Archive
IBM Assigned Twelve Storage Patents
Yes, IBM is at it again with it’s storage innovation receiving 12 new patents for tape systems. What? You thought tape was a dead? Again? Tape is very much alive and kicking and while you may be jaded one way or another, tape is still the cheapest most reliable long term storage platform out there.
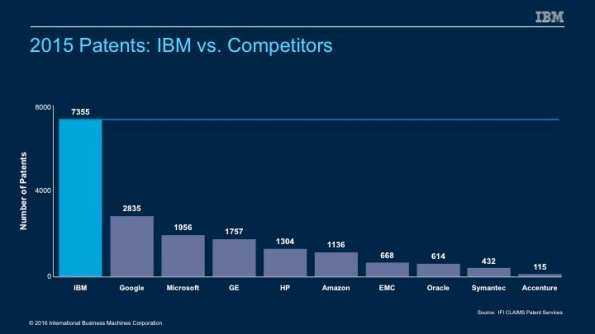
IBM is known for it’s innovation and the patents it is awarded every year. For the last 23 years, it has been awarded more patents in the US than any other company. Just in 2015, IBM was awarded 7355 patents compared to 7852 patents for Google, Microsoft GE and HP combined. Roughly 40% of the 18172 patents awarded went to IBM.
When you look at the 12 storage patents (listed here), you notice they are all from 2010- to 2014/15. They range from how the data is written to abrasion check. The people behind these technologies are brilliant to say the least and it shows in the details of the filing. While they are sometimes hard to read, the technology being introduced will save IBM customers time and money down the road.
IBM also uses its patents as a revenue source. Just in the last year, IBM sold patents to both Pure Storage and Western Digital. Since Pure and IBM compete in the all flash array environment, IBM must of gotten a huge sum of money for those patents to offset the ability to crush your competitor. None the less, IBM utilizes its investment of R&D buy selling the technology to others who may be spending their money elsewhere (like marketing and selling).
If you want to learn more about the IBM Storage Patents, click over here to read about them in detail.
Value of Spectrum Control to Spectrum Scale
Great new Blog from my friend Ravi Prakash. Follow him for all things Spectrum Control!….
Today if you are a customer in a sector like financial, retail, digital media, biotechnology, science or government and you use applications like big data analytics, gene sequencing, digital media or scalable file serving, there is a strong possibility that you are already using IBM Spectrum Scale (previously called General Parallel File System or GPFS).
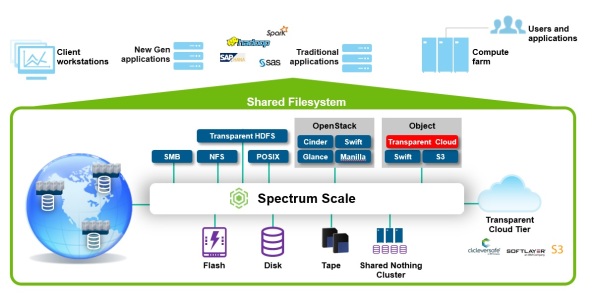
A question foremost in your mind may be: “If Spectrum Scale has its own element manager – the Scale GUI, what would I gain from using Spectrum Control?”
The Spectrum Scale GUI focuses on a single Spectrum Scale cluster. In contrast, the Spectrum Control GUI offers a single pane-of-glass to manage multiple Scale clusters, it gives you higher level analytics, a view of relationships between clusters, the relationships between clusters and SAN attached storage. In future, we expect to extend this support to Spectrum Scale in hybrid cloud scenarios where Spectrum Scale may be backed…
View original post 382 more words
Do RDMs need MPIO?
I got a great question the other day regarding VMware Raw Device Mappings:
If an RDM is a direct pass though of a volume from Storage Device to VM, does the VM need MPIO software like a physical machine does?
The short answer is NO, it doesn’t. But I thought I would show why this is so, and in fact why adding MPIO software may help.
First up, to test this, I created two volumes on my Storwize V3700.

I mapped them to an ESXi server as LUN ID 2 and LUN ID 3. Note the serials of the volumes end in 0040 and 0041:

On ESX I did a Rescan All and discovered two new volumes, which we know match the two I just made on my V3700, as the serial numbers end in 40 and 41 and the LUN IDs are 2 and 3:

I confirmed that the…
View original post 356 more words
Clustering V7000 Unified Storage Controllers
We have been getting this question about clustering the storage controllers on the V7000 Unified (V7kU) more and more as people start expanding their systems beyond their initial controllers. But let’s step back a few steps and understand what we are working with first.
- V7kU is a mixed protocol storage platform. It uses Spectrum Scale as the file system and Storwize as the operating system. This is important as people get interested in how they can adopt a high speed, parallel file system with grace and ease. The V7kU comes preloaded so no need to understand the knobs and switches of installing and configuring Spectrum Scale (formerly known as GPFS). The V7kU supports SMB (CIFS), NFS, FC, FCoE, iSCSI and can be used with other building blocks like Openstack to support Object Storage too.
- V7kU can scale up to 20 disk enclosures per controller. This platform can cluster up to four controllers giving customers a chance to max out around 7.5 PBs of storage. The best part is you can mix and match drives types and sizes. You can have flash drives in the same enclosure as SAS and NLSAS drives.
- Single interface is the best part of this solution. You can provision both block and file access from the same gui/cli. Data protection like snapshot s and flash copies, replication and remote cache copies.
- Policy based data management. One of my favorite parts of the solution is I can create policies to manage the data on the box. For example, I can create a policy that says if my flash pool becomes 75% full start moving the oldest data to the NLSAS pool. Not only does this make my job easier not having to manage the data move, but it frees up the flash pool and extends the buying power of the flash. Since flash is the most expensive part of the storage, I want the best bang for the buck there.
Now comes the part of can we cluster these V7000s to make a bigger pool, yes we can. Not only can we cluster the systems (multiple IO groups) we can mix the file and block independently. The best part as you add IO groups you add more performance, capacity all the while managing it from the same single interface.
This was taken from the V7000 Infocenter:
Procedure
Results
id name UPS_serial_number WWNN status IO_group_id IO_group_name config_node UPS_unique_id hardware 1 node1 1000877059 5005076801000EAA online 0 io_grp0 yes 20400002071C0149 8F2 2 node2 1000871053 500507680100275D online 0 io_grp0 no 2040000207040143 8F2
All nodes are now online.
Cloud vs Tape, keep the kittens off your data!
Currently, I am working with a customer on their archive data and we are discussing which is the better medium for their data that never gets read back into their environment. They have about 200TB of data that is sitting on their Tier 1 that is not being accessed, ever. The crazy part is this data is growing faster than the database that is being accessed by their main program.
This is starting to pop up more and more as the unstructured data is eating up storage systems and not being used very frequently. I have heard this called dark data or cold data. In this case its frozen data.
We started looking at what it would cost them over a 5 year period to store their data on both tape and cloud. Yes, that four letter word is still a very good option for most customers. We wanted to keep the exercise simple so we agreed that 200TB would be the size of the data and there would be no recalls on the data. We know most cloud providers charge extra for the recalls so we wanted and of course the tape system doesn’t have that extra cost so we wanted an apples to apples comparison. As close as we could.
For the cloud we used Amazon Glacier pricing which is about $0.007 per GB per month. Our formula for cloud:
200TB X 1000GB X $0.007 x 60 months = $84,000
The tape side of the equation was a little more tricky but we decided that we would just look at the tape media and tape library in comparison. I picked an middle of the road tape library and the new LTO7 media.
Tape Library TS3200 street price $10,000 + 48 LTO7 tapes (@ $150 each) = $17,200
We then looked at the ability to scale and what would happen if they factored in their growth rate. They are growing at 20% annually which translates to 40TB a year. Keeping the same platforms what would be their 5 year cost? Cloud was..
200TB + (Growth of 3.33TB per month) x 1000GB x 60 months = $125,258
Tape was calculated at:
$10,000 for the library + (396TB/6TB LTO7s capacity)x$150 per tape = $19,900
We all here how cloud is so much cheap and easier to scale but after doing this quick back of the napkin math I am not so sure. I know what some of you are saying that we didn’t calculate the server costs and the 4 FTEs it takes to manage a tape system. I agree this is basic but in this example this is a small to medium size company that is trying to invest money into getting their product off the ground. The tape library is fairly small and should be a set it and forget it type of solution. I doubt there will much more overhead for the tape solution than a cloud. Maybe not as cool or flashy but for $100,000 over 5 years they can go out and buy their 5 person IT staff a $100 lunch everyday, all five years.
So to those who think tape is a four letter word and is that thing in the corner that no one wants to deal with, I say embrace it and squeeze the value out of them. Most IT shops have tape still and can show to their finical teams how they can lower their cost with out putting their data at risk in the cloud with this:
IBM Bundles Spectrum SDS Licenses
IBM changed the way they are going to market with the Spectrum Storage family of software defined storage platform. Since the initial re-branding of their software formerly known as Tivioli, XIV, GPFS, SVC, TPC and LTFS, the plan was to create a portfolio of packages that would aid in protecting and storing data on existing hardware or in the cloud. This lines up with how Big Blue is looking for better margins and cloud ready everything.
These platforms, based on a heritage of IBM products, now are available as a suite where a customer can order the license (per TB) with unlimited usage for all six offerings. The now allows customers to move more rapidly into the SDS environment not have a complex license agreement to manage. All of the Spectrum family is based on a similar look and feel and support is all done through IBM.
Clients will have to license the software only for production capacity. Since all of the software is part of the suite, clients can also test and deploy different items and mix and match as they see fit. If you need 100TB of data protection, this allows you to have 50TB or Spectrum Protect and maybe 50 TB of Spectrum Archive. If you then need to add storage monitoring IE Spectrum Control, then your license count doesn’t start from 0 but at 100TB. If anything has taught me working with IBM, the more you buy of the same thing the cheaper per unit it will be in the end.
For more information on the Spectrum Storage Suite go to the IBM home here:
XIV Real Time Compression Q&A
I had a customer recently upgrade their XIVs to the 11.6.1 code and wanted to know more about the real time compression that is now built into the code. IBM purchased the compression technology from a company named “Storwize” and adopted the name for their mid-range product family. One of the cool things that came out of that acquisition is the RACE engine that runs the compression algorithm.
Basically the compression is your standard LZ compression with some cool technology that keeps meta data about what you are writing. For XIV, this happens before the data is written to cache and turns all of those random writes into a sequential write. If you want to dig into the way RTC works check out this link.
The XIV team took the compression technology and integrated it into the XIV. The GUI even will show you an estimate on which volume will get better compression savings in order to fine tune your workloads. 
Q. How does the compression work? Is it on all the volumes/pools?
A. Compression can turned on if a pool is set to “thin”. This thin pool then can have both thick and thin volumes in it. Once compression is turned on and licensed you can convert any thin volume to a compressed volume by right clicking on it and choosing compress. You can also tell XIV to compress all of your volumes or de-compress all of your volumes.
Q. Can I turn it off and on based on compression savings?
A. Yes, compression can be turned off on the whole box or just one volume. You get to decide based on the compression savings
Q. What size volumes can it handle?
A. The maximum is 10TB and the minimum is 52GB
Q. What kind of performance hit will it have on the XIV?
A. There are some benchmarks in the redbook with turning on compression that can help you decide on compression. Basically it comes down to two things: the workload and the model of XIV. If you look in the Compression Savings field and it is 30% or less then the you should not compress that data. If you have a new 314 model or 214 model compression can be turned on but 114 models need to be checked to make sure there is enough horsepower.
Q. What type of data does not compress well?
A. I get this question a lot. The basic answer is any time of data that has either already been compressed. Also backups seem to have lower compression savings. The better answer is always look at the compression savings in the gui and base conclusion on that output.
Q. Can I compress volumes that are mirrored?
A. Of course. Mirrored volumes can be compressed on both sides. If the mirror already exists then the mirror has to be broken, data compressed and the mirror copy has to be re-synced. We have seen a major performance improvement with compressed mirrored volumes as the amount of data being transferred is cut into half or less.
If you have questions about running compression on XIV or any other IBM platform leave a comment and I will try to answer them here.
Storage is dead. Long live Storage.
Storage is a wonderful place to work. It seems like every few months someone or something new is coming out with the latest way to make it easy to store more data for less. There seems like about 100 new startups all begging for money and clients all the while trying to build new code bases to fix issues solved by the Big 5 years ago.
The 5 big five of course being IBM, EMC, NTAP, HP and HDS in some sort of order. These companies have spent Billions of dollars researching and engineering ways to store the simple bits of our 1s and 0s. Now in the new age we see these companies struggling for sales and even the market share leader of ~45% is being sold to a PC company because its not making the money it did a few years ago.
If you look at what is happening in the storage industry you can see why. Price per TB is rock bottom thanks to our buddies at Amazon and Google. IT Directors expect these cloud prices of pennies on the TBs in order to keep up with the demand on budgets. Just think 30 years ago gas cost $1.09 and a GB of data cost you $105,000. Now gas is around $2.00 and a GB of data? Well let’s just say it is around $0.03. What other commodity has fallen so quickly as data storage?
Another reason is efficiency. Storage has gotten better at making better use of the disks and better space savings all together. You can see it in the technologies like XIV and VSAN where the disks are dumb and the RAID is software. Also through in Dedupe, compression, clones, etc. and now the system that you bought for 100TBs a couple years ago is compared to a system with the same hardware (drive sizes anyway) that can push 300-500TBs of capacity. So that $100,000 storage array that was pushing 100TB is now the same cost for 500TBs.
And the last reason I see causing companies to squirm is Software Defined Infrastructure. Companies buy what hardware they want and then lay down their preferred software on top to manage and protect their data. And since its a heck of a lot easier to start a software company where you don’t have to worry about all of those pesky firmware versions and interop-ability matrix things, they are sprouting up like dandelions.
Now put it all together, lower cost /TB, better efficiency, and more software sales reps will lead to lower sales and lower potential. There is only one way out. Those who can put all of this together.
I have heard over and over that everyone wants to move out of hardware and move to cloud based or hybrid cloud. I see the value in cloud and I believe it has a place in the data center but for the most part I see it as a low cost storage platform where data is hosted for non mission critical applications. You want to run you email or CRM system there? sure go for it. You want to run distribution system or your surgical system out there when Netflix and Chill is happening? Probably not.
So to the Big 5 as a 2016 word of advice, embrace your hardware. It makes you different. It gives you a chance to walk into customers and give them a choice. Don’t fall for the flashy object of cloud (honestly the margins can’t be that good). Spend time developing integration into applications so things can work better together. Spend time reaching out to other companies and seeing how you can integrate their technologies into your own with out having to acquire them.
In the long run, people are going to make the best choice for their company and one shoe doesn’t fit all. The more you can offer and the better the offerings are, the better the customer will feel about your company. And who knows they might take a look at something else you sell down the road.
XIV Soft limit can be adjusted by customer
It appears IBM has removed the requirement for XIV systems running 11.6 that need to over provision beyond what the box is provide. Before 11.6 a XIV customer had to ask a Technical Advisor (TA) to submit a RPQ and then they would dial into the system to change the total amount of storage that could be provisioned. This was normally done because of thin provisioning but now even more so becuase of compression on XIV.
Here is the information I see in the release notes:
XIV 11.6 Command Reference: system_soft_capacity_set soft_size=SizeGB
This command is used to set the size of the system soft capacity. The soft capacity size of the system can be set to up to 3 times the size of the hard capacity of the system, and as low as the maximum size between the currently allocated soft capacity and the system’s hard capacity (whichever is greater). The current hard, soft, and/or allocated soft capacity can be retrieved using the system_capacity_list command.
I still would advise any customers wishing to change the soft capacity to speak with either a TA or a support person.
IBM Storage Sessions at Interconnnect
If you are attending the IBM Inetconnect conference there is a TON of storage related sessions. Here is the link to the main page where you can find out all the information about general sessions and the Aerosmith concert.
To build your agenda you can go to the portal here: IBM Interconnect Portal
There you will see all sorts of information about the conference and you can sign up for sessions ahead of time. You can look at certain ‘tracks’ for different types of sessions or you can search for them based on the date/time or session topic. If you are interested in a storage related topic I have listed them below. Do notice that these sessions are at Mandalay Bay.
If you see me in the halls feel free to introduce yourself and I will buy you a coffee/beverage of choice.
| Session Number | Session Name | Date | Time | Location |
| 5987 | Storage and Data Protection Track Kickoff | Monday, February 23, 2015 | 11-12 pm | Mandalay Bay Ballroom A |
| 6171 | IBM Tivoli Storage Manager for Enterprise Resource Planning Protecting SAP HANA | Monday, February 23, 2015 | 12-12.50 pm | Mandalay Bay-Meet the Experts Forum #3 |
| 1037 | Tivoli Storage Productivity Center: A Field-Level Guide for Deployment or Upgrading | Monday, February 23, 2015 | 12.15-1.15 pm | Mandalay Bay Breakers I |
| 3780 | Data Management in the Cloud | Monday, February 23, 2015 | 2-3 pm | Mandalay Bay Breakers I |
| 3363 | The Secret to Building a Successful Enterprise Storage Infrastructure for Cloud | Monday, February 23, 2015 | 12.15-1.15 pm | Mandalay Bay-Breakers J |
| 3959 | IBM Data Protection Roadmap | Monday, February 23, 2015 | 5-6 pm | Mandalay Bay Ballroom A |
| 3620 | IBM Tivoli Storage Manager for Virtual Environments 7.1.1 VMware Lab | Monday, February 23, 2015 | 3.30 -6.30 pm | MB South Seas G |
| 3809 | Gain Insights and Efficiency by Managing Elastic Storage with IBM SmartCloud Virtual Storage Center | Tuesday, February 24, 2015 | 8-9 am | Mandalay Bay-Breakers I |
| 3861 | Learn How to Detect and Avoid Problems in Your Storage Environment | Tuesday, February 24, 2015 | 9.30-10.30 am | Mandalay Bay-Breakers I |
| 4001 | Simplify Storage Management with Tivoli Storage Productivity Center | Tuesday, February 24, 2015 | 11-12 pm | Mandalay Bay-Breakers I |
| 3921 | IBM’s Software Defined Storage Vision and Strategy | Tuesday, February 24, 2015 | 2-3 pm | Mandalay Bay Ballroom A |
| 2257 | How Using IBM Virtual Storage Center Simplifies Life and Cuts Costs for Verint Systems | Tuesday, February 24, 2015 | 3.30-4.30 pm | Mandalay Bay-Breakers I |
| 3878 | SAP HANA Data Protection Capabilities and Best Practices | Tuesday, February 24, 2015 | 11-12 pm | Mandalay Bay Breakers J |
| 3627 | IBM Tivoli Storage Productivity Center 5.2 Daily Operations and Provisioning | Tuesday, February 24, 2015 | 8-10 am | MB South Seas G |
| 1665 | TSM 101: Tivoli Storage Manager Spelled Out | Tuesday, February 24, 2015 | 10-10.50 am | MTE/Engagement Center |
| 6051 | Blueprints Aren’t Just for Houses | Tuesday, February 24, 2015 | 11-11.50 am | Mandalay Bay-Meet the Experts Forum #3 |
| 1462 | Elastic Storage: Software Defined Storage for Cloud, Big Data/Analytics and Technical Computing | Tuesday, February 24, 2015 | 2-3 pm | Mandalay Bay Breakers I |
| 4973 | BYOC—Bring Your Own Challenge—to the Storage Software Portfolio Experts | Tuesday, February 24, 2015 | 12.30-1.30 pm | Mandalay Bay Mandalay Ballroom A |
| 5196 | Evolving from Traditional Storage and Backup to an Optimized, State-of-the-Art Solution | Tuesday, February 24, 2015 | 12.30-1.30 PM | Mandalay Bay Breakers J |
| 6635 | Next-Generation Data Protection, Reporting, Monitoring and Alerting for Heterogeneous Environments | Tuesday, February 24, 2015 | 5.30-6.30 PM | Mandalay Bay Breakers I |
| 1295 | Optimize Your Storage with IBM SmartCloud Virtual Storage Center Advanced Analytics | Wednesday, February 25, 2015 | 1-2 pm | MTE/Engagement Center |
| 3588 | Advance Your Business with IBM’s Software Defined Storage Offerings | Wednesday, February 25, 2015 | 2-3 PM | Mandalay Bay Breakers I |
| 5109 | Protecting Data in Hybrid Cloud Environments | Wednesday, February 25, 2015 | 8-9 am | Mandalay Bay Ballroom A |
| 5606 | Affordable Data Protection for SMBs | Wednesday, February 25, 2015 | 11-12 pm | Mandalay Bay Breakers J |
| 5519 | Capital City Bank: Winning with IBM Tivoli Storage Manager Cloud Solutions for the Mid-Market | Wednesday, February 25, 2015 | 3.30-4.30 pm | Mandalay Bay-Breakers J |
| 3672 | Storage Infrastructure Matters for the Cloud | Thursday, February 26, 2015 | 9-10 am | Mandalay Bay-Breakers I |
| 4791 | Data Protection in Virtual Server Environments: One Size Does Not Fit All | Thursday, February 26, 2015 | 10.30-11.30 am | Mandalay Bay Breakers I |
| 4394 | Explore the Benefits of Three Future Tivoli Storage Manager Capabilities | Thursday, February 26, 2015 | 9-10 am | Mandalay Bay Ballroom A |
| 3623 | Tivoli Storage Manager 7.1.1 Node Replication | Thursday, February 26, 2015 | 8-10 am | Mandalay Bay South Seas A |
| 3629 | IBM Tivoli Storage Productivity Center 5.2 Reporting | Thursday, February 26, 2015 | 8-10 am | Mandalay Bay South Seas J |
| 2132 | Tivoli Storage Manager 7 in a Large-Scale Linux Environment at State Farm Insurance | Thursday, February 26, 2015 | 9-10 am | Mandalay Bay Breakers J |
| 5224 | Elastic Storage in the Cloud | Thursday, February 26, 2015 | 1-2 pm | Mandalay Bay Breakers I |
| 5025 | Large-Scale Migration from Symantec NetBackup to Tivoli Storage Manager at Portugal’s Largest Bank | Thursday, February 26, 2015 | 10.30-11.30 am | Mandalay Bay Breakers J |
