, we define the output-length function
It is also convenient to define the sequence of matrices , where is Toeplitz with , . This allows one to write the entire output of a causal LTI filter G with impulse response to an input as
Let the SVD of be , where has orthonormal rows, is diagonal with positive elements, and is unitary.
The effective differential entropy of exceeds the differential entropy of by
The determinant of can be related to that of by noticing that
Since is unitary, it follows that , which from (A3) means that
The product is a symmetric Toeplitz matrix, with its first column, , given by
. Thus, the sequence corresponds to the samples 0 to of those resulting from the complete convolution , even when the filter G is IIR, where denotes the time-reversed (possibly infinitely long) response g. Consequently, and since has no zeros on the unit circle, and g is absolutely summable, we can use the Grenander and Szegö’s theorem [29], and Reference [18], Theorem 4.2, to obtain that
Appendix B. Proofs of Results Stated in the Previous Sections
Proof of Lemma 1.
Let be the variance of . Thus, . Let . Then, . As a consequence,
But from the Courant-Fischer theorem [30],
thus, , satisfying Condition ii) in Definition 2. Adding to this the fact that, in this case, for all n, Condition i) in Definition 2 is satisfied, as well, completing the proof. □
Proof of Lemma 2.
Let be the intervals (bins) in where the sample has constant PDF. Define the discrete random process , where if and only if . Let where has orthonormal rows. Then,
where the inequality is due to the fact that and are deterministic functions of ; hence, . Subtracting from (A9) we obtain
Hence,
where the last equality follows from Lemma A1 (in Appendix C) whose conditions are met because, given , the sequence has independent entries each of them distributed uniformly over a possibly different interval with finite and positive measure. The opposite inequality is obtained by following the same steps as in the proof of Lemma A1, from (A124) onwards, which completes the proof. □
Proof of Lemma 3.
Let , where is a unitary matrix and where and have orthonormal rows.
Then,
We can lower bound as follows:
where holds because conditioning does not increase entropy, is from the fact that , and follows from the chain rule of entropy.
Substituting this result into (A14), dividing by n, taking the limit as , and recalling that is entropy balanced, we conclude that .
The opposite bound over can be obtained from
where is a jointly Gaussian sequence with the same second-order moment as . Therefore, . But satisfies the assumptions of Proposition A2; thus, . Therefore, , which substituted in (A14) yields
Hence, satisfies Condition ii) of Definition 2. Since also satisfies Condition i) of Definition 2, it follows that is entropy balanced, completing the proof. □
Proof of Lemma 4.
Pick any and let where is a unitary matrix and the matrices and have orthonormal rows. Since , we have that
Let be the SVD of , where is an orthogonal matrix, has orthonormal rows and is a diagonal matrix with the singular values of .
Hence
The singular values of are , . Now, notice that
and that
Thus, from (A24) and the Cauchy eigenvalue interlacing theorem [30],
Hence,
Recalling that G is minimum phase (which guarantees that its singular values change at most polynomially with n, due to Lemma 7), we conclude that
Substituting back into (A23), we arrive to
where holds because is entropy balanced. This completes the proof. □
Proof of Lemma 5.
Let be a sequence of matrices, each with orthonormal rows spanning a subspace of that contains the span of the columns of . For each , let be such that is a unitary matrix. Then,
Thus,
where the last equality holds because is entropy balanced and is entropy balanced (from Lemma 3). This completes the proof. □
Proof of Lemma 6.
Since is unitary, we have that
where
Thus,
where follows from the chain rule of differential entropy. It only remains to show that the limit of as equals the entropy rate of . We will do this by deriving a lower and an upper bounds which converge to the same expression as .
A lower bound for can be obtained by noticing that
where follows from the fact that conditioning on more information does not increase differential entropy, is due to the fact that , for any constant a, holds because , is a direct application of the chain rule of differential entropy, and stems from (A34) and the fact that . On the other hand,
Then, by inserting (A43) and (A42) in (A37), dividing by n, and taking the limit , we obtain
where the last equality is a consequence of the fact that is entropy balanced (specifically, from Proposition A3).
We now derive an upper bound for . Defining the random vector
and since is diagonal, we can write
where
Therefore,
Notice that, by Assumption 2, and, thus, is restricted to the span of of dimension , for all . Then, for every , one can construct a unitary matrix , with and , such that the rows of span the space spanned by the columns of and such that . Therefore, from (A49),
where and are the covariance matrices of and , respectively, and where the last inequality follows from [31]. The fact that and are upper bounded for all n, and the fact that either grows with n or decreases sub-exponentially (from Lemma 7), imply that
But the fact that implies that . On the other hand, recalling that and noting that has orthonormal rows, reveals that (from the assumption that is entropy balanced). Therefore,
which coincides with the lower bound found in (A45), completing the proof. □
Proof of Lemma 7.
The transfer function can be factored as , where is stable and minimum phase and is stable with all the non-minimum phase zeros of , both being biproper rational functions. From Lemma A2 (in Appendix C), in the limit as , the eigenvalues of are lower and upper bounded by and , respectively, where . Let and be the SVDs of and , respectively, with and being the diagonal entries of the diagonal matrices , , respectively. Then,
Denoting the i-th row of by be, we have that, from the Courant-Fischer theorem [30] that
Likewise,
Thus,
The result now follows directly from Lemma A3 (in Appendix C). □
Proof of Theorem 6.
To obtain the other bounds on the entropy gain of , we will use Lemma 6. Recalling the structure of specified in Assumption 2, the random vector whose differential entropy appears on the RHS of (64) takes the form
Notice that, for every , the columns of the matrix span a space of dimension , with . If (i.e., ), then
If that is that case for every , the lower bound in (70) is reached by inserting the latter expression into (64) and invoking Lemma 7.
Let be an SVD for , where has orthonormal rows,
where are the singular values of , and has orthonormal rows. Construct a unitary matrix such that
where is as before, and has orthonormal rows, and its row span is the orthogonal complement of that of . Thus,
From (A63) and (A60), we obtain
where the indicator function if and 0 otherwise. The first differential entropy on the RHS of (A66) can be lower bounded as
where is from the entropy power inequality [1], holds because and is from Proposition A1. An upper bound can be obtained as
where holds because conditioning does not increase entropy, is because a Gaussian distribution maximizes the differential entropy for a given covariance matrix, and is due to Reference [31]. Notice that satisfies the requirements of Proposition A2, implying that . Thus, since , it follows from (A67), (A68), and (A66) that
For the last differential entropy on the RHS of (A66), notice that . Consider the SVD , with being unitary, being diagonal, and having orthonormal rows. We can then conclude that
Now, the fact that
reveals that
Recalling that and that is unitary, it is easy to show (by using the Courant-Fischer theorem [30]) that
with equality in and if and only if and , respectively. Substituting this into (A71) and then the latter into (A70), we arrive to
Substituting the upper bound from this equation and from (A68) into (A66) and the latter in (64), exploiting the fact that is entropy balanced (which ensures that satisfies Condition i) in Definition 2) and invoking Lemma 7 yields the upper bound in (70).
Proof of Lemma 8.
We will consider first the case and show that , where now is the left unitary matrix in the SVD . We will prove that this is the case by using a contradiction argument. Thus, suppose the contrary, i.e., that
Then, there exists a sequence of unit-norm vectors , with for all n, such that
For each , define the n-length unit-norm image vectors . Then,
where the last equality follows from the fact that, by construction, is in the span of the first m rows of , together with the fact that is unitary (which implies that ). Since the top m entries in decay exponentially as n increases, we have that
where is a finite-order polynomial of n (from Lemma A3, in Appendix C).
Now, notice that is a Toeplitz matrix with the convolution of f and (the impulse response of F and its time-reversed version, respectively) on its first row and column. It then follows from Reference [18], Lemma 4.1, that
(the inequality is strict because all the zeros of are strictly outside the unit disk). Then, we conclude that
Recall that ; thus, from (A75), and , which means that , which contradicts (A77). Therefore,
Proof of Theorem 9.
Denote the Blaschke product [11] of as
which clearly satisfies
where is the first sample in the impulse response of . Notice that (A84) implies that for every sequence of random variables with uniformly bounded variance. Since has only stable poles and its zeros coincide exactly with the poles of , it follows that is an MP stable transfer function. Thus, the asymptotically stationary process defined in (139) can be constructed as
where is a Toeplitz lower triangular matrix with its main diagonal entries equal to . Since is entropy balanced, so is , thanks to Lemma 4.
The fact that is biproper with as in (A85) implies that, for any with finite differential entropy,
which will be utilized next.
For any given , suppose that is chosen and and are distributed so as to minimize subject to the constraint (i.e., is a realization of ), yielding the reconstruction
Since we are considering mean-squared error distortion, it follows that, for rate-distortion optimality, must be jointly Gaussian with . In addition, there is no loss of rate-distortion optimality if is entropy balanced (otherwise, it would have a lower entropy rate than its entropy-balanced counterpart, which differs from the former only on a finite number of samples and has the same asymptotic MSE). From these vectors, define
where is a zero-mean Gaussian vector independent of with finite differential entropy and finite variance such that , . Then, we have that (the change of variables and the steps in this chain of equations is represented by the block diagrams shown in Figure 7)
where follows from being invertible, is due to the fact that , holds because . The equality stems from (see (A87)). Equality holds in because and in because of (A91). But from Theorem 4 and since is entropy balanced, . From Lemma 3 and because is entropy balanced, so is . This guarantees, from Lemma 5, that . Thus, .
At the same time, the distortion for the source when reconstructed as is
where holds because is bounded, and is due to the fact that, in the limit, is a unitary operator. Recalling the definitions of and , we conclude that ; therefore,
In order to complete the proof, it suffices to show that . For this purpose, consider now the (asymptotically) stationary source , and suppose that realizes . Again, and will be jointly Gaussian, satisfying (the latter condition is required for minimum MSE optimality). From this, one can propose an alternative realization in which the error sequence is , yielding an output with . Then,
where follows by recalling that and because , stems from (A87), is a consequence of , follows from the fact that . Finally, holds because is invertible for all n. Since, asymptotically as , the distortion yielded by for the non-stationary source is the same which is obtained when is reconstructed as (recall (A84)), we conclude that , completing the proof. □
Appendix C. Technical Lemmas and Propositions
Proposition A1.
Let the random vector have finite differential entropy, and suppose its covariance matrix satisfies . Then, for any unitary matrix and
Proof.
Define . Since is unitary, it follows that and that and have the same eigenvalues. Therefore,
where holds because a Gaussian distribution yields the largest differential entropy for a given covariance matrix, is from the fact that and is due to the Cauchy interlacing theorem [30]. This proves the upper bound in (A112). For the lower bound, we have
where stems from the fact that and follows from (A113). This completes the proof. □
Proposition A2.
Let be a random process such that the variance of , for finite n, and
Then, . ▲
Proof.
The assumptions on imply that, for every , there exists a finite such that, for every , and . Then,
where holds because , while stems from the fact that, for every , . Thus, for every , , which means that , completing the proof. □
Proposition A3.
Let be an entropy-balanced random process. Then, for each and for every sequence of matrices , with orthonormal rows,
Proof of Proposition A3.
We will first show that
To see this, notice that, for every with orthonormal rows, there exists a matrix with orthonormal rows which are also orthogonal to those of . This means that the matrix is unitary; thus,
where holds due to the chain-rule of differential entropy and follows because conditioning does not increase differential entropy. Therefore, . Dividing this by n, taking the limit when and recalling that satisfies (17) yields (A117).
We will now prove that . For this purpose, let be a jointly Gaussian random process with the same second-order statistics as . Then,
with the inequality due to the fact that has orthonormal rows. But meets the requirements of Proposition A2; thus, . The proof is completed by combining this result with (A117). □
Lemma A1.
Let be a random process with independent elements, and where each element is uniformly distributed over possible different intervals , such that , for some positive and bounded . Then, is entropy balanced.
Proof.
Without loss of generality, we can assume that , for all i (otherwise, we could scale the input by , which would scale the output by the same proportion, increasing the input entropy by and the output entropy by , without changing the result). The input vector is confined to an n-box (the support of ) of volume and has entropy . This support is an n-box which contains k-boxes of different k-volume. Each of these k-boxes is determined by fixing entries in to , and letting the remaining k entries sweep freely over . Thus, the k-volume of each k-box is the product of the k support sizes of the associated selected free-sweeping entries. But recalling that for all i, the volume of each k-box can be upper bounded by . With this, the added volume of all the k-boxes contained in the original n-box can be upper bounded as
We now use this result to upper bound the entropy rate of .
Let where is a unitary matrix and where and have orthonormal rows. From this definition, will distribute over a finite region , corresponding to the projection onto the -dimensional span of the rows of . Hence, is upper bounded by the entropy of a uniformly distributed vector over the same support, i.e., by , where is the -dimensional volume of this support. In turn, is upper bounded by the sum of the volume of all -dimensional boxes contained in the n-box in which is confined, which we already denoted by , and which is upper bounded as in (A120). Therefore,
Recalling that , dividing by n and taking the limit as yields
On the other hand,
where follows because is an orthogonal matrix. Letting correspond to the jointly Gaussian sequence with the same second-order moments as , and recalling that the Gaussian distribution maximizes differential entropy for a given covariance, we obtain the upper bound
where follows since the are independent, and stems from the fact that has orthonormal rows. Since is bounded for all n, we obtain by substituting (A125) into (A124) that . The combination of this with (A123) yields , satisfying Condition ii) in Definition 2. From this, the proof is completed by noting that satisfies Condition i) in Definition 2. This completes the proof. □
Lemma A2.
Let be a causal, finite-order, stable and strictly minimum-phase rational transfer function with impulse response such that . Then, and .
Proof of Lemma A2.
The fact that is upper bounded follows directly from the fact that is a stable transfer function. On the other hand, is positive definite, with . Suppose that . If this were true, then it would hold that . But is the lower triangular Toeplitz matrix associated with , which is stable (since is minimum phase), implying that , thus leading to a contradiction. This completes the proof. □
We re-state here (for completeness and convenience) the unnumbered lemma in the proof of Reference [16], Theorem 1, as follows:
Lemma A3.
Let the transfer function satisfy Assumption 1 and suppose it has no poles. Then,
where the elements in the sequence are positive and increase or decrease at most polynomially with n.
Lemma A4.
Let be matrices with the same dimensions. Then,
Proof.
For every such that ,
where the last inequality holds because and are symmetric and because of the Cauchy-Schwartz inequality. The proof is completed by noting that (A128) holds for the that minimizes , and . □
References
- Cover, T.M.; Thomas, J.A. Elements of Information Theory, 2nd ed.; Wiley-Interscience: Hoboken, NJ, USA, 2006. [Google Scholar]
- Shannon, C.E.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1949. [Google Scholar]
- Itô, H. Principle of the minimum entropy in information theory. Proc. Jpn. Acad. 1953, 29, 194–197. [Google Scholar] [CrossRef]
- O’Neal, J. Bounds on subjective performance measures for source encoding systems. IEEE Trans. Inf. Theory 1971, 17, 224–231. [Google Scholar] [CrossRef]
- Pierobon, M.; Akyildiz, I.F. Capacity of a Diffusion-Based Molecular Communication System With Channel Memory and Molecular Noise. IEEE Trans. Inf. Theory 2013, 59, 942–954. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Pierobon, M.; Balasubramaniam, S. An Information Theoretic Framework to Analyze Molecular Communication Systems Based on Statistical Mechanics. Proc. IEEE 2019, 107, 1230–1255. [Google Scholar] [CrossRef]
- Aaron, M.R.; McDonald, R.A.; Protonotarios, E. Entropy power loss in linear sampled data filters. Proc. IEEE 1967, 55, 1093–1094. [Google Scholar] [CrossRef]
- Papoulis, A.; Pillai, S.U. Probability, Random Variables and Stochastic Processes, 3rd ed.; McGraw-Hill: New York, NY, USA, 1991. [Google Scholar]
- Kim, Y.H. Feedback capacity of stationary Gaussian channels. IEEE Trans. Inf. Theory 2010, 56, 57–85. [Google Scholar] [CrossRef]
- Rudin, W. Real and Complex Analysis; McGraw-Hill: New York, NY, USA, 1987. [Google Scholar]
- Serón, M.M.; Braslavsky, J.H.; Goodwin, G.C. Fundamental Limitations in Filtering and Control; Springer: London, UK, 1997. [Google Scholar]
- Martins, N.C.; Dahleh, M.M.A. Fundamental limitations of performance in the presence of finite capacity feedback. In Proceedings of the 2005, American Control Conference, Portland, OR, USA, 8–10 June 2005. [Google Scholar]
- Martins, N.; Dahleh, M. Feedback control in the presence of noisy Channels: “Bode-like” fundamental limitations of performance. IEEE Trans. Autom. Control 2008, 53, 1604–1615. [Google Scholar] [CrossRef]
- Yu, S.; Mehta, P.G. Bode-Like Fundamental Performance Limitations in Control of Nonlinear Systems. IEEE Trans. Autom. Control 2010, 55, 1390–1405. [Google Scholar] [CrossRef]
- Gray, R.M. Information rates of autorregressive processes. IEEE Trans. Inf. Theory 1970, IT-16, 412–421. [Google Scholar] [CrossRef]
- Hashimoto, T.; Arimoto, S. On the rate-distortion function for the nonstationary Gaussian autoregressive process. IEEE Trans. Inf. Theory 1980, IT-26, 478–480. [Google Scholar] [CrossRef]
- Gray, R.M.; Hashimoto, T. A note on rate-distortion functions for nonstationary Gaussian autoregressive processes. IEEE Trans. Inf. Theory 2008, 54, 1319–1322. [Google Scholar] [CrossRef] [Green Version]
- Gray, R.M. Toeplitz and circulant matrices: A review. Found. Trends Commun. Inf. Theory 2006, 2, 155–239. [Google Scholar] [CrossRef]
- Rényi, A. On the dimension and entropy of probability distributions. Acta Math. Hung. 1959, 10, 193–215. [Google Scholar] [CrossRef]
- Shannon, C. Coding theorems for a discrete source with a fidelity criterion. IRNE Nat. Conv. Rec. 1959, 4, 143–163. [Google Scholar]
- Goodwin, G.C.; Graebe, S.F.; Salgado, M.E. Control System Design, 1st ed.; Prentice Hall PTR: Upper Saddle River, NJ, USA, 2000. [Google Scholar]
- Chen, C.T. Linear System Theorey and Design, 3rd ed.; The Oxford Series in Electrical and Computing Engineering; Oxford University Press: Oxford, UK, 1999. [Google Scholar]
- Elia, N. When Bode meets Shannon: Control-oriented feedback communication schemes. IEEE Trans. Autom. Control 2004, 49, 1477–1488. [Google Scholar] [CrossRef]
- Silva, E.I.; Derpich, M.S.; Østergaard, J. A framework for control system design subject to average data-rate constraints. IEEE Trans. Autom. Control 2011, 56, 1886–1899. [Google Scholar] [CrossRef] [Green Version]
- Silva, E.I.; Derpich, M.S.; Østergaard, J. An achievable data-rate region subject to a stationary performance constraint for LTI plants. IEEE Trans. Autom. Control 2011, 56, 1968–1973. [Google Scholar] [CrossRef] [Green Version]
- Yüksel, S. Characterization of Information Channels for Asymptotic Mean Stationarity and Stochastic Stability of Nonstationary/Unstable Linear Systems. IEEE Trans. Inf. Theory 2012, 58, 6332–6354. [Google Scholar] [CrossRef] [Green Version]
- Freudenberg, J.S.; Middleton, R.H.; Braslavsky, J.H. Minimum Variance Control Over a Gaussian Communication Channel. IRE Trans. Comm. Syst. 2011, 56, 1751–1765. [Google Scholar] [CrossRef] [Green Version]
- Ardestanizadeh, E.; Franceschetti, M. Control-theoretic approach to communication with feedback. IEEE Trans. Autom. Control 2012, 57, 2576–2587. [Google Scholar] [CrossRef]
- Grenander, U.; Szegö, G. Toeplitz Forms and Their Applications; University of California Press: Berkeley, CA, USA, 1958. [Google Scholar]
- Horn, R.A.; Johnson, C.R. Matrix Analysis; Cambridge University Press: Cambridge, UK, 1985. [Google Scholar]
- Fiedler, M. Bounds for the determinant of the sum of Hermitian matrices. Proc. Am. Math. Soc. 1971, 30, 27–31. [Google Scholar] [CrossRef]
Figure 1.
A causal, stable, linear and time-invariant system G with input and output processes, initial state, and output disturbance.
Figure 1.
A causal, stable, linear and time-invariant system G with input and output processes, initial state, and output disturbance.

Figure 2.
Support of (laying in the u-v plane) compared to that of (the rhombus in ).

Figure 3.
Image of the cube through the square matrix with columns , , and .

Figure 4.
(Left): LTI system P within a noisy feedback loop. (Right): equivalent system when the feedback channel is noiseless and has unit gain.
Figure 4.
(Left): LTI system P within a noisy feedback loop. (Right): equivalent system when the feedback channel is noiseless and has unit gain.

Figure 5.
(Top): The class of feedback channels described by Assumption 3. (Bottom): an equivalent form.
Figure 5.
(Top): The class of feedback channels described by Assumption 3. (Bottom): an equivalent form.

Figure 6.
Block diagram representation of how the non-stationary source is built and then reconstructed as .
Figure 6.
Block diagram representation of how the non-stationary source is built and then reconstructed as .

Figure 7.
Block-diagram representation of the changes of variables in the proof of Theorem 9.

Figure 8.
Block diagram representation a non-white Gaussian channel and the coding scheme considered in Reference [9].
Figure 8.
Block diagram representation a non-white Gaussian channel and the coding scheme considered in Reference [9].

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Derpich, M.S.; Müller, M.; Østergaard, J. The Entropy Gain of Linear Systems and Some of Its Implications. Entropy 2021, 23, 947. https://doi.org/10.3390/e23080947
AMA Style
Derpich MS, Müller M, Østergaard J. The Entropy Gain of Linear Systems and Some of Its Implications. Entropy. 2021; 23(8):947. https://doi.org/10.3390/e23080947
Chicago/Turabian StyleDerpich, Milan S., Matias Müller, and Jan Østergaard. 2021. "The Entropy Gain of Linear Systems and Some of Its Implications" Entropy 23, no. 8: 947. https://doi.org/10.3390/e23080947
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.