
I don't think SlateStarCodex readers have an average IQ of 137
I don't think SlateStarCodex readers have an average IQ of 137
It sounds unlikely because it is.

I’m continuing on the same theme as the last post: Coming across something on twitter and then playing around in R-studio for a while.
I saw this post, pictured below:

The graph shows self-reported IQ according to a survey of SSC readers the year 2020. Crémieux Recueil points out that people seem to round their answer so that it ends in either 5 or 0. This can illustrate the flimsiness of self-reported data, though some people commenting on the post claim they’ve taken tests that round the number, or that they’ve only gotten a confidence interval and would have to guess the exact number. Not remembering/knowing your IQ score exactly is maybe not that weird, but it is an artifact you don’t get in real test data, only in self-report.
What I would like to focus on is that these self-reported numbers just seem unlikely regardless. It’s known that self-report of positive qualities tend to become inflated. This is clearly exemplified when people compare themselves to others - infamously one study showed that around 88% of U.S. citizens think they’re better than average at driving. Over-estimation also happens for qualities reported in absolute numbers.1
Single examples on the SSC survey seem to invoke numbers that many psychologists consider ridiculous, with multiple reports of IQ six or seven (!) standard deviations above the mean. Erik Hoel has a compelling discussion on why these types of extreme number are not meaningful - specifically the section “IQ tests get less defined the higher you go”. For example, he points out that when you get to very high scores the measurement errors also becomes much larger. IQ tests are mostly valid and reliable within the ranges psychologists care about, but when it comes to differentiating an IQ of 135 from one of 145 they’re pretty bad. When I see these extreme scores on the survey, I also wonder what test they’ve used; the most established test I’m aware of, WAIS-IV, maxes out at 160. There are other tests of course, but still, it sure raises some doubts.
I downloaded the data, which was generously openly shared on the blog. Like Crémieux I removed a couple of low outliers but kept the high ones. The mean I got was 137, slightly above the 99th percentile.
Perhaps you don’t find that unlikely? Maybe it doesn’t sound that weird that mostly high-IQ people would be attracted to reading 10000 word essays on SSRIs and book reviews of “The Origin Of Consciousness In The Breakdown Of The Bicameral Mind”.
How smart do you have to be to find SlateStarCodex interesting?
It wouldn’t be surprising if people over-reported their IQ. Still one probably wouldn’t invoke this explanation if the number wasn’t so high. Imagine you didn’t believe anyone would lie or self-decieve about their IQ and that you didn’t know the result of the survey yet. How would you would try to predict before-hand what type of result you would find?
My go at this would be to think of what sort of function would describe who becomes a reader. We can name this the “interest function”. Anyone can happen across the blog but whether they find it interesting enough to keep reading is (hypothetically) related to their IQ.2 This is a bit of a toy-example so stay with me. What would a plausible interest function look like?
One suggestion is that it’s simply exponential, the more IQ the more interest, compounding. I don’t think that sounds likely. When you’re at a level where you’re able to engage with the material, additional IQ-points shouldn’t do much. Instead I guess it should be some sort of sigmoid function, where the likelihood-of-interest gradually rises and then settles approaching a maximum. I used a common logistic function:3
I could imagine that who’s interested in a nerdy blog about psychiatry and rationality is somewhat related to IQ. Let’s for the sake of argument start with a kind of dramatic function where interest in the blog is quite low below 100 IQ, sharply rising when you move one standard deviation above but becoming almost satiated by two SD above.

I can’t really tell if this function would be considered flattering. On one hand if you’re the sort of person who worships “Intelligence”, maybe you want your blog to attract high-IQ-people. On the other hand, Scott Alexander is a compelling writer and good at explaining his thoughts. That you don’t have to be a genius to get it should be a compliment. It’s easy to argue that the function would be flatter and not as right-shifted for this reason, but I wanted to use one of the more severe functions that I would still accept as at least somewhat plausible.
Now, let’s multiply this interest function by the probability density function of the normal distribution. I.e. the probability of being at a certain level of IQ is multiplied by the probability that someone at that level would find the blog interesting.
Before you scroll down, make a guess. What would the new distribution look like? What would the new mean be?

The new distribution lands at about one standard deviations above the mean, or in IQ-points: 115.
We can also see a similar probability of being at the mean of the population distribution and at two standard deviations above. The reason is that even though we set our probability of interest as low at the mean4 there just are that many more people at the center of the distribution.
This is quite far from the self-reported SSC-data. You can for example see at the histogram at the start of the post that a very rare IQ of 165 is more frequently reported than a common average IQ of 100. Finding people with 165 IQ at all should be hard. For every person with 165 IQ in the population we should expect there to be 10000 people with an average 100.
But ok, maybe the real interest function is more extreme than the one I imagined. I built a Shiny app where you can play with different values for the interest function (link).5 Let’s keep the shape and shift the interest function even more, 2 standard deviations:

Now interest is very low at the mean and interest-probability doesn’t become satiated until after three standard deviations above the mean. I honestly don’t find this interest function believable, but maybe you do. Let’s see how it looks when multiplied by the population probability density function:
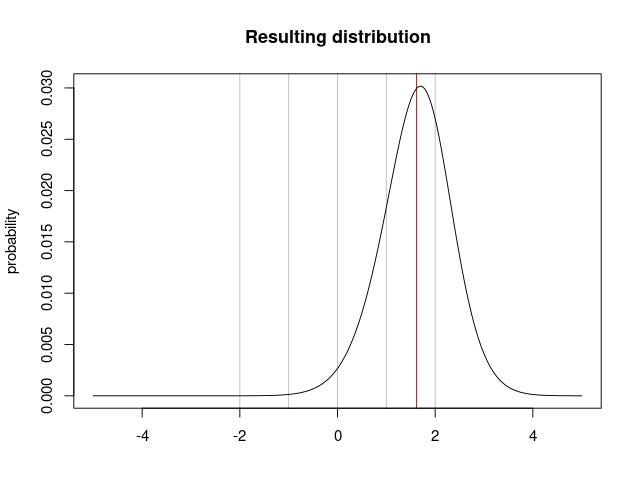
Even so, we still only get a mean 1.62 standard deviations above the mean, corresponding to 124 IQ.
If I want to get it close to 137 I need to shift the interest function a total 4.5 standard deviations to the right! The resulting interest function and distribution looks like this:

The probability of interest is now very low at 130 IQ and even at 145 IQ6, only picking up after that. I think most readers would agree that such an interest function seems a bit ridiculous. SlateStarCodex a sort of nerdy blog about a variety of subjects, not a collection of extremely difficult math puzzles. It’s written in an accessible style of English and is often shared on social media. When it discusses difficult concepts it usually does so in a pedagogical way. (This is a good thing!)
The point I want to make is that claiming that some subset of the population is two and a half standard deviations above the mean is a more extreme claim than it initially might sound like (this goes for other traits and contexts as well). It’s easy to think something along the lines of “I bet mostly high-IQ people are attracted to the blog”, and assume that that is enough to shift the mean to whatever you consider to be high-IQ. That thought process is basically a version of the base-rate fallacy.
Even if we grant that “probability of interest” is a clearly simplified way of thinking about this, I don’t think a more complicated conceptualization of the function would justify something like the final graph. For example: Maybe you think high IQ-people are also more likely to come across the blog in the first place, and/or are more likely to actually respond to the yearly reader survey. I don’t think that would be enough.
Ok but when would we expect subpopulations to average over two standard deviations above the mean?
I’m not sure. My two cents is that unless there’s gate-keeping, like for example competition for a limited number of spots where IQ is expected to give you a significant edge, you probably wouldn’t get an average that high. If the competition is intense enough, with very many people competing for only a few spots, IQ wouldn’t even necessarily have to give you a huge edge (I think) since other determinants of winning in the competition would also likely max out.
Another context is when there’s some continuous pressure to drop out over time, and having a high IQ helps you daily. For example, making it through a long and difficult education. That context could be seen as analogous with applying the interest function again and again and again.
The third context is if you almost per definition select based on the variable. For example I wouldn’t be surprised if someone said OCD-patients are two standard deviations above the mean on some measure of intrusive thoughts.
But I don't think SlateStarCodex readers have an average IQ of 137.
When it comes to (likely) inflated self-reports of IQ I think it’s probably a mix of mostly people considering themselves better than average in relation to others (better-than-average-effect) and a bit of overestimation of ones ability in absolute terms (overconfidence).
Of course it’s more like a combination of who’s interested and who comes across the blog, other traits related to nerdiness, politics, and a bunch of different factors.
When changing the function we manipulate two extra variables that we can call shift (s) and rise (r):
Probability of interest at the mean is 12%, compared to 95% 2 SD and 99.5% at 3 SD.
My very first Shiny app, so be nice!
Specifically 0.002% and 3%. If you want to be pedantic the new mean ended at 136, but I thought it was a bit more elegant to work with round numbers. I admit I did not expect to have to shift the interest function that far; When I built the app I first happened to set the limits of the shift-slider so that it wasn’t even possible to input the values required.
It seems to me like your analysis is assuming a low correlation between blog readers. If readership primarily drew from random internet traffic, that might make sense, but if it draws from social communities then it doesn't. We already have many social communities of high-IQ people, universities and tech campuses. If SSC readership comes from word-of-mouth recommendations from within those kinds of communities, or other communities that self-select for high IQ, then that's all you need.
People I know IRL who read the blog all have IQs around 137 or whatever, so it doesn't seem implausible to me.
You're missing a confounder - people who *know their IQ* are likely to have high IQs. More specifically, in the US they're likely to have one that's at least 130.
When I was growing up, grade schools in the US had special programs for extra-smart kids - the one in California was called "Mentally Gifted Minors". The cutoff for being assigned to this program was an IQ of 130 (aka ">98% on standardized tests"). So in my experience (and also that of many other SSC readers) if your IQ is >130 you were asked (around 4th grade IIRC) to attend special classes because you have a high IQ. People who in their youth were told their IQ is notably high have a big incentive to later go get tested to see how high it is; people who have NOT been told that have much LESS incentive to do so. So survey-takers whose IQ is under 130 are likely to not know the number so they skip the question; survey-takers whose IQ is over 130 are much more likely to know the number (and if they don't know it, they can safely *guess* it's at least that high).