
Abstract
Integration of machine learning (ML) components in critical applications introduces novel challenges for software certification and verification. New safety standards and technical guidelines are under development to support the safety of ML-based systems, e.g., ISO 21448 SOTIF for the automotive domain and the Assurance of Machine Learning for use in Autonomous Systems (AMLAS) framework. SOTIF and AMLAS provide high-level guidance but the details must be chiseled out for each specific case. We initiated a research project with the goal to demonstrate a complete safety case for an ML component in an open automotive system. This paper reports results from an industry-academia collaboration on safety assurance of SMIRK, an ML-based pedestrian automatic emergency braking demonstrator running in an industry-grade simulator. We demonstrate an application of AMLAS on SMIRK for a minimalistic operational design domain, i.e., we share a complete safety case for its integrated ML-based component. Finally, we report lessons learned and provide both SMIRK and the safety case under an open-source license for the research community to reuse.
Similar content being viewed by others

1 Introduction
Machine learning (ML) is increasingly used in critical applications, e.g., supervised learning using deep neural networks (DNN) to support automotive perception. Software systems developed for safety-critical applications must undergo assessments to demonstrate compliance with functional safety standards. However, as the conventional safety standards are not fully applicable for ML-enabled systems (Salay et al., 2018; Tambon et al., 2022), several domain-specific initiatives aim to complement them, e.g., organized by the EU Aviation Safety Agency, the ITU-WHO Focus Group on AI for Health, and the International Organization for Standardization.
In the automotive industry, several standardization initiatives are ongoing to allow safe use of ML in road vehicles. It is evident that the established functional safety as defined in ISO 26262 Functional Safety (FuSa) is no longer sufficient for the next generation of advanced driver-assistance systems (ADAS) and autonomous driving (AD). One complementary standard under development is ISO 21448 Safety of the Intended Functionality (SOTIF). SOTIF aims for absence of unreasonable risk due to hazards resulting from functional insufficiencies, incl. those originating in ML components.
Standards such as SOTIF mandate high-level requirements on what a development organization must provide in a safety case for an ML-based system. However, how to actually collect the evidence — and argue that it is sufficient — is up to the specific organization. Assurance of Machine Learning for use in Autonomous Systems (AMLAS) is one framework that supports the development of corresponding safety cases (Hawkins et al., 2021). Still, when applying AMLAS on a specific case, there are numerous details that must be analyzed, specified, and validated. The research community lacks demonstrator systems that can be used to explore such details.
To address the lack of ML-based demonstrator systems with accompanying safety cases, we embarked on an engineering research endeavor. Engineering research is described in the evolving ACM SIGSOFT Empirical Standards (Ralph et al., 2020) and we consider it synonymous with design science research (Wieringa, 2014; Runeson et al., 2020). Our engineering research was guided by the following design problem:
How to demonstrate and share a complete ML safety case for an open ADAS?
We report results from an industry-academia collaboration on safety assurance of SMIRK, an ML-based open-source software (OSS) ADAS that provides pedestrian automatic emergency braking (PAEB) in an industry-grade simulator. SMIRK is an “original software publication” (Socha et al., 2022) available on GitHub (RISE Research Institutes of Sweden, 2022). In this paper, our main contribution is the carefully described application of AMLAS in conjunction with the development of an ML component. While parts of the framework have been demonstrated before (Gauerhof et al., 2020), we believe this is the first comprehensive use of AMLAS conducted independently from its authors. Moreover, we believe this paper constitutes a pioneering safety case for an ML-based component that is OSS and completely transparent. Thus, our contribution can be used as a starting point for studies on safety engineering aspects such as operational design domain (ODD) extension, dynamic safety cases, and reuse of safety evidence.
Our results show that even an ML component in an ADAS designed for a minimalistic ODD results in a large safety case. Furthermore, we consider three lessons learned to be particularly important for the community. First, using a simulator to create synthetic data sets for ML training particularly limits the validity of the negative examples. Second, evaluation of object detection is non-intuitive and necessitates internal training. Third, the fitness function used for model selection encodes essential tradeoff decisions; thus, the project team must be aligned.
The paper is organized into three main parts:
- Part I:
-
Section 1 contains this introduction. Section 2 contains a background section describing SOTIF, AMLAS, and object detection using YOLO. In Section 3, we share an overview of related work. Finally, Section 4 describes the method used in our R&D project.
- Part II:
-
Sections 5–11 describe the intertwined development and safety assurance of SMIRK. We present an overall system description (Section 5), system requirements (Section 6), system architecture (Section 7), data management strategy (Section 8), ML-based pedestrian recognition component (Section 9), test design (Section 10), and test results (Section 11), respectively.
- Part III:
-
Section 12 reports lessons learned from our R&D project. Section 13 discusses the main threats to validity before Section 14 concludes the paper and outlines future work.
Finally, to ensure a self-contained paper, the Appendix presents the complete AMLAS safety argumentation for the use of ML in SMIRK.
2 Background
This section briefly presents SOTIF and AMLAS, respectively. Also, we present details of object detection and recognition using YOLO, which is fundamental to understand the subsequent safety argumentation.
2.1 SOTIF
ISO 21448 SOTIF is a candidate standard under development to complement the established automotive standard ISO 26262 Functional Safety (FuSa). While FuSa covers hazards caused by malfunctioning behavior, SOTIF addresses hazardous behavior caused by the intended functionality. Note that SOTIF covers “reasonably foreseeable misuse” but explicitly excludes antagonistic attacks; thus, we do not discuss any security concerns in this paper. A system that meets FuSa can still be hazardous due to insufficient environmental perception or inadequate robustness within the ODD. The SOTIF process provides guidance on how to systematically ensure the absence of unreasonable risk due to functional insufficiencies. The goal of the SOTIF process is to perform a risk acceptance evaluation and then reduce the probability of (1) known and (2) unknown scenarios causing hazardous behavior.
Figure 1 shows a simplified version of the SOTIF process. The process starts in the upper left with A) Requirements Specification. Based on the requirements, a B) Risk Analysis is done. For each identified risk, its potential Consequences are analyzed. If the risk of harm is reasonable, it is recorded as an acceptable risk. If not, the activity continues with an analysis of Causes, i.e., an identification and evaluation of triggering conditions. If the expected system response to triggering conditions is acceptable, the SOTIF process continues with V&V activities. If not, the remaining risk forces a C) Functional Modification with a corresponding requirements update.

A simplified overview of the SOTIF process. Adapted from ISO 21488
The lower part of Fig. 1 shows the V&V activities in the SOTIF process, assuming that they are based on various levels of testing. For each risk, the development organization conducts D) Verification to ensure that the system satisfies the requirements for the known hazardous scenarios. If the F) Conclusion of Verification Tests are satisfactory, the V&V activities continue with validation. If not, the remaining risk requires a C) Functional Modification. In the E) Validation, the development organization explores the presence of unknown hazardous scenarios — if any are identified, they turn into known hazardous scenarios. The H) Conclusion of Validation Tests estimate the likelihood of encountering unknown scenarios that lead to hazardous behavior. If the residual risk is sufficiently small, it is recorded as an acceptable risk. If not, the remaining risk again necessitates a C) Functional Modification.
2.2 Safety assurance using the AMLAS process
The methodology for the AMLAS was developed by the Assuring Autonomy International Programme, University of York (Hawkins et al., 2021). AMLAS provides a process that results in 34 safety evidence artifacts. Moreover, AMLAS provides a set of recurring safety case patterns for ML components presented using the graphical format Goal Structuring Notation (GSN) (Assurance Case Working Group, 2021).

An overview of the AMLAS process, adapted from Hawkins et al. (2021). Blue color denotes systems engineering, whereas black color relates specifically to the ML component. Numbers refer to the AMLAS stages, not sections in this paper
Figure 2 shows an overview of the six stages of the AMLAS process. The upper part stresses that the development of an ML component and its corresponding safety case is done in the context of larger systems development, indicated by the blue arrow. Analogous to SOTIF, AMLAS is an iterative process as highlighted by the black arrow in the bottom.
Starting from the System Safety Requirements from the left, stage 1 is ML Safety Assurance Scoping. This stage operates on a systems engineering level and defines the scope of the safety assurance process for the ML component as well as the scope of its corresponding safety case — the interplay with the non-ML safety engineering is fundamental. The next five stages of AMLAS all focus on assurance activities for different constituents of ML development and operations. Each of these stages concludes with an assurance argument that when combined, and complemented by evidence through artifacts, compose the overall ML safety case.
- Stage 2:
-
ML Safety Requirements Assurance. Requirements engineering is used to elicit, analyze, specify, and validate ML safety requirements in relation to the software architecture and the ODD.
- Stage 3:
-
Data Management Assurance. Requirements engineering is first used to develop data requirements that match the ML safety requirements. Subsequently, data sets are generated (development data, internal test data, and verification data) accompanied by quality assurance activities.
- Stage 4:
-
Model Learning Assurance. The ML model is trained using the development data. The fulfilment of the ML safety requirements is assessed using the internal test data.
- Stage 5:
-
Model Verification Assurance. Different levels of testing or formal verification to assure that the ML model meets the ML safety requirements. Most importantly, the ML model shall be tested on verification data that has not influenced the training in any way.
- Stage 6:
-
Model Deployment Assurance. Integrate the ML model in the overall system and verify that the system safety requirements are satisfied. Conduct integration testing in the specified ODD.
The rightmost part of Fig. 2 shows the overall safety case for the system under development with the argumentation for the ML component as an essential part, i.e., the target of the AMLAS process.
2.3 Object detection and recognition using YOLO
YOLO is an established real-time object detection and recognition algorithm that was originally released by Redmon et al. (2016). The first version of YOLO introduced a novel object detection process that uses a single DNN to perform both prediction of bounding boxes around objects and classification at once. YOLO was heavily optimized for fast inference to support real-time applications. A fundamental concept of YOLO is that the algorithm considers each image only once, hence its name “You Only Look Once.” Thus, YOLO is referred to as a single-stage object detector.
Single-stage object detectors consist of three core parts: (1) the model backbone, (2) the model neck, and (3) the model head. The model backbone extracts important features from input images. The model neck generates so-called feature pyramids using PANet (Liu et al., 2018) that support generalization to different sizes and scales. The model head performs the detection task, i.e., it generates the final output vectors with bounding boxes and class probabilities.
In a nutshell, YOLO segments input images into smaller images. Each input image is split into a square grid of individual cells. Each cell predicts bounding boxes capturing potential objects and provides confidence scores for each box. Furthermore, YOLO does a class prediction for objects in the bounding boxes. Relying on the Intersection over Union (IoU) method for evaluating bounding boxes, YOLO eliminates redundant bounding boxes. The final output from YOLO consists of unique bounding boxes with class predictions. There are several versions of YOLO and each version provides different model architectures that balance the tradeoff between inference speed and accuracy differently — additional layers of neurons provide better accuracy at the expense of computation time.
3 Related work
Many researchers argue that software and systems engineering practices must evolve as ML enters the picture. As proposed by Bosch et al. (2021), we refer to this emerging area as AI engineering. AI engineering increases the importance of several system qualities. Quality characteristics discussed in the area of “explainable AI” are particularly important to safety argumentation. In our paper, we adhere to the following definitions provided by Arrieta et al. (2020): “Given an audience, an explainable AI is one that produces details or reasons to make its functioning clear or easy to understand.” In the same vein, we refer to interpretability as “a passive characteristic referring to the level at which a given model makes sense for a human observer.” In our work on SMIRK, the human would be an assessor of
the safety argumentation. In contrast, we regard explainability as an active characteristic of a model that clarifies its internal functions. The current ML models in SMIRK do not actively explain their outputs. For a review of DNN explainability techniques in automotive perception, e.g., post hoc saliency methods, counterfactual explanations, and model translations, we refer to a recent review by Zablocki et al. (2022).
In light of AI engineering, the rest of this section presents related work on safety argumentation and testing of automotive ML, respectively.
3.1 Safety argumentation for machine learning
Many publications address the issue of safety argumentation for systems with ML-based components and highlight corresponding safety gaps. A solid argumentation is required to enable safety certification, for example to demonstrate compliance with future standards such as SOTIF and ISO 8800 Road Vehicles — Safety and Artificial Intelligence. While there are several established safety patterns for non-AI systems (e.g., simplicity, substitution, sanity check, condition monitoring, comparison, diverse redundancy, replication redundancy, repair, degradation, voting, override, barrier, and heartbeat (Wu & Kelly, 2004; Preschern et al., 2015)), considerable research is now directed at understanding to what extent existing approaches apply to AI engineering. For example, Picardi et al. (2020) presented a set of patterns that later turned into AMLAS, i.e., the process that guides most of our work in this paper.
Mohseni et al. (2020) reviewed safety-related ML research and mapped ML techniques to safety engineering strategies. Their mapping identified three main categories toward safe ML: (1) inherently safe design; (2) enhanced robustness, a.k.a. “safety margin”; and (3) run-time error detection, a.k.a. “safe fail.” The authors further split each category into sub-categories. Based on their proposed categories, the safety argumentation we present for SMIRK used an inherently safe design as the starting point through a careful “design specification” and “implementation transparency.” Moreover, from the third category, SMIRK relies on “OOD error detection” as will be presented in Section 9.3.
Schwalbe and Schels (2020) presented a survey on specific considerations for safety argumentation targeting DNNs, organized into four development phases. First, they state that requirements engineering must focus on data representativity and entail scenario coverage, robustness, fault tolerance, and novel safety-related metrics. Second, development shall seek safety by design by, e.g., acknowledging uncertainty and enhancing robustness (in line with recommendations by Mohseni et al. 2020). Third, the authors discuss verification primarily through formal model checks using solvers. Fourth, they consider validation as the task of identifying missing requirements and test cases, for which they recommend data validation followed by both qualitative and quantitative analyses.
Tambon et al. (2022) conducted a systematic literature review on certification of safety-critical ML-based systems. Based on 217 primary studies, the authors identified five overall categories in the literature: (1) robustness, (2) uncertainty, (3) explainability, (4) verification, and (5) safe reinforcement learning. Moreover, the paper concludes by calling for deeper industry-academia collaborations related to certification. Our work on SMIRK responds to this call and explicitly discusses the identified categories on an operational level (except reinforcement learning since this type of ML does not apply to SMIRK). By conducting hands-on development of an ADAS and its corresponding safety case, we have identified numerous design decisions that have not been discussed in prior work. As the devil is in the detail, we recommend other researchers to transparently report from similar endeavors in the future.
Schwalbe et al. (2020) systematically established and broke down safety requirements to argue the sufficient absence of risk arising from SOTIF-style functional insufficiencies. The authors stress the importance of diverse evidence for a safety argument involving DNNs. Moreover, they provide a generic approach and template to thoroughly report DNN specifics within a safety argumentation structure. Finally, the authors show its applicability for an example use case based on pedestrian detection. In our work, 34 artifacts of different types constitute the safety evidence. Furthermore, pedestrian detection is a core feature of SMIRK.
Several research projects selected ML-based pedestrian detection systems to illustrate different aspects of safety argumentation. Wozniak et al. (2020) provided a safety case pattern for ML-based systems and showcase its applicability for pedestrian detection. The pattern is integrated within an overall encompassing approach for safety case generation. On a similar note, Willers et al. (2020) discussed safety concerns for DNN-based automotive perception, including technical root causes and mitigation strategies. The authors argue that it remains an open question how to conclude whether a specific concern is sufficiently covered by the safety case — and stress that safety cannot be determined analytically through ML accuracy metrics. In our work on SMIRK, we provide safety evidence that goes beyond the level of the ML model. Using AMLAS, we also claim that we demonstrate sufficient evidence for ML in SMIRK. Finally, related to pedestrian detection, we find that the work by Gauerhof et al. (2020) is the closest to this study, and the reader will find that we repeatedly refer to it in relation to SMIRK requirements in Section 6.
In the current paper, we present a holistic ML safety case building on previous work for a demonstrator system available under an OSS license. Furthermore, in contrast to a discussion restricted to pedestrian detection, we discuss an ADAS that subsequently commences emergency braking in a simulated environment. This addition responds to a call from Haq et al. (2021a) to go from offline to online testing, as many safety violations cannot be detected on the level of the ML model. While online testing is not novel, research papers on ML testing have largely considered standalone image data sets disconnected from concerns of running systems.
3.2 Testing of machine learning in automated vehicles
According to AMLAS, the two primary means to generate safety evidence for ML-based systems through V&V are testing and verification (Hawkins et al., 2021). As test-based verification is substantially more mature for DNNs such as used in SMIRK, we restrict ourselves to testing. In the context of an ML-based system, this can be split into (1) data set testing, (2) model testing, (3) unit testing, (4) integration testing, (5) system testing, and (6) acceptance testing (Song et al., 2022). The related work focuses on model and system testing.
Model testing shall be performed on the verification data set that must not have been used in the training process. Depending on the test subject and the test level, the inputs for corresponding ADAS testing might be images such as in DeepRoad (Zhang et al., 2018) and DeepTest (Tian et al., 2018), or test scenario configurations as used by Ebadi et al. (2021).
Many research projects investigated efficient design of effective test cases for ADAS. Thus, several approaches to test case generation in simulated environments have been proposed. Pseudo-test oracle differential testing focuses on detecting divergence between programs’ behaviors when provided the same input data. For example, DeepXplore (Pei et al., 2017) changes the test input—like solving an optimization problem—to find the inputs triggering different behaviors between similar autonomous driving DNN models, while trying to increase the neuron coverage. Metamorphic testing works based on detecting violations of metamorphic relations to identify erroneous behaviors. For example, DeepTest (Tian et al., 2018) applies different transformations to a set of seed images and utilizes metamorphic relations to detect faulty behaviors of different Udacity DNN models for self-driving cars, while aiming for increasing neuron coverage as well. Gradient-based test input generation regards the test input generation as an optimization problem and generates a high number of failure-revealing or difference-inducing test inputs while maximizing the test adequacy criteria, e.g., neuron coverage. DeepXplore (Pei et al., 2017) utilizes gradient ascent to generate inputs provoking different behaviors among similar DNN models. Generative Adversarial Network (GAN)–based test input generation is intended to generate realistic test input, which cannot be easily distinguished from original input. DeepRoad (Zhang et al., 2018) utilizes a GAN-based metamorphic testing approach to generate test images for testing Udacity DNN models for autonomous driving.
System testing entails ensuring that system safety standards are met following the integration of the model into the system. As for model testing, many research projects proposed techniques to generate test cases. A commonly proposed approach is to use search-based techniques to identify failure-revealing or collision-provoking scenarios. Many papers argue that simulated test scenarios are effective complements to field testing — which tends to be costly and sometimes dangerous.
Ben Abdessalem et al. (2016) proposed the multi-objective search algorithm NSGA-II along with surrogate models to find critical test scenarios with few simulations for the pedestrian detection system PeVi. PeVi constitutes the reference architecture for SMIRK, as described in Section 7, for which we obtained deep insights during a replication study (Borg et al., 2021a). In a subsequent study, Ben Abdessalem et al. (2018b) used MOSA developed by Panichella et al. (2015)—a many-objective optimization search algorithm—along with objectives based on branch coverage and failure-based heuristics to detect undesired and failure-revealing feature interaction scenarios for integration testing in an automated vehicle. Furthermore, in a third related study, Ben Abdessalem et al. (2018a) combined NSGA-II and decision tree classifier models—which they referred to as a learnable evolutionary algorithm—to guide the search for critical test scenarios. Moreover, the proposed approach characterizes the failure-prone regions of the test input space. Inspired by previous work, we have used various search-techniques, including NSGA-II, to generate test scenarios for pedestrian detection and emergency braking of the autonomous driving platform Baidu Apollo in the SVL simulator (Ebadi et al., 2021).
The test cases providing safety evidence for SMIRK correspond to systematic grid searches rather than any metaheuristic search. We think this is a necessary starting point for a safety argumentation. On the other hand, as argued in several related papers, we believe that search techniques could be a useful complement during testing of ML-based systems to pinpoint weaknesses and guide functional modifications — for example as part of the SOTIF process. In the SMIRK context, we plan to investigate this further as part of future work.
4 Method: engineering research
The overall frame of our work is the engineering researchFootnote 1 standard as defined in the community endeavor ACM SIGSOFT Empirical Standards (Ralph et al., 2020). Engineering research is an appropriate standard when evaluating technological artifacts, e.g., methods, systems, and tools — in our case SMIRK and its safety case. To support the validity of our research, we consulted the essential attributes of the corresponding checklist provided in the standard. We provide three clarifications for readers cross-checking our work against these attributes: (1) empirical evaluations of SMIRK are done using simulation in ESI Pro-SiVIC, (2) empirical evaluation of the safety case has been done through workshops and peer-review, and (3) we compare the SMIRK safety case against the state-of-the-art as we build on previous work.
Engineering research aims to develop general design knowledge in a specific field to help practitioners create solutions to their problems. As discussed by van Aken (2004), technological rules can be used to express design knowledge by capturing general knowledge about the mappings between problems and proposed solutions. Technological rules can normally be expressed as “To achieve <Effect> in <Context> apply <Intervention>.” Starting from a technological rule, researchers can extend the rule’s scope of validity by applying the intervention to new contexts or develop rules from the general to more specific contexts (Runeson et al., 2020), i.e., new studies can lead to both generalization and specialization.
Our work aims to specialize a technological rule for AMLAS. Starting from:
To develop a safety case for ML in autonomous systems apply AMLAS.
we seek general design knowledge for the more specific rule:
To develop a safety case for ML-based perception in ADAS apply AMLAS.
Figure 3 shows an overview of the 2-year R&D project (SMILE IIIFootnote 2) that resulted in the SMIRK MVP (Minimum Viable Product) and the safety case for its ML component. Note that collaborations in the preceding SMILE projects started already in 2016 (Borg et al., 2019), i.e., we report from research in the context of prolonged industry involvement. Starting from the left, we relied on A) Prototyping to get an initial understanding of the problem and solution domain (Käpyaho & Kauppinen, 2015). As our pre-understanding during prototyping grew, SOTIF and AMLAS were introduced as fundamental development processes and we established a first System Requirements Specification (SRS). The AMLAS process starts in the System Safety Requirements, which in our case come from following the SOTIF process.

An overview of the SMIRK development in the SMILE III project
Based on the SRS, we organized a B) Hazard Analysis and Risk Assessment (HARA) workshop (cf. ISO 262626) with all author affiliations represented. Then, the iterative C) SMIRK development phase commenced, encompassing both software development, ML development, and a substantial amount of documentation. When meeting our definition of done, i.e., an MVP implementation and stable requirements specifications, we conducted D) Fagan Inspections as described in Section 4.1. After corresponding updates, we baselined the SRS and the Data Management Specification (DMS). Note that due to the COVID-19 pandemic, all group activities were conducted in virtual settings.
Subsequently, the development project turned to E) V&V and Functional Modifications as limitations were identified. In line with the SOTIF process (cf. Fig. 1), also this phase of the project was iterative. The various V&V activities generated a significant part of the evidence that supports our safety argumentation. The rightmost part of Fig. 3 depicts the safety case for the ML component in SMIRK, which is peer-reviewed as part of the submission process of this paper.
4.1 Safety evidence from Fagan inspections
We conducted two formal Fagan inspections (Fagan, 1976) during the SMILE III project with representatives from the organizations listed as co-authors of this paper. All reviewers are active in automotive R&D. The inspections targeted the Software Requirements Specification and the Data Management Specification, respectively. The two formal inspections constitute essential activities in the AMLAS safety assurance and result in ML Safety Requirements Validation Results [J] and a Data Requirements Justification Report [M]. A Fagan inspection consists of the steps (1) Planning, (2) Overview, (3) Preparation, (4) Inspection meeting, (5) Rework, and (6) Follow-up.
-
1.
Planning: The authors prepared the document and invited the required reviewers to an inspection meeting.
-
2.
Overview: During one of the regular project meetings, the lead authors explained the fundamental structure of the document to the reviewers, and introduced an inspection checklist. Reviewers were assigned particular inspection perspectives based on their individual expertise. All information was repeated in an email, as not all reviewers were present at the meeting.
-
3.
Preparation: All reviewers conducted an individual inspection of the document, noting any questions, issues, and required improvements.
-
4.
Inspection meeting: Two weeks after the individual inspections were initiated, the lead authors and all reviewers met for a virtual meeting. The entire document was discussed, and the findings from the independent inspections were compared. All issues were compiled in inspection protocols.
-
5.
Rework: The lead authors updated the SRS according to the inspection protocol. The independent inspection results were used as input to capture-recapture techniques to estimate the remaining amount of work (Petersson et al., 2004). All changes are traceable through individual GitHub commits.
-
6.
Follow-up: Reviewers who previously found issues verified that those had been correctly resolved.
4.2 Presentation structure for the safety evidence
In the remainder of this paper, the AMLAS stages and the resulting artifacts act as the backbone in the presentation. Table 1 provides an overview of how those artifacts relate to the stages of AMLAS and where in this paper they are described for SMIRK. Throughout the paper, the notation [A]–[HH], in bold font, refers to the 34 individual artifacts prescribed by AMLAS. Finally, in the Appendix, the same 34 artifacts are used to present a complete safety case for the ML component in SMIRK.
5 SMIRK System Description [C]
SMIRK is a PAEB system that relies on ML. As an example of an ADAS, SMIRK is intended to act as one of several systems supporting the driver in the dynamic driving task, i.e., all the real-time operational and tactical functions required to operate a vehicle in on-road traffic. SMIRK, including the accompanying safety case, is developed with full transparency under an OSS license. We develop SMIRK as a demonstrator in a simulated environment provided by ESI Pro-SiVICFootnote 3.
The SMIRK product goal is to assist the driver on country roads in rural areas by performing emergency braking in the case of an imminent collision with a pedestrian. The level of automation offered by SMIRK corresponds to SAE Level 1: Driver Assistance, i.e., “the driving mode-specific execution by a driver assistance system of either steering or acceleration/deceleration” — in our case only braking. The first release of SMIRK is an MVP, i.e., an implementation limited to a highly restricted ODD, but, future versions might include steering and thus comply with SAE Level 2.
Sections 5 and 6 presents the core parts of the SMIRK SRS. The SRS, as well as this section, largely follows the structure proposed in IEEE 830-1998: IEEE Recommended Practice for Software Requirements Specifications (IEEE, 1998) and the template provided by Wiegers (2008). This section presents a SMIRK overview whereas Section 6 specifies the system requirements.
5.1 Product scope
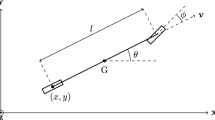
Figure 4 illustrates the overall function provided by SMIRK. SMIRK sends a brake signal when a collision with a pedestrian is imminent. Pedestrians are expected to cross the road at arbitrary angels, including perpendicular movement and moving toward or away from the car. Furthermore, a stationary pedestrian on the road must also trigger emergency braking, i.e., a scenario known to be difficult for some pedestrian detection systems. Finally, Fig. 4 stresses that SMIRK must be robust against false positives, also know as “braking for ghosts.” In this work, this refers to the ML-based component recognizing a pedestrian although another type of object is on collision course (e.g., an animal or a traffic cone) rather than radar noise. Trajectories are illustrated with blue arrows accompanied by a speed (v) and possibly an angle (\(\theta\)). In the superscript, c and p denote car and pedestrian, respectively, and 0 in the subscript indicates initial speed.

Example scenario with a pedestrian crossing the road at an arbitrary angle. A false positive is also presented, i.e., a ghost
Note that the sole purpose of SMIRK is PAEB. The design of SMIRK assumes deployment in a vehicle with complementary ADAS, e.g., large animal detection, lane keeping assistance, and various types of collision avoidance. We also expect that sensors and actuators will be shared between ADAS. For the SMIRK MVP, however, we do not elaborate further on ADAS co-existence and we do not adhere to any particular higher-level automotive architecture. In the same vein, we do not assume a central perception system that fuses various types of sensor input. SMIRK uses a standalone ML model trained for pedestrian detection and recognition. In the SMIRK terminology, to mitigate confusion, the radar detects objects and the ML-based pedestrian recognition component identifies potential pedestrians in the camera input.
The SMIRK development necessitated quality trade-offs. The software product quality model defined in the ISO/IEC 25010 standard consists of eight characteristics. Furthermore, as recommend in requirements engineering research (Horkoff, 2019), we add the two novel quality characteristics interpretability and fairness. For each characteristic, we share its importance for SMIRK by assigning it a low [L], medium [M] or high [H] priority. The priorities influence architectural decisions in SMIRK and support elicitation of architecturally significant requirements (Chen et al., 2012).
-
Functional suitability. No matter how functionally restricted the SMIRK MVP is, stated and implied needs of a prototype ADAS must be met. [H]
-
Performance efficiency. SMIRK must be able to process input, do ML inference, and commence emergency braking in realistic driving scenarios. Identifying when performance efficiency reached excessive levels is vital in the requirements engineering process. [M]
-
Compatibility. SMIRK shall be compatible with other ADAS, but, this is an ambition beyond the MVP development. [L]
-
Usability. SMIRK is an ADAS that operates in the background without a user interface for direct driver interaction. [L]
-
Reliability. A top priority in the SMIRK development that motivates the application of AMLAS. [H]
-
Security. Not included in the SOTIF scope, thus not prioritized. [L]
-
Maintainability. Evolvability from the SMIRK MVP is a key concern for future projects; thus, maintainability is important. [M]
-
Portability. We plan to port SMIRK to other simulators and physical demonstrators in the future. Initially, it is not a primary concern. [L]
-
Interpretability. While interpretability is vital for any cyber-physical system, SMIRK’s ML exacerbates the need further. [M]
-
Fairness. A vital quality that primarily impacts the data requirements specified in the Data Management Specification (Borg et al., 2021b). [H]
5.2 Product functions
SMIRK comprises implementations of four algorithms and uses external vehicle functions. In line with SOTIF, we organize all constituents into the categories sensors, algorithms, and actuators.
-
Sensors
-
Algorithms
-
Time-to-collision (TTC) calculation for objects on collision course.
-
Pedestrian detection and recognition based on the camera input where the radar detected an object (see Section 9.1).
-
Out-Of-distribution (OOD) detection of never-seen-before input (part of the safety cage mechanism, see Section 9.3).
-
A braking module that commences emergency braking. In the SMIRK MVP, maximum braking power is always used.
-
-
Actuators
-
Brakes (provided by ESI Pro-SiVIC, not elaborated further).
-
Figure 5 illustrates detection of a pedestrian on a collision course, i.e., PAEB shall be commenced. The ML-based functionality of pedestrian detection and recognition, including the corresponding OOD detection, is embedded in the Pedestrian Recognition Component (defined in Section 7.1).

Illustrative example of pedestrian detection that shall trigger emergency braking
6 SMIRK system requirements
This section specifies the SMIRK system requirements, organized into system safety requirements and ML safety requirements. ML safety requirements are further refined into performance requirements and robustness requirements. The requirements are largely re-purposed from the system for pedestrian detection at crossings described by Gauerhof et al. (2020) to our PAEB ADAS, thus allowing for comparisons to previous work within the research community.
6.1 System safety requirements [A]
-
SYS-SAF-REQ1 SMIRK shall commence automatic emergency braking if and only if collision with a pedestrian on collision course is imminent.
Rationale: This is the main purpose of SMIRK. If possible, ego car will stop and avoid a collision. If a collision is inevitable, ego car will reduce speed to decrease the impact severity. Hazards introduced from false positives, i.e., braking for ghosts, are mitigated under ML Safety Requirements.
6.2 Safety requirements allocated to ML component [E]
Based on the HARA (see Section 4), two categories of hazards were identified. First, SMIRK might miss pedestrians and fail to commence emergency braking — we refer to this as a missed pedestrian. Second, SMIRK might commence emergency braking when it should not — we refer to this as an instance of ghost braking.
-
Missed pedestrian hazard: The severity of the hazard is very high (high risk of fatality). Controllability is high since the driver can brake ego car.
-
Ghost braking hazard: The severity of the hazard is high (can be fatal). Controllability is very low since the driver would have no chance to counteract the braking.
We concluded that the two hazards shall be mitigated by ML safety requirements.
6.3 Machine learning safety requirements [H]
This section refines SYS-SAF-REQ1 into two separate requirements corresponding to missed pedestrians and ghost braking, respectively.
-
SYS-ML-REQ1. The pedestrian recognition component shall identify pedestrians in all valid scenarios when the radar tracking component returns a \(TTC < 4s\) for the corresponding object.
-
SYS-ML-REQ2 The pedestrian recognition component shall reject false positive input that does not resemble the training data.
Rationale: SYS-SAF-REQ1 is interpreted in light of missed pedestrians and ghost braking and then broken down into the separate ML safety requirements SYS-ML-REQ1 and SYS-ML-REQ2. The former requirement deals with the “if” aspect of SYS-SAF-REQ1 whereas its “and only if” aspect is targeted by SYS-ML-REQ2. SMIRK follows the reference architecture from Ben Abdessalem et al. (2016) and SYS-ML-REQ1 uses the same TTC threshold (4 s, confirmed during a research stay in Luxembourg). Moreover, we have validated that this TTC threshold is valid for SMIRK based on calculating braking distances for different car speeds. SYS-ML-REQ2 motivates the primary contribution of the SMILE III project, i.e., an OOD detection mechanism that we refer to as a safety cage.
6.3.1 Performance requirements
The performance requirements are specified with a focus on quantitative targets for the pedestrian recognition component. All requirements below are restricted to pedestrians on or close to the road.
For objects detected by the radar tracking component with a TTC \(<\) 4s, the following requirements must be fulfilled:
-
SYS-PER-REQ1 The pedestrian recognition component shall identify pedestrians with an accuracy of 93% when they are within 80 m.
-
SYS-PER-REQ2 The false negative rate of the pedestrian recognition component shall not exceed 7% within 50 m.
-
SYS-PER-REQ3 The false positives per image of the pedestrian recognition component shall not exceed 0.1% within 80 m.
-
SYS-PER-REQ4 In 99% of sequences of 5 consecutive images from a 10 FPS video feed, no pedestrian within 80 m shall be missed in more than 20% of the frames.
-
SYS-PER-REQ5 For pedestrians within 80 m, the pedestrian recognition component shall determine the position of pedestrians within 50 cm of their actual position.
-
SYS-PER-REQ6 The pedestrian recognition component shall allow an inference speed of at least 10 FPS in the ESI Pro-SiVIC simulation.
Rationale: SMIRK adapts the performance requirements specified by Gauerhof et al. (2020) for the SMIRK ODD. SYS-PER-REQ1 reuses the accuracy threshold from Example 7 in AMLAS, which we empirically validated for SMIRK — initially in a feasibility analysis, subsequently during system testing. SYS-PER-REQ2 and SYS-PER-REQ3 are two additional requirements inspired by Henriksson et al. (2019). Note that SYS-PER-REQ3 relies on the metric false positive per image rather than false positive rate as true negatives do not exist for object detection (further explained in Section 10.1 and discussed in Section 12). SYS-PER-REQ6 means that any further improvements to reaction time have a negligible impact on the total brake distance.
6.3.2 Robustness requirements
Robustness requirements are specified to ensure that SMIRK performs adequately despite expected variations in input. For pedestrians present within 50 m of Ego, captured in the field of view of the camera:
-
SYS-ROB-REQ1 The pedestrian recognition component shall perform as required in all situations Ego may encounter within the defined ODD.
-
SYS-ROB-REQ2 The pedestrian recognition component shall identify pedestrians irrespective of their upright pose with respect to the camera.
-
SYS-ROB-REQ3 The pedestrian recognition component shall identify pedestrians irrespective of their size with respect to the camera.
-
SYS-ROB-REQ4 The pedestrian recognition component shall identify pedestrians irrespective of their appearance with respect to the camera.
Rationale: SMIRK reuses robustness requirements for pedestrian detection from previous work. SYS-ROB-REQ1 is specified in Gauerhof et al. (2020). SYS-ROB-REQ2 is presented as Example 7 in AMLAS, which has been limited to upright poses, i.e., SMIRK is not designed to work for pedestrians sitting or lying on the road. SYS-ROB-REQ3 and SYS-ROB-REQ4 are additions identified during the Fagan inspection of the System Requirements Specification (see Section 4.1).
6.4 Operational design domain [B]
This section briefly describes the SMIRK ODD. As the complete ODD specification, based on the taxonomy developed by NHTSA (Thorn et al., 2018), is lengthy, we only present the fundamental aspects in this section. We refer interested readers to the GitHub repository. Note that we deliberately specified a minimalistic ODD, i.e., ideal conditions, to allow the development a complete safety case for the SMIRK MVP.
-
Physical infrastructure Asphalt single-lane roadways with clear lane markings and a gravel shoulder. Rural settings with open green fields.
-
Operational constraints Maximum speed of 70 km/h and no surrounding traffic.
-
Objects No objects except 0-1 pedestrians, either stationary or moving with a constant speed (\(<\) 15 km/h) and direction.
-
Environmental Conditions Clear daytime weather with overhead sun. Headlights turned off. No particulate matter leading to dirt on the sensors.
7 SMIRK system architecture
SMIRK is a pedestrian emergency braking ADAS that demonstrates safety-critical ML-based driving automation on SAE Level 1. The system uses input from two sensors (camera and radar/LiDAR) and implements a DNN trained for pedestrian detection and recognition. If the radar detects an imminent collision between the ego car and an object, SMIRK will evaluate if the object is a pedestrian. If SMIRK is confident that the object is a pedestrian, it will apply emergency braking. To minimize hazardous false positives, SMIRK implements a SMILE safety cage to reject input that is OOD. To ensure industrial relevance, SMIRK builds on the reference architecture from PeVi, an ADAS studied in previous work by Ben Abdessalem et al. (2016).
Explicitly defined architecture viewpoints support effective communication of certain aspects and layers of a system architecture. The different viewpoints of the identified stakeholders are covered by the established 4+1 view of architecture by Kruchten (1995). For SMIRK, we describe the logical view using a simple illustration with limited embedded semantics complemented by textual explanations. The process view is presented through a bulleted list, whereas the interested reader can find the remaining parts in the GitHub repository (RISE Research Institutes of Sweden, 2022). Scenarios are illustrated with figures and explanatory text.
7.1 Logical view
The SMIRK logical view is constituted by a description of the entities that realize the PAEB. Figure 6 provides a graphical description.

SMIRK logical view
SMIRK interacts with three external resources, i.e., hardware sensors and actuators in ESI Pro-SiVIC: A) Mono Camera (752\(\times\)480 (WVGA), sensor dimension 3.13 cm \(\times\) 2.00 cm, focal length 3.73 cm, angle of view 45 degrees), B) Radar unit (providing object tracking and relative lateral and longitudinal speeds), and C) Ego Car (An Audi A4 for which we are mostly concerned with the brake system). SMIRK consists of the following constituents. We refer to E), F), G), I), and J) as the Pedestrian Recognition Component, i.e., the ML-based component for which this study presents a safety case.
-
Software components implemented in Python:
-
D) Radar Logic (calculating TTC based on relative speeds)
-
E) Perception Orchestrator (the overall perception logic)
-
F) Rule Engine (part of the safety cage, implementing heuristics such as pedestrians do not fly in the air)
-
G) Uncertainty Manager (main part of the safety cage, implementing logic to avoid false positives)
-
H) Brake Manager (calculating and sending brake signals to the ego car)
-
-
Trained machine learning models:
-
I) Pedestrian Detector (a YOLOv5 model trained using PyTorchFootnote 4
-
J) Anomaly Detector (an autoencoder provided by SeldonFootnote 5)
-
7.2 Process view
The process view deals with the dynamic aspects of SMIRK including an overview of the run time behavior of the system. The overall SMIRK flow is as follows:
-
1.
The Radar detects an object and sends the signature to the Radar Logic class.
-
2.
The Radar Logic class calculates the TTC. If a collision between the ego car and the object is imminent, i.e., TTC is less than 4 s assuming constant motion vectors, the Perception Orchestrator is notified.
-
3.
The Perception Orchestrator forwards the most recent image from the Camera to the Pedestrian Detector to evaluate if the detected object is a pedestrian.
-
4.
The Pedestrian Detector performs a pedestrian detection in the image and returns the verdict (True/False) to the Pedestrian Orchestrator.
-
5.
If there appears to be a pedestrian on a collision course, the Pedestrian Orchestrator forwards the image and the radar signature to the Uncertainty Manager in the safety cage.
-
6.
The Uncertainty Manager sends the image to the Anomaly Detector and requests an analysis of whether the camera input is OOD or not.
-
7.
The Anomaly Detector analyzes the image in the light of the training data and returns its verdict (True/False).
-
8.
If there indeed appears to be an imminent collision with a pedestrian, the Uncertainty Manager forwards all available information to the Rule Engine for a sanity check.
-
9.
The Rule Engine does a sanity check based on heuristics, e.g., in relation to laws of physics, and returns a verdict (True/False).
-
10.
The Uncertainty Manager aggregates all information and, if the confidence is above a threshold, notifies the Brake Manager that collision with a pedestrian is imminent.
-
11.
The Brake Manager calculates a safe brake level and sends the signal to Ego Car to commence PAEB.
8 SMIRK data management specification
This section describes the overall approach to data management for SMIRK and the explicit data requirements. SMIRK is a demonstrator for a simulated environment. Thus, as an alternative to longitudinal traffic observations and consideration of accident statistics, we have analyzed the SMIRK ODD through the ESI Pro-SiVIC “Object Catalog.” We conclude that the demographics of pedestrians in the ODD is constituted of the following: adult males and females in either casual, business casual, or business casual clothes, young boys wearing jeans and a sweatshirt, and male road workers. As other traffic is not within the ODD (e.g., cars, motorcycles, and bicycles), we consider the following basic shapes from the object catalog to as examples of OOD objects (that still can appear in the ODD) for SMIRK to handle in operation: boxes, cones, pyramids, spheres, and cylinders.
8.1 Data Requirements [L]
This section specifies requirements on the data used to train and test the pedestrian recognition component. The data requirements are specified to comply with the ML Safety Requirements in the SRS. All data requirements are organized according to the assurance-related desiderata proposed by Ashmore et al. (2021), i.e., the key assurance requirements that ensure that the data set is relevant, complete, balanced, and accurate.
Table 2 shows a requirements traceability matrix between ML safety requirements and data requirements. The matrix presents an overview of how individual data requirements contribute to the satisfaction of ML Safety Requirements. Entries in individual cells denote that the ML safety requirement is addressed, at least partly, by the corresponding data requirement. SYS-PER-REQ4 and SYS-PER-REQ6 are not related to the data requirements.
8.1.1 Desideratum: relevant
This desideratum considers the intersection between the data set and the supported dynamic driving task in the ODD. The SMIRK training data will not cover operational environments that are outside of the ODD, e.g., images collected in heavy snowfall.
-
DAT-REL-REQ1 All data samples shall represent images of a road from the perspective of a vehicle.
-
DAT-REL-REQ2 The format of each data sample shall be representative of that which is captured using sensors deployed on the ego car.
-
DAT-REL-REQ3 Each data sample shall assume sensor positioning representative of the positioning used on the ego car.
-
DAT-REL-REQ4 All data samples shall represent images of a road environment that corresponds to the ODD.
-
DAT-REL-REQ5 All data samples containing pedestrians shall include one single pedestrian.
-
DAT-REL-REQ6 Pedestrians included in data samples shall be of a type that may appear in the ODD.
-
DAT-REL-REQ7 All data samples representing non-pedestrian OOD objects shall be of a type that may appear in the ODD.
Rationale: SMIRK adapts the requirements from the Relevant desiderata specified by Gauerhof et al. (2020) for the SMIRK ODD. DAT-REL-REQ5 is added based on the corresponding fundamental restriction of the ODD of the SMIRK MVP. DAT-REL-REQ7 restricts data samples providing OOD examples for testing.
8.1.2 Desideratum: complete
This desideratum considers the sampling strategy across the input domain and its subspaces. Suitable distributions and combinations of features are particularly important. Ashmore et al. (2021) refer to this as the external perspective on the data.
-
DAT-COM-REQ1 The data samples shall include the complete range of environmental factors within the scope of the ODD.
-
DAT-COM-REQ2 The data samples shall include images representing all types of pedestrians according to the demographics of the ODD.
-
DAT-COM-REQ3 The data samples shall include images representing pedestrians paces from standing still up to running at 15km/h.
-
DAT-COM-REQ4 The data samples shall include images representing all angles an upright pedestrian can be captured by the given sensors on the ego car.
-
DAT-COM-REQ5 The data samples shall include images representing all distances to crossing pedestrians from 10 up to 100 m away from ego car.
-
DAT-COM-REQ6 The data samples shall include examples with different levels of occlusion giving partial views of pedestrians crossing the road.
-
DAT-COM-REQ7 The data samples shall include a range of examples reflecting the effects of identified system failure modes.
Rationale: SMIRK adapts the requirements from the complete desiderata specified by Gauerhof et al. (2020) for the SMIRK ODD. We deliberately replaced the original adjective “sufficient” to make the data requirements more specific. Furthermore, we add DAT-COM-REQ3 to cover different poses related to the pace of the pedestrian and DAT-COM-REQ4 to cover different observation angles.
8.1.3 Desideratum: balanced
This desideratum considers the distribution of features in the data set, e.g., the balance between the number of samples in each class. Ashmore et al. (2021) refer to this as an internal perspective on the data.
-
DAT-BAL-REQ1 The data set shall have a representation of samples for each relevant class and feature that ensures AI fairness with respect to gender.
-
DAT-BAL-REQ2 The data set shall have a representation of samples for each relevant class and feature that ensures AI fairness with respect to age.
-
DAT-BAL-REQ3 The data set shall contain both positive and negative examples.
Rationale: SMIRK adapts the requirements from the Balanced desiderata specified by Gauerhof et al. (2020) for the SMIRK ODD. The concept of AI fairness is to be interpreted in the light of the Ethics guidelines for trustworthy AI published by the European Commission (High-Level Expert Group on Artificial Intelligence, 2019). Note that the number of ethical dimensions that can be explored in through the ESI Pro-SiVIC object catalog is limited to gender (DAT-BAL-REQ1) and age (DAT-BAL-REQ2). Moreover, the object catalog does only contain male road workers and all children are boys. Furthermore, DAT-BAL-REQ3 is primarily included to align with Gauerhof et al. (2020) and to preempt related questions by safety assessors. In practice, the concept of negative examples when training object detection models are typically satisfied implicitly as the parts of the images that do not belong to the annotated class are true negatives (further explained in Section 10.1).
8.1.4 Desideratum: accurate
This desideratum considers how measurement issues can affect the way that samples reflect the intended ODD, e.g., sensor accuracy and labeling errors.
-
DAT-ACC-REQ1: All bounding boxes produced shall include the entirety of the pedestrian.
-
DAT-ACC-REQ2: All bounding boxes produced shall be no more than 10% larger in any dimension than the minimum sized box capable of including the entirety of the pedestrian.
-
DAT-ACC-REQ3: All pedestrians present in the data samples shall be correctly labeled.
Rationale: SMIRK reuses the requirements from the Accurate desiderata specified by Gauerhof et al. (2020).
8.2 Data generation log [Q]
This section describes how the data used for training the ML model in the pedestrian recognition component was generated. Based on the data requirements, we generate data using ESI Pro-SIVIC. The data are split into three sets in accordance with AMLAS.
-
Development data: Covering both training and validation data used by developers to create models during ML development.
-
Internal test data: Used by developers to test the model.
-
Verification data: Used in the independent test activity when the model is ready for release.
The SMIRK data collection campaign focuses on generation of annotated data in ESI Pro-SiVIC. All data generation is script-based and fully reproducible. Section 8.2.1 describes positive examples (PX), i.e., humans that shall be classified as pedestrians. Section 8.2.2 describes examples that represent OOD shapes (NX), i.e., objects that shall not initiate PAEB in case of an imminent collision. These images, referred to as OOD examples, shall either not be recognized as a pedestrian or be rejected by the safety cage (see Section 9.3).
In the data collection scripts, ego car is always stationary whereas pedestrians and objects move according to specific configurations. The parameters and values were selected to systematically cover the ODD. Finally, images are sampled from the camera at 10 frames per second with a resolution of \(752 \times 480\) pixels. For each image, we add a separate image file containing the ground truth pixel-level annotation of the position of the pedestrian. In total, we generate data representing \(8 \times 616 = 4928\) execution scenarios with positive examples and \(5 \times 20 = 100\) execution scenarios with OOD examples. In total, the data collection campaign generates roughly 185 GB of image data, annotations, and meta-data (including bounding boxes).
8.2.1 Positive examples
We generate positive examples from humans with eight visual appearances (see the upper part of Fig. 7) available in the ESI Pro-SiVIC object catalog:
- P1:
-
Casual female pedestrian
- P2:
-
Casual male pedestrian
- P3:
-
Business casual female pedestrian
- P4:
-
Business casual male pedestrian
- P5:
-
Business female pedestrian
- P6:
-
Business male pedestrian
- P7:
-
Child
- P8:
-
Male construction worker
For each of the eight visual appearances, we specify the execution of 616 scenarios in ESI Pro-SiVIC organized into four groups (A–D). The pedestrians always follow rectilinear motion (a straight line) at a constant speed during scenario execution. Groups A and B describe pedestrians crossing the road, either from the left (group A) or from the right (group B). There are three variation points, i.e., (1) the speed of the pedestrian, (2) the angle at which the pedestrian crosses the road, and (3) the longitudinal distance between ego car and the pedestrian’s starting point. In all scenarios, the distance between the starting point of the pedestrian and the edge of the road is 5 m.
-
A. Crossing the road from left to right (4 \(\times\) 7 \(\times\) 10 = 280 scenarios)
-
Speed (m/s): [1, 2, 3, 4]
-
Angle (degree): [30, 50, 70, 90, 110, 130, 150]
-
Longitudinal distance (m): [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
-
-
B. Crossing the road from right to left (4 \(\times\) 7 \(\times\) 10 = 280 scenarios)
-
Speed (m/s): [1, 2, 3, 4]
-
Angle (degree): [30, 50, 70, 90, 110, 130, 150]
-
Longitudinal distance (m): [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
-
Groups C and D describe pedestrians moving parallel to the road, either toward ego car (group C) or away (group D). There are two variation points, i.e., (1) the speed of the pedestrian and (2) an offset from the road center. The pedestrian always moves 90 m, with a longitudinal distance between ego car and the pedestrian’s starting point of 100 m for group C (towards) and 10 m for group D (away).
-
C. Movement parallel to the road toward ego car (4 \(\times\) 7= 28 scenarios)
-
Speed (m/s): [1, 2, 3, 4]
-
Lateral offset (m): [−3, −2, −1, 0, 1, 2, 3]
-
-
D. Movement parallel to the road away from ego car (4 \(\times\) 7= 28 scenarios)
-
Speed (m/s): [1, 2, 3, 4]
-
Lateral offset (m): [−3, −2, −1, 0, 1, 2, 3]
-
8.2.2 Out-of-distribution examples
We generate OOD examples using five basic shapes (see the lower part of Fig. 7) available in the ESI Pro-SiVIC object catalog:
- N1:
-
Sphere
- N2:
-
Cube
- N3:
-
Cone
- N4:
-
Pyramid
- N5:
-
Cylinder
For each of the five basic shapes, we specify the execution of 20 scenarios in ESI Pro-SiVIC. The scenarios represent a basic shape crossing the road from the left or right at an angle perpendicular to the road. Since basic shapes are not animated, we fix the speed at 4 m/s. Moreover, as lateral offsets and different angles make little to no difference in front of the camera, we disregard these variation points. In all scenarios, the distance between the starting point of the basic shape and the edge of the road is 5 m. The only variation points are the crossing direction and the longitudinal distance between ego car and the objects’ starting point. As for pedestrians, the objects always follow a rectilinear motion at a constant speed during scenario execution.
-
Crossing direction: [left, right]
-
Longitudinal distance (m): [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]

Visual appearance of pedestrians (P1–P8) and basic shapes (N1–N5)
8.2.3 Preprocessing and data splitting
As the SMIRK data collection campaign relies on data generation in ESI Pro-SiVIC, the need for pre-processing differs from counterparts using naturalistic data. The script-based data generation ensures that the crossing pedestrians and objects appear at the right distance with specified conditions and with controlled levels of occlusion. All output images share the same characteristics; thus, no normalization is needed. SMIRK includes a script to generate bounding boxes for training the object detection model. ESI Pro-SiVIC generates ground truth image segmentation on a pixel-level. The script is used to convert the output to the appropriate input format for model training.
The development data contains images with no pedestrians, in line with the description of “background images” in the YOLOv5 training tips provided by UltralyticsFootnote 6. Background images have no objects for the model to detect, and are added to reduce FPs. Ultralytics recommends 0–10% background images to help reduce FPs and reports that the fraction of background images in the well-known COCO data set is 1% (Lin et al., 2014). In our case, we add background images with cylinders (N5) to the development data. In total, the SMIRK development data contains 1.98% background images, i.e., 1.75% images without any objects and 0.23% with a cylinder.
The generated data are used in three sequestered (separated) data sets:
-
Development data: P2, P3, P6, and N5
-
Internal test data: P1, P4, N1, and N3
-
Verification data: P5, P7, P8, N2, and N4
Note that we deliberately avoid mixing pedestrian models from the ESI Pro-SiVIC object catalog in the data sets due to the limited diversity in the images within the ODD.
9 Machine learning component specification
The pedestrian recognition component consists of two ML-based constituents: a pedestrian detector and an anomaly detector (see Fig. 6).
9.1 Pedestrian detection using YOLOv5s
SMIRK implements its pedestrian recognition component using the third-party OSS framework YOLOv5 by Ultralytics. Based on Ultralytics’ publicly reported experiments on real-time characteristics of different YOLOv5 architecturesFootnote 7, we found that YOLOv5s stroke the best balance between inference time and accuracy for SMIRK. After validating the feasibility in our experimental setup, we proceeded with this ML architecture selection.
The pedestrian recognition component uses the YOLOv5 architecture without any modifications. YOLOv5s has 191 layers and \(\approx\)7.5 million parameters. We use the default configurations proposed in YOLOv5s regarding activation, optimization, and cost functions. As activation functions, YOLOv5s uses Leaky ReLU in the hidden layers and the sigmoid function in the final layer. We use the default optimization function in YOLOv5s, i.e., stochastic gradient descent. The default cost function in YOLOv5s is binary cross-entropy with logits loss as provided in PyTorch, which we also use. We refer the interested reader to further details provided by Rajput (2020) and Ultralytics’ GitHub repository.
9.2 Model development log [U]
This section describes how the YOLOv5s model has been trained for the SMIRK MVP. We followed the general process presented by Ultralytics for training on custom data.
First, we manually prepared two SMIRK data sets to match the input format of YOLOv5. In this step, we also divided the development data [N] into two parts. The first part containing approximately 80% of development data, was used for training. The second part, consisting of the remaining data, was used for validation. Camera frames from the same video sequence were kept together in the same partition to avoid having almost identical images in the training and validation sets. Additionally, we kept the distribution of objects and scenario types consistent in both partitions. The internal test data [O] was used as a test set. We then prepared these three data sets, training, validation, and test, according to Ultralytic’s instructions and trained YOLOv5 for a single class, i.e., pedestrians. The data sets were already annotated using ESI Pro-SiVIC; thus, we only needed to export the labels to the YOLO format with one txt-file per image. Finally, we organize the individual files (images and labels) according to the YOLOv5 instructions. More specifically, each label file contains the following information:
-
One row per object.
-
Each row contains class, x_center, y_center, width, and height.
-
Box coordinates are stored in normalized xywh format (from 0 to 1).
-
Class numbers are zero-indexed, i.e., they start from 0.
Second, we trained a YOLO model using the YOLOv5s architecture with the development data without any pre-trained weights. The model was trained for 10 epochs with a batch-size of 8. The results from the validation subset (27,843 images in total) of the development data guide the selection of the confidence threshold for the ML model. We select a threshold to meet SYS-PER-REQ3 with a safety margin for the development data, i.e., an FPPI of 0.1%. This yields a confidence threshold for the ML model to classify an object as a pedestrian that equals 0.448. The final pedestrian detection model, i.e., the ML model [V], has a size of \(\approx\) 14 MB.
9.3 OOD detection for the safety cage architecture
SMIRK detects OOD input images as part of its safety cage architecture. The OOD detection relies on the OSS third-party library Alibi DetectFootnote 8 from Seldon. Alibi Detect is a Python library that provides several algorithms for outlier, adversarial, and drift detection for various types of data (Klaise et al., 2020). For SMIRK, we trained Alibi Detect’s autoencoder for outlier detection, with three convolutional and deconvolutional layers for the encoder and decoder respectively.
Figure 8 shows an overview of the DNN architecture of an autoencoder. An encoder and a decoder are trained jointly in two steps to minimize a reconstruction error. First, the autoencoder receives input data X and encodes it into a latent space of fewer dimensions. Second, the decoder tries to reconstruct the original data and produces output \(X'\). An and Cho (2015) proposed using the reconstruction error from a autoencoder to identify input that differs from the training data. Intuitively, if inlier data is processed by the autoencoder, the difference between X and \(X'\) will be smaller than for outlier data, i.e., OOD data will stand out. By carefully selecting a tolerance threshold, this approach can be used for OOD detection.

Overview architecture of an autoencoder. Adapted from WikiUser:EugenioTL (CC BY-SA 4.0)
For SMIRK, we trained Alibi Detect’s autoencoder for OOD detection on the training data subset of the development data. The encoder part is designed with three convolutional layers followed by a dense layer resulting in a bottleneck that compresses the input by 96.66%. The latent dimension is limited to 1,024 variables to limit requirements on processing VRAM of the GPU. The reconstruction error from the autoencoder is measured as the mean squared error between the input and the reconstructed instance. The mean squared error is used for OOD detection by computing the reconstruction error and considering an input image as an outlier if the error surpasses a threshold \(\theta\). The threshold used for OOD detection in SMIRK is 0.004, roughly corresponding to the threshold that rejects a number of samples that equals the amount of outliers in the validation set. As explained in Section 11.4, the OOD detection is only active for objects at least 10 m away from ego car as the results for close-up images are highly unreliable. Furthermore, as the constrained SMIRK ODD ensures that only one single object appears in each scenario, the safety cage architecture applies the policy “once an anomaly, always an anomaly” — objects that get rejected once will remain anomalous no matter what subsequent frames might contain.
10 SMIRK system test specification
This section describes the overall SMIRK test strategy. The ML-based pedestrian recognition component is tested on multiple levels. We focus on four aspects of the ML testing scope facet proposed by Song et al. (2022):
-
Data set testing: This level refers to automatic checks that verify that specific properties of the data set are satisfied. As described in the ML Data Validation Results, the data validation, presented in Section 11.1, includes automated testing of the Balance desiderata. Since the SMIRK MVP relies on synthetic data, the distribution of pedestrians is already ensured by the scripts. However, other distributions such as distances to objects and bounding box sizes are important targets for data set testing.
-
Model testing: Testing that the ML model provides the expected output. This is the primary focus of academic research on ML testing, and includes white-box, black-box, and data-box access levels during testing (Riccio et al., 2020). SMIRK model testing is done independently from model development and results in ML Verification Results [Z] as described in Section 11.2.2.
-
Unit testing: Conventional unit testing on the level of Python classes. A test suite developed for the pytest framework is maintained by the developers and not elaborated further in this paper.
-
System testing: System-level testing of SMIRK based on a set of Operational Scenarios [EE]. All test cases are designed for execution in ESI Pro-SiVIC. The system testing targets the requirements in the System Requirements Specification. This level of testing results in Integration Testing Results [FF] presented in Section 11.3.
10.1 ML model testing [AA]
This section corresponds to the Verification Log [AA] in AMLAS Step 5, i.e., Model Verification Assurance. Here we explicitly document the ML Model testing strategy, i.e., the range of tests undertaken and bounds and test parameters motivated by the SMIRK system requirements.
The testing of the ML model is based on assessing the object detection accuracy for the sequestered verification data set. A fundamental aspect of the verification argument is that this data set was never used in any way during the development of the ML model. To further ensure the independence of the ML verification, engineers from Infotiv, part of the SMILE III research consortium, led the corresponding verification and validation work package and were not in any way involved in the development of the ML model. As described in the Machine Learning Component Specification (see Section 9), the ML development was led by Semcon with support from RISE Research Institutes of Sweden.
The ML model test cases provide results for both 1) the entire verification data set and 2) eight slices of the data set that are deemed particularly important. The selection of slices was motivated by either an analysis of the available technology or ethical considerations, especially from the perspective of AI fairness (Borg et al., 2021b). Consequently, we measure the performance for the following slices of data. Identifiers in parentheses show direct connections to requirements.
- S1:
-
The entire verification data set
- S2:
-
Pedestrians close to the ego car (longitudinal distance \(<\) 50 m) (SYS-PER-REQ1, SYS-PER-REQ2)
- S3:
-
Pedestrians far from the ego car (longitudinal distance \(\ge\) 50 m)
- S4:
-
Running pedestrians (speed \(\ge\) 3 m/s) (SYS-ROB-REQ2)
- S5:
-
Walking pedestrians (speed 0 m/s but \(<\) 3 m/s) (SYS-ROB-REQ2)
- S6:
-
Occluded pedestrians (entering or leaving the field of view, defined as bounding box in contact with any edge of image) (DAT-COM-REQ4)
- S7:
-
Male pedestrians (DAT-COM-REQ2)
- S8:
-
Female pedestrians (DAT-COM-REQ2)
- S9:
-
Children (DAT-COM-REQ2)
Evaluating the output from an object detection model in computer vision is non-trivial. We rely on the established IoU metric to evaluate the accuracy of the YOLOv5 model. After discussions in the development team, supported by visualizationsFootnote 9, we set the target at 0.5. We recognize that there are alternative measures tailored for pedestrian detection, such as the log-average miss rate (Dollar et al., 2011) but we find such metrics to be unnecessarily complex for the restricted SMIRK ODD with a single pedestrian. There are also entire toolboxes that can be used to assess object detection (Bolya et al., 2020). Whereas more complex metrics could be used, we decide to use IoU in SMIRK’s safety argumentation. Relying on a simpler metric supports interpretability, which is a vital to any safety case, especially if ML is involved (Jia et al., 2022).
Even using the standard IoU metric to assess how accurate SMIRK’s ML model is, the evaluation results are not necessarily intuitive to non-experts. Each image in the SMIRK data set either has a ground truth bounding box containing the pedestrian or no bounding box at all. Similarly, when performing inference on an image, the ML model will either predict a bounding box containing a potential pedestrian or no bounding box at all. IoU is the intersection over the union of the two bounding boxes. An IoU of 1 implies a perfect overlap. For the ML model in SMIRK, we evaluate pedestrian detection at IoU = 0.5, which for each image means:
- TP:
-
True positive: IoU \(\ge\) 0.5
- FP:
-
False positive: IoU \(<\) 0.5
- FN:
-
False negative: There is a ground truth bounding box in the image, but no predicted bounding box.
- TN:
-
True negative: All parts of the image with neither a ground truth nor a predicted bounding box. This output carries no meaning in our case.
Figure 9 shows predictions from the the ML model. The green rectangles show the ground truth and the red rectangles show ML model’s prediction of where a pedestrian is present. The left example is a FP since IoU=0.3 with a predicted box substantially smaller than the ground truth. On the other hand, the ground truth is questionable, as there probably is only a single pixel containing the pedestrian below the visible arm that drastically increases the size of the green box. The center example is a TP with IoU=0.9, i.e., the overlap between the boxes is very large. The right example is another FP with IoU=0.4 where the predicted box is much larger than the ground truth. These examples show that FPs during model testing do not directly translate to FPs on the system level as discussed in the HARA (Safety Requirements Allocated to ML Component [E]). If any of the objects within the red bounding boxes were on a collision course with the ego car, commencing PAEB would indeed be the right action for SMIRK and thus not violate SYS-SAF-REQ1. This observation corroborates the position by (Haq et al., 2021b), i.e., system level testing that goes beyond model testing on single frames is critically needed.

Example predictions from the SMIRK ML model. The center image represents a TP, whereas the left and right examples are FPs with IoU scores of 0.3 and 0.4, respectively
All results from running ML model testing, i.e., ML Verification Results [Z], are documented in the Protocols folder.
10.2 System level testing
System-level testing of SMIRK involves integrating the ML model into the pedestrian recognition component and the complete PAEB ADAS. We do this by defining a set of Operational Scenarios [EE] for which we assess the satisfaction of the ML Safety Requirements. The results from the system-level testing, i.e., the Integration Testing Results [FF], are presented in Section 11.3.
10.2.1 Operational scenarios
SOTIF defines an operational scenario as “a description of an imagined sequence of events that includes the interaction of the product or service with its environment and users, as well as interaction among its product or service components.” Consequently, the set of operational scenarios used for testing SMIRK on the system level must represent the diversity of real scenarios that may be encountered when SMIRK is in operation. Furthermore, for testing purposes, it is vital that the set of defined scenarios are meaningful with respect to the verification of SMIRK’s safety requirements.
As SMIRK is designed to operate in ESI Pro-SiVIC, the difference between defining operational scenarios in text and implementation scripts to execute the same scenarios in the simulated environment is very small. We will not define any operational scenarios that cannot be scripted for execution in ESI Pro-SiVIC. To identify a meaningful set of operational scenarios, we use equivalence partitioning as proposed by Masuda (2017) as one approach to limit the number of test scenarios to execute in vehicle simulators. Originating in the equivalence classes, we use combinatorial testing to reduce the set of operational scenarios. Using combinatorial testing to create test cases for system testing of a PAEB testing in a vehicle simulator has previously been reported by Tao et al. (2019). We create operational scenarios that provide complete pair-wise testing of SMIRK considering the identified equivalence classes using the AllPairs test combinations generatorFootnote 10.
Based on an analysis of the ML Safety Requirements and the Data Requirements, we define operational scenarios addressing SYS-ML-REQ1 and SYS-ML-REQ2 separately. For each subset of operational scenarios, we identify key variation dimensions (i.e., parameters in the test scenario generation) and split dimensions into equivalence classes using explicit ranges. Note that ESI Pro-SiVIC enables limited configurability of basic shapes compared to pedestrians; thus, the corresponding number of operational scenarios is lower.
Operational Scenarios for SYS-ML-REQ1:
-
Pedestrian starting point (lateral offset from the road in meters): Left side of the road (−5 m), Center of the road (0 m), Right side of the road (5 m)
-
Longitudinal distance from ego car (offset in meters): Close distance (\(<\) 25 m), Medium distance (25–50 m), Far away ( 50 m)
-
Pedestrian appearance: Female casual, Male business casual, Male business, Female business, Child, Male worker
-
Pedestrian speed (m/s): Stationary (0 m/s), Slow (1 m/s), Fast (3 m/s)
-
Pedestrian crossing angle (degrees): Toward ego car (0), Diagonal toward (45), Perpendicular (90), Diagonal away (135), Away from car (180)
-
Ego car speed (m/s): Slow (\(<\) 10 m/s), Medium (10–15 m/s), Fast (15–20 m/s)
The dimensions and ranges listed above result in 2430 possible combinations. Using combinatorial testing, we create a set of 25 operational scenarios that provides pair-wise coverage of all equivalence classes.
Operational Scenarios for SYS-ML-REQ2:
-
Object starting point (lateral offset from the road in meters): Left side of the road (−5 m), On the road (0 m), Right side of the road (5 m)
-
Longitudinal distance from ego car (offset in meters): Close (\(<\) 25 m), Medium distance (25–50 m), Far away ( 50 m)
-
Object appearance: Sphere, Cube, Cone, Pyramid
-
Object speed (m/s): Stationary (0 m/s), Slow (1 m/s), Fast (3 m/s)
-
Ego car speed (m/s): Slow (\(<\)10 m/s), Medium (10–15 m/s), Fast (15–20 m/s)
The dimensions and ranges listed above result in 324 possible combinations. Using combinatorial testing, we create a set of 13 operational scenarios that provides pair-wise coverage of all equivalence classes.
For each operational scenario, two test parameters represent ranges of values, i.e., the longitudinal distance between ego car and the pedestrian and the speed of ego car. For these two test parameters, we identify a combination of values that result in a collision unless SMIRK initiates emergency braking. Table 3 shows an overview of the 38 operational scenarios, whereas all details are available as executable test scenarios in the GitHub repository.
10.2.2 System test cases
The system test cases are split into three categories. First, each operational scenario identified in Section 10.2.1 constitutes one system test case, i.e., Test Cases 1–38. Second, to increase the diversity of the test cases in the simulated environment, we complement the reproducible Test Cases 1–38 with test case counterparts adding random jitter to the parameters. For Test Cases 1–38, we create analogous test cases that randomly add jitter in the range from −10 to +10% to all numerical values. Partial random testing has been proposed by Masuda (2017) in the context of test scenarios execution in vehicle simulators. Note that introducing random jitter to the test input does not lead to the test oracle problem (Barr et al., 2014), as we can automatically assess whether there is a collision between ego car and the pedestrian without emergency braking in ESI Pro-SiVIC or not (TC-RAND-[1-25]). Furthermore, for the test cases related to provoking ghost braking, we know that emergency braking shall not commence.
The third category is requirements-based testing (RBT). RBT is used to gain confidence that the functionality specified in the ML Safety Requirements has been implemented correctly (Hauer et al., 2019). The top-level safety requirement SYS-SAF-REQ1 will be verified by testing of all underlying requirements, i.e., its constituent detailed requirements. The test strategy relies on demonstrating that SYS-ML-REQ1 and SYS-ML-REQ2 are satisfied when executing TC-OS-[1-38] and TC-RAND-[1-38]. SYS-PER-REQ1–SYS-PER-REQ5 and SYS-ROB-REQ1–SYS-ROB-REQ4 are verified through the model testing described in Section 10.1. The remaining performance requirement SYS-PER-REQ6 is verified by TC-REQ-3. Table 4 lists all system test cases, of all three categories, using the Given-When-Then structure as used in behavior-driven development (Tsilionis et al., 2021). For the test cases TC-RBT-[1-3], the “Given” condition is that all metrics have been collected during execution of TC-OS-[1-38] and TC-RAND-[1-38]. The set includes seven metrics:
-
1.
MinDist: Minimum distance between ego car and the pedestrian during a scenario.
-
2.
TimeTrig: Time when the radar tracking component first returned TTC \(<\) 4 s for an object.
-
3.
DistTrig: Distance between ego car and the object when the radar component first returned TTC \(<\) 4 s for an object.
-
4.
TimeBrake: Time when emergency braking was commenced.
-
5.
DistBrake: Distance between ego car and the object when emergency braking commenced.
-
6.
Coll: Whether a scenario involved a collision between ego car and a pedestrian.
-
7.
CollSpeed: Speed of ego car at the time of collision.
11 SMIRK test results
This section presents the most important test results from three levels of ML testing, i.e., data testing, model testing, and system testing. Complete test reports are available in the protocols subfolder on GitHubFootnote 11. Moreover, this section presents the Erroneous Behavior Log.
11.1 Results from data testing [S]
This section describes the results from testing the SMIRK data set. The data testing primarily involves a statistical analysis of its distribution and automated data validation using Great ExpectationsFootnote 12. Together with the outcome of the Fagan inspection of the Data Management Specification (described in Section 4.1), this constitutes the ML Data Validation Results in AMLAS. As depicted later in Fig. 19, the results entail evidence mapping to the four assurance-related desiderata, i.e., we report a validation of (1) data relevance, (2) data completeness, (3) data balance, and (4) data accuracy. Since we generate synthetic data using ESI Pro-SiVIC, data relevance has been validated through code reviews and data accuracy is implicit as the tool’s ground truth is used. For both the relevance and accuracy desiderata, we have manually analyzed a sample of the generated data to verify requirements satisfaction.
We validate the ethical dimension of the data balance by analyzing the gender (DAT-BAL-REQ1) and age (DAT-BAL-REQ2) distributions of the pedestrians in the SMIRK data set. SMIRK evolves as a demonstrator in a Swedish research project, which provides a frame of reference for this analysis. Table 5 shows how the SMIRK data set compares to Swedish demographics from the perspective of age and gender. The demographics originate in a study on collisions between vehicles and pedestrians by the Swedish Civil Contingencies Agency (Schyllander, 2014). We notice that (1) children are slightly over-represented in accidents but under-represented in deadly accidents, and that (2) adult males account for over half of the deadly accidents in Sweden. The rightmost column shows the distribution of pedestrian types in the entire SMIRK data set. We designed the SMIRK data generation process to result in a data set that resembles the deadly accidents in Sweden, but, motivated by AI fairness, we increased the fraction of female pedestrians to mitigate a potential gender bias. Finally, as discussed in Section 8.2.3, code reviews confirmed that the development data contains roughly 2% “background images.”
Automated data testing is performed by defining conditions that shall be fulfilled by the data set. These conditions are checked against the existing data and any new data that is added. Some tests are fixed and simple, such as expecting the dimensions of input images to match the ones produced by the vehicle’s camera. Similarly, all bounding boxes are expected to be within the dimensions of the image. Other tests look at the distribution and ranges of values to assure the completeness, accuracy, and balance of the data set and catch human errors. This includes validating enough coverage of pedestrians at different positions of the image, coverage of varying range of pedestrian distances, and bounding box aspect ratios. For values that are hard to define rules for, a known good set of inputs can be used as a starting point and remaining and new inputs can be checked to against these reference inputs. As an example, this can be used to verify that the color distribution and pixel intensity are within expected ranges. This can be used to identify images that are too dark or dissimilar to existing images.
Figure 10 shows a selection of summary plots from the data testing that support our claims for data validity, in particular from the perspective of data completeness. Figure 10a presents the distance distribution between ego car and pedestrians, verifying that the data set contains pedestrians at distances 10–100 m (DAT-COM-REQ5). Figure 10b shows a heatmap of the bounding boxes’ centers captures by the 752×480 WVGA camera. We confirm that pedestrians appear from the sides of the field of view and a larger fraction of images contain a pedestrian just in front of ego car. The position distribution supports our claim that DAT-COM-REQ4 is satisfied, i.e., the data samples represent different camera angles. Figure 10c shows a heatmap of bounding box dimensions, i.e., different aspect ratios. A variety of aspect ratios indicate that pedestrians move with a diversity of arm and leg movements — indicating walking and running — and thus support our claim that DAT-COM-REQ3 is fulfilled. Finally, Fig. 10d shows the color histogram of the data set. In the automated data testing, we use this as a reference value when adding new images to ensure that they match the ODD. For example, a sample of nighttime images would have a substantially different color distribution.

Four visualizations from the data testing showing distributions of (a) the distance between ego car and the pedestrian, (b) the center position of the bounding box, (c) the bounding box dimension, and (d) colors.
11.2 Results from model testing
This section is split into results from testing done during development and the subsequent independent verification. Throughout this section, the following abbreviations are used for a set of standard evaluation metrics: Precision (P), Recall (R), F1-score (F1), Intersection over Union (IoU), True Positive (TP), False Positive (FP), FPs Per Image (FPPI), False Negative (FN), and Average Precision for IoU at 0.5 (AP@0.5), and Confidence (Conf).
11.2.1 Internal test results [X]
In this section, we present the most important results from the internal testing. These results provide evidence that the ML model satisfies the ML safety requirements (see Section 6.3) on the internal test data. The total number of images in the internal test data is 139,526 (135,139 pedestrians (96.9%) and 4,387 non-pedestrians (3.1%)). As described in Section 10.1, Fig. 11 depicts four subplots representing IoU = 0.5: A) P vs. R, B) F1 vs. Conf, C) P vs. Conf, and D) R vs. Conf. Figure 11a shows that the ML model is highly accurate, i.e., the unavoidable discrimination-efficiency tradeoff of object detection (Wu & Nevatia, 2008) is only visible in the upper right corner. Figure 11b–d show how P, R, and F1 vary with different Conf thresholds. Table 6 presents further details of the accuracy of the ML model for the selected Conf threshold, organized into (1) all distances from the ego car, (2) within 80 m, and (3) within 50 m, respectively. The table also shows the effect of adding OOD detection using the autoencoder, i.e., a substantially reduced number of FPs.

Evaluation of the ML model on the internal test data at IoU = 0.5, i.e., (a) P-R curve, (b) F1 vs. Conf, (c) P vs. Conf., and (d) R vs. Conf.
Table 7 demonstrates how the ML model satisfies the performance requirements on the internal test data. First, the TP rate (95.9%) and the FN rate (0.31%) for the respective distances meet the requirements. The model’s FPPI (0.42%), on the other hand, is too high to meet SYS-PER-REQ3 as we observed 444 FPs (cones outnumber spheres by 2:1). This observation reinforces the need to use a safety cage architecture, i.e., OOD detection that can reject input that does not resemble the training data. The rightmost column in Table 7 shows how the FPPI decreased to 0.012% with the autoencoder. All basic shapes were rejected, but 13 images with pedestrians led to FPs within the ODD due to too low IoU scores.
SYS-PER-REQ4 is met as the fraction of rolling windows with more than a single FN is 0.24%, i.e., \(\le\) 3%. Figure 12 shows the distribution of position errors in the object detection for pedestrians within 80 m of ego car, i.e., the difference between the object detection position and ESI Pro-SiVIC ground truth. The median error is 1.0 cm, the 99% percentile is 5.6 cm, and the largest observed error is 12.7 cm. Thus, we show that SYS-PER-REQ5 is satisfied for the internal test data, i.e., \(\le\) 50 cm position error for pedestrian detection within 80 m. Note that satisfaction of SYS-PER-REQ6, i.e., sufficient inference speed, is demonstrated as part of the system testing reported in Section 11.3. The complete test report is available on GitHub.

Distribution of position errors for the internal test data
Table 8 presents the output of the ML model on the eight slices of internal test data defined in Section 10.1. Note that we saved the children in the ESI Pro-SiVIC object catalog for the verification data, i.e., S9 does not exist in the internal test data. Apart from the S6 slice with occlusion, the model accuracy is consistent across the slices which corroborates satisfaction of the robustness requirements on the internal test data, e.g., in relation to pose (SYS-ROB-REQ2), size (SYS-ROB-REQ2), and appearance (SYS-ROB-REQ2).
11.2.2 ML verification results [Z]
This section reports the key findings from conducting the independent ML model testing, i.e., the Verification Log in the AMLAS terminology. These results provide independent evidence that the ML model satisfies the ML safety requirements (see Section 6.3) on the verification data. The total number of images in the verification data is 208,884 (202,712 pedestrians (97.0%) and 6,172 non-pedestrians (3.0%)). Analogous to Section 11.2.1, Fig. 13 depicts four subfigures representing IoU = 0.5: P vs. R (cf. Fig. 13a), F1 vs. Conf (cf. Fig. 13b), P vs. Conf (cf. Fig. 13c), and R vs. Conf (cf. Fig. 13d). We observe that the appearance of the four subfigures closely resembles the corresponding plots for the internal test data (cf. Fig. 11).

Evaluation of the ML model on the verification data at IoU=0.5, i.e., (a) P-R curve, (b) F1 vs. Conf., (c) P vs. Conf., and (d) R vs. Conf.
Table 9 shows the output from the ML model using the Conf threshold 0.448 on the verification data. The table is organized into (1) all distances from the ego car, (2) within 80 m, and (3) within 50 m, respectively. The table also shows the effect of adding OOD detection using the autoencoder, i.e., the number of FPs is decreased just as for the internal test data. Table 10 demonstrates how the ML model satisfies the performance requirements on the verification data. Similar to the results for the internal test data, the FPPI (0.21%) is too high to satisfy SYS-PER-REQ3 without additional OOD detection, i.e., we observed 330 FPs (roughly an equal share of pyramids and children). The rightmost column in Table 10 shows how the FPPI decreased to 0.015% with the autoencoder. All basic shapes were rejected, instead children at a long distance with too low IoU scores dominate the FPs. We acknowledge that it is hard for the YOLOv5 to achieve a high IoU for the few pixels representing a child almost 80 m away. However, commencing emergency braking in such cases is an appropriate action — a child detected with a low IoU is not an example of the ghost braking hazard described in Section 6.2. SYS-PER-REQ4 is satisfied as the fraction of rolling windows with more than a single FN is 2.3%. Figure 14 shows the distribution of position errors. The median error is 1.0 cm, the 99% percentile is 5.4 cm, and the largest observed error is 12.8 cm. Consequently, we show that SYS-PER-REQ5 is satisfied for the verification data.

Distribution of position errors for the verification data
Table 12 presents the output of the ML model on the nine slices of the verification data defined in Section 10.1. In relation to the robustness requirements, we notice that there the accuracy is slightly lower for S9 (children). This finding is related to the size requirement SYS-ROB-REQ3. Table 11 contains an in-depth analysis of children at different distances with OOD detection. We confirm that most FPs occur outside of the ODD, i.e., 507 out of 512 FPs occur for children more than 80 m from ego car. In extension, we show that the performance requirements are still satisfied for the most troublesome slice of data as follows:
-
TP rate children \(\le 80 m\): \(\frac{50,402}{50,696} = 99.4\%\)
-
FN rate children \(\le 50 m\): \(\frac{249}{30,731} = 0.81\%\)
-
FPPI children \(\le 80 m\): \(\frac{5}{52,463} = 0.0099\%\)
The independent verification concludes that all requirements are met, based on the same argumentation as for the internal test results. The complete verification report is available on GitHub.
11.3 Results from system testing [FF]
This section presents an overview of the results from testing SMIRK in ESI Pro-SiVIC, which corresponds to the Integration Testing Results in AMLAS. As explained in Section 10.2.2, we measure seven metrics for each test case execution, i.e., MinDist, TimeTrig, DistTrig, TimeBrake, DistBrake, Coll, and CollSpeed.
Table 13 presents the results from executing the test cases representing operational scenarios with pedestrians, i.e., TC-OS-[1–25]. From the left, the columns show (1) test case ID, (2) the minimum distance between ego car and the pedestrian during the scenario, (3) the difference between TimeTrig and TimeBrake, (4) the difference between DistTrig and DistBrake, (5) whether there was a collision, (6) the speed of ego car at the collision, and (7) the initial speed of ego car. We note that (2) and (3) are 0 for all 25 test cases, showing that the pedestrian is always detected at the first possible frame when TTC \(\le\) 4s, which means that SMIRK commenced emergency braking in all cases. Moreover, we see that SMIRK successfully avoids collisions in all but two test cases. In TC-OS-5, the pedestrian starts 20 m from ego car and runs towards it while it drives at 16 m/s — SMIRK brakes but barely reduces the speed. In TC-OS-9, the pedestrian starts only 15 m from ego car but SMIRK significantly reduces the speed by emergency braking.
The remaining system test cases corresponding to non-pedestrian operational scenarios (TC-OS-[26–38]) and all test cases with jitter (TC-RAND-[1–38]) were also executed with successful test verdicts. All scenarios with basic shapes on collision course were rejected by the safety cage architecture, i.e., SMIRK did never commence any ghost braking. In a virtual conclusion of test meeting, the first three authors concluded that TC-RBT-1 and TC-RBT-2 had passed successfully. Finally, Fig. 15 shows the distribution of inference speeds during the system testing. The median inference time is 22.0 ms and the longest inference time observed is 51.6 ms. Based on these results we conclude that TC-RBT-3 passed successfully and thus provide evidence that SYS-PER-REQ6 is satisfied. The complete system test report is available on GitHub.

Distribution of inference speeds during system testing
11.4 Erroneous behavior log [DD]
As prescribed by AMLAS, the characteristics of erroneous outputs shall be predicted and documented. This section presents the key observations from internal testing of the ML model, independent verification activities, and system testing in ESI Pro-SiVIC. The findings can be used to design appropriate responses by other vehicular systems in the SMIRK context.
Tables 8 and 12 show that the AP@0.5 are lower for occluded pedestrians (S6). As occlusion is an acknowledged challenge for object detection, which we previously have studied for automotive pedestrian detection (Henriksson et al., 2021b), this is an expected result. Table 12 also reveals that the number of FPs and FNs for the S9 slice (children) is relatively high, resulting in slightly lower AP@0.5. Table 11 shows that the problem with children is primarily far away, explained by the few pixels available for the object detection at long distances. While the SMIRK fulfils the robustness requirements within the ODD, we recognize this perception issue in the erroneous behavior log.
During the iterative SMIRK development (cf. E) in Fig. 3), it became evident that OOD detection using the autoencoder was inadequate at close range. Figure 16 shows reconstruction errors (on the y-axis) for all objects in the validation subset of the development data at A) all distances, B) > 10 m, C) > 20 m, and D) > 30 m. The visualization clearly shows that the autoencoder cannot convincingly distinguish the cylinders from the pedestrians at all distances (in subplot A), different objects appear above the threshold, but the OOD detection is more accurate when objects at close distance are excluded (subplot D) displays high accuracy). Based on validation of the four distances, comparing the consequences of the trade-off between safety cage availability and accuracy, the design decision for SMIRK’s autoencoder is to only perform OOD detection for objects that are at least 10 m away. We explain the less accurate behavior at close range by limited training data, a vast majority of images contain pedestrians at a larger distance — which is reasonable since the SMIRK ODD is limited to rural country roads.

Reconstruction errors for different objects on the validation subset of the development data at different distances from ego car (purple=cylinder, red=female business casual, blue=male business, green=male casual). The dashed lines show the threshold for rejecting objects. The subplots show A) all distances, B) more than 10 m, C) more than 20 m, and D) more than 30 m. In SMIRK, we use alternative B) in the safety cage
12 Lessons learned and practical advice
This section shares the most valuable lessons learned during our project. We organize the section into the perspectives of AI engineering and industry-academia collaboration.
12.1 AI engineering in the safety context
SOTIF and AMLAS are compatible and complementary. Our experience in this R&D project is that the processes are feasible to combine during systems development and safety engineering. We expected this based on reading process documentation before embarking on this project, and our hands-on experience confirmed the compatibility in our case under study. As presented in Figs. 1 and 2, both processes are iterative which is key to AI engineering. In our project, we first used SOTIF (including a formal HARA) to iterate toward an initial SRS. From this point, subsequent development iterations that adhered to both the cycles of SOTIF and AMLAS followed. Moreover, SOTIF and AMLAS complement each other as SOTIF maintains a systems perspective (sensors, ML algorithms, and actuators, cf. Section 5.2) whereas AMLAS provides an artifact-oriented focus on safety evidence for activities related to ML. Finally, as stressed by industry partners, we found that we could apply both SOTIF and AMLAS after initial prototyping (cf. Fig. 3) and still harness insights from previous ad hoc work. While safety rarely can be added on top of a complex system, we found that prototyping accelerated subsequent safety engineering for SMIRK.
Using a simulator to create data sets limits the validity of the negative examples. On one hand, our data generation scripts enable substantial freedom and cheap access to data. On the other hand, there is barely any variation in the scenarios (apart from clouds moving on the skydome) as would be the case for naturalistic data. As anything that is not a pedestrian in our data is a de facto negative example (see rationale for DAT-BAL-REQ3), and nothing ever appears in our simulated scenarios unless we add it in our scripts, the diversity of our negative examples is very limited. Our approach to negative examples in the development data, referred to as “background images” in Section 8.2.3, involved including the outlier example Cylinder [N5]. From experiments on the validation subset of the development data, we found that adding frames with cylinders representing negative examples was essential to let the model distinguish between pedestrians and basic shapes. For ML components designed for use in the real world, trained on outcomes from real data collection campaigns, the natural variation of the negative examples would be completely different. When working with synthetic data from simulators, how to specify data requirements on negative examples remains an open question.
Evaluation of object detection models is non-trivial. We spent substantial time to align the understanding within the project and we believe other development endeavors will need to do the same. In particular, we observed that the definition of TP, FP, TN, and FN based on IoU (explained in Section 10.1) is difficult to grasp for novices. The fact that FPs appear due to low IoU scores despite parts of a pedestrian indeed is detected is often counter-intuitive, i.e., “how can a detected pedestrian ever be a FP?” To align the development team, organizations should ensure that the true meaning of those KPIs are communicated as part of internal training. In the same vein, FP rate is not a valid metric (as TNs do not exist) whereas FN rate is used in SYS-PER-REQ2 — again internal training is important to align the understanding. What intuitively is perceived as a FP on the system level is not the same as a FP on the ML model level. To make the distinction clear, we restrict the use of FPs to the model level and refer to incorrect braking on the system level as “ghost braking.”
ML model selection post learning involves fundamental decisions. Model selection is an essential activity in ML. When training ML models over several epochs, the best performing model given some criterion shall be kept. Also, when training alternative models with alternative architectures or hyperparameter settings, there must be a way to select the best candidate. How to tailor a fitness function to quantitatively measure what “best” involves is a delicate engineering effort with inevitable tradeoffs. The default fitness function in YOLOv5 puts 10% of the weight at AP@0.5 and 90% at Mean AP for a range of ten IoU values between 0.5 and 0.95. It would be possible to further customize the fitness function to also cover fairness aspects, i.e., to already during model selection value models that fulfill various quality aspects. There is no upper limit to the possible complexity, as this could encompass gender, size, ODD aspects, etc. For SMIRK, however, we decided to do the opposite, i.e., to prioritize simplicity to gain interpretability by using a simpler metric. As explained in Section 10.1, our fitness function solely uses AP@0.5. Future work could also explore sets of complementary fitness functions and evaluate approaches for multi-criteria optimization for ML model selection (Ali et al., 2017; Koch et al., 2015).
OOD scores can be measured for different parts of an image. What pixels to send to the autoencoder is another important design decision. Initially, we used the entire image as input to the autoencoder, which showed promising results in detecting major changes in the environmental conditions, e.g., leaving the ODD due to nightfall or heavy fog. However, it quickly became evident that this input generated too small differences in the autoencoder’s reconstruction error between inliers and outliers, i.e., it was not a feasible approach to reject basic shapes. We find this to be in line with how the “curse of dimensionality” affects unsupervised anomaly detection in general (Zimek et al., 2012) — the anomalies we try to find are dwarfed by the background information. Instead, we decided to focus on squares (a good shape for the autoencoder) containing pixels close to the bounding box of the detected object, and tried three solutions: (1) extracting a square centered on the middle pixel, (2) extracting the entire bounding box and padding with gray pixels to make it a square, and (3) stretching the contents of the bounding box to fit a rectangle matching the average aspect ratio of pedestrians in the development set. The third approach was the most successful in our study, and is now used in SMIRK. Future OOD architectures will likely combine different selection of the input images.
The fidelity of the radar signatures in the simulator matters. While it is easy for a human to tell how realistic the visual appearance of objects are in ESI Pro-SiVIC, assessing the appropriateness of its radar signature model requires a sensor expert. In SMIRK, we attached the same radar signature to all pedestrians, i.e., the one provided for human bodies in the object catalog. For all basic shapes, on the other hand, we attach the same simplistic spherical radar signature. Designing customized signatures is beyond the scope of our project; thus, we acknowledge this limitation as a threat to validity. It is possible that system testing results would have been different if more elaborate radar signatures were used.
12.2 Reflections on industry-academia collaboration
Engineering research is ideally done in projects that involve partners from both industry and academia. While it might sound easy to accomplish, the software and systems engineering research community acknowledges that it is hard. Numerous papers address challenges and best practices in industry-academia collaboration. A systematic review by Garousi et al. (2016) identified 10 challenge themes (e.g., different time horizons, contrasting reward systems, limited practical relevance, and limited resources) and 17 best practice themes (e.g., select real-world problems, work in an agile fashion, organize regular meetings, and identify industry champions). In this section, we share three main reflections related to industry-academia collaboration around safety-critical ML-based demonstrator development that complement previously reported perspectives.
Collaborating in a safety-critical context is sensitive. The research relation between industry and academia in Sweden is recognized in the (empirical) software engineering community as particularly good. The relations have developed over decades, and we have successfully conducted several research projects guided by the best practices from the literature. However, developing a publicly available demonstrator with an accompanying safety case was a new experience. We found that industry partners are highly reluctant to put their names anywhere in anyway that could suggest any form of liability. Legal discussions can completely stall research projects. For SMIRK, the only reasonable way forward was to (1) largely remove the traceability of individual partner’s contributions, and (2) add explicit disclaimers that SMIRK is only intended for simulators and that all users assume all responsibility and risk etc. We accept that this compromise threatens the validity of our work.
Preparing for long-term maintenance of an OSS demonstrator is difficult. Initiating development of a demonstrator system in a public repository under an OSS license is no problem. However, preparing for long-term maintenance of the system is a different story. Research funding is typically project-based and when projects conclude, it might be hard to motivate maintenance efforts — even if there are active users. Long-term support of OSS tends to depend on individual champions, but, this is rarely sustainable. We acknowledge the challenge and support SMIRK’s longevity by (1) hosting the source code in a GitHub repository managed by the independent non-profit institute RISE, (2) publishing careful contribution guidelines including a branching model, and (3) explicitly stating the responsible unit in the RISE line organization. Even more importantly, before we initiated the development, we aligned the goals of SMIRK with RISE’s long-term research roadmap and project portfolio. Time will tell whether our efforts are sufficient to ensure long-term maintenance.
Finding long-term hosting of large data sets is hard. Fully open ML-based projects must go beyond sharing its source code by also making corresponding data sets available. For us, this turned out to be more difficult than expected. First, GitHub is not a feasible choice for data hosting as they recommend repositories to remain small, i.e., less than 5 GB is strongly recommended. Also, GitHub does not support sophisticated data versioning but must be combined with third party solutions such as DVCFootnote 13. Second, no project partners volunteered to assure long-term hosting of the 185 GB SMIRK data set. Data hosting requires appropriate solutions to accommodate access control, backup, bandwidth, etc. Moreover, even with appropriate solutions in place, storing data is not free — and when the research project is over, someone must keep paying. Our solution, which involved negotiations with long lead-times, was to reach out to a national non-profit AI ecosystem. Luckily, AI Sweden agreed to host the SMIRK data set as part of their Data Factory initiative.
13 Limitations and threats to validity
This section discusses the primary limitations of our work and the most important threats to validity. The overall goal of engineering research is to produce general design knowledge rather than to solve the problems of unique instances. Consequently, we critically discuss our research with respect to the specialized technological rule: “To develop a safety case for ML-based perception in ADAS apply AMLAS.” As proposed by Engström et al. (2020), we discuss the design knowledge resulting from our engineering research with respect to rigor, relevance, and novelty. Our discussion of rigor further addresses categories of validity in qualitative research as presented by Maxwell (1992),
13.1 Rigor
Rigor refers to the degree to which the research is conducted in a thorough, rigorous, and systematic manner. This includes factors such as the use of appropriate research methods, the careful design of the study, and the robustness of the data analysis. Presenting engineering research constructs explicitly supports communicating the research contributions to readers and peer researchers. In this work, we express both a design problem and how we seek to specialize a technological rule from ML in autonomous systems to ML in ADAS.
We primarily support the rigor of our engineering research by applying the engineering frameworks SOTIF and AMLAS. We claim that we properly adapted the frameworks to the SMIRK development context and Section 2 shares our preunderstanding, which allows others to assess our process interpretations. We highlight that we have been in contact with developers of both frameworks. The initiator of SOTIF is part of our research collaboration network in Sweden and RISE Research Institutes of Sweden is involved in the standardization process. Regarding AMLAS, to support a valid implementation in our R&D project, we invited the developers to give a workshop with plenty of interactivity.
The scope of our specialized technological rule, and the underlying engineering research, involves the perspectives of automotive stakeholders. Interpretive validity addresses the researchers’ ability to interpret the perspectives of the R&D participants. There is a risk that the views of the authors influenced the reported lessons learned and practical advice without properly reflecting all perspectives involved. We mitigate this researcher bias through member checking, i.e., letting participants validate our final outcome.
Our primary approach to mitigate threats to evaluation validity is through transparency. We carefully describe design decisions for SMIRK and the work involved in the six AMLAS phases. Thanks to the complete safety case argumentation in the Appendix, we stress that the traceability from arguments to the design and implementation supports external assessments. The description of our safety evidence can be traced on GitHub at the level of commits. Finally, as descriptive validity also involves issues of omission, we claim that our reported ML safety case is complete. The transparency allows others to scrutinize our claim.
13.2 Relevance
Relevance refers to the degree to which the research addresses a relevant and important problem. Involved factors include the validity of the design problem, the potential impact of the study findings on the field, the relevance for practitioners and researchers, and the generalizability.
We support relevance by anchoring the engineering research in a real problem instance. Many companies are currently facing challenges related to safety assurance for ML-based automotive perception systems. Working with the concrete challenge of safety assurance for ML in SMIRK helped connecting all stakeholders. Threats to relevance have been mitigated in the SMILE III project through prolonged involvement, i.e., the long-term relations that evolved during the study. The first SMILE project started already in 2016 and several partners have worked jointly on safety cage architectures since 2018. What we report does not represent individual interviews but joint work and regular project meetings.
Generalizabiliy is the condition of extending the findings to other contexts. The rich description of the systems and safety engineering that led to the open SMIRK ADAS (Socha et al., 2022) supports analytical generalization to other contexts. Furthermore, just like AMLAS is applicable to safety argumentation in different domains, we believe that the safety case provided in the Appendix can inspire similar projects beyond the automotive sector — especially if computer vision is involved. Still, we acknowledge three limitations that threaten the generalizability.
First, we developed SMIRK for the simulator ESI Pro-SiVIC. We have not systematically analyzed how different aspects of the safety case generalize to an ML-based ADAS intended for deployment in a real-world vehicle. However, we mitigated this threat through prolonged industry involvement. All SMILE projects have received an equal share of public and industry funding, which assured that the R&D activities entailed were considered practically relevant to industry. We believe that the SMIRK requirements would generalize to real-world systems, whereas the two AMLAS stages data management and model deployment would change the most. Future work should investigate this in detail. However, we argue that our work with synthetic images is relevant for real-world systems due to the growing interest in combining synthetic and natural images (Poucin et al., 2021).
Second, SMIRK is a single independent ADAS designed for a minimalisic ODD. The main strategy to mitigate threats related to the minimalism was again prolonged involvement, i.e., our industry partners found our safety case relevant; thus, also others in the community are likely to share this view. It is less clear how the independence of the SMIRK ADAS influences the generalizability of our contributions as a modern car can be considered a system-of-systems (Pelliccione et al., 2020). We leave it to future work to assess how the safety case would change if additional ADAS were involved in the same safety argumentation.
Third, Python is dynamically typed and not an ideal choice for development of safety-critical applications. We chose Python to get easy access to numerous state-of-the-art ML libraries. Also, as it is the dominating language in the research community others can more easily build on our work. A real-world in-vehicle implementation would lead to another language choice, e.g., adhering to MISRA C (Motor Industry Software Reliability Association et al., 2012), a widely accepted set of software development guidelines for using the C programming language in safety-critical systems.
13.3 Novelty
Novelty refers to the newness or originality of an idea, approach, or method. The novelty of our contributions primarily originate in two concepts useful in engineering research. First, combinatorial creativity involves the combination of existing ideas, concepts, or elements to create something new and novel. Among other things, our work combines research on requirements engineering and software testing in the development of a safety case for ML.
Second, research synthesis is a method of systematically combining the results of multiple studies. There are several approaches to synthesizing results, e.g., statistical meta-analysis as popular in medicine, less formal narrative methods, and meta-ethnography that relies on interpretation to preserve the social contexts in which the original findings emerged. Closer to our work, Denyer et al. (2008) discuss how design-oriented research synthesis can address fragmentation and increase the chances of industrial adoption.
There is an ever-increasing number of software engineering publications and the research field is diverse and fragmented. Moreover, the practical relevance of the research has been frequently questioned (Garousi et al., 2020). We argue that our approach to design-oriented synthesis of fragmented requirements on ML-based perception systems, safety cage architectures, DNNs and ML testing — identified in various software engineering subfields and connected using the AMLAS framework — represents a holistic case that has been missing. Collecting these pieces in a joint publication increases the chances for industrial impact.
Finally, as reported by Engström et al. (2020), expressing technological rules clearly and at a carefully selected level of abstraction helps in communicating the novelty. To the best of our knowledge, SMIRK was the first completely transparent ML-based OSS ADAS. On the same note, related to our specialized technological rule, we believe this publication is the first complete transparent safety case for an ADAS ML component. We also believe that this is the first peer-reviewed work from a complete application of AMLAS that does not involve any of the inventors of the framework. Consequently, this also constitutes novelty related to the general technological rule presented in Section 4.
14 Conclusion and future work
Safe ML is going to be fundamental when increasing the level of vehicle automation. Several automotive standardization initiatives are ongoing to allow safety certification for ML in road vehicles, e.g., ISO 21448 SOTIF. However, standards provide high-level requirements that must be operationalized in each development context. Unfortunately, there is a lack of publicly available ML-based automotive demonstrator systems that can be used to study safety case development. We set out to remedy this lack through engineering research in an industry-academia collaboration in Sweden. The design knowledge provided through our engineering research relates to the technological rule: “To develop a safety case for ML-based perception in ADAS apply AMLAS.”
We present a safety argumentation for SMIRK, a PAEB designed for operation in the industry-grade simulator ESI Pro-SiVIC. SMIRK uses a radar sensor for object detection and an ML-based component relying on a DNN for pedestrian recognition. Originating in SMIRK’s minimalistic ODD, we present a complete safety case for its ML-based component by following the AMLAS framework. To the best of our knowledge, this work constitutes the first complete application of AMLAS independent from its authors. Guided by AMLAS, we argue that we demonstrate how to provide sufficient evidence that ML in SMIRK is safe given its ODD. We conclude that even for a very restricted ODD, the size of the ML safety case is considerable, i.e., there are many aspects of the AI engineering that must be clearly explained. As the devil is in the detail, we carefully report all steps — and we recommend future research studies to follow suit.
We report several lessons learned related to AI engineering in the SOTIF/AMLAS context. First, using a simulator to create synthetic data sets for ML training particularly limits the validity of the negative examples. Second, the complexity of object detection evaluations necessitates internal training within the project team. Third, composing the fitness function used for model selection is a delicate engineering activity that forces explicit tradeoff decisions. Fourth, what parts of an image to send to a autoencoder for OOD detection is an open question — for SMIRK, we stretch the content of bounding boxes to a larger square. Finally, we report three reflections related to industry-academia collaboration around safety-critical ML-based demonstrator development.
Thanks to the complete safety case, SMIRK can be used as a starting point for several avenues of future research. First, the SMIRK MVP enables studies on efficient and effective approaches to conduct safety assurance for ODD extension. In this context, SMIRK could be used as a platform to study dynamic safety cases, i.e., updating the safety case as the system evolves, and reuse of safety evidence for new operational contexts (dela Vara et al., 2019). Second, SMIRK could be used as a realistic test benchmark for automotive ML testing, including search-based techniques for test case generation. The testing community has largely worked on offline testing of single frames, but we know that this is insufficient. Also, we recommend comparative studies involving real-world testing in controlled environments, as discrepancies do exist between simulations and the physical world. Third, we recommend the community to port SMIRK to other simulators beyond ESI Pro-SiVIC. As we investigated in previous work, running highly similar test scenarios in different simulators can lead to considerably different results — further exploring this phenomenon using SMIRK would be a valuable research direction. Finally, while SOTIF explicitly excludes antagonistic attacks, there are good reasons to consider both safety and cybersecurity jointly in automotive systems through co-engineering. We plan to use SMIRK as a starting point in future studies on adversarial ML attacks.
Data availability
All data related to this study is publicy available. The SMIRK source code is publicly available on GitHub under a GPL-3.0 license: https://github.com/RI-SE/smirk/. This repository also contains all safety evidence and instructions to allow reproduction of our results. The data set used for development of SMIRK’s ML component is available at AI Sweden: https://www.ai.se/en/data-factory/datasets/data-factory-datasets/smirk-dataset.
Notes
As noted in the empirical standard for engineering research, some methodological guidelines refer to the same approach as design science research.
We stress that SMIRK shall never be used in a real vehicle and the authors take no responsibility in any such endeavors.
References
Abdessalem, R. B., Nejati, S., Briand, LC., et al. (2018a). Testing vision-based control systems using learnable evolutionary algorithms. In: Proceedings of the 40th International Conference on Software Engineering, pp. 1016–1026.
Abdessalem, R. B., Panichella, A., Nejati, S., et al. (2018b). Testing autonomous cars for feature interaction failures using many-objective search. In: Proceedings of the 33rd International Conference on Automated Software Engineering, pp. 143–154.
Ali, R., Lee, S., & Chung, T. C. (2017). Accurate multi-criteria decision making methodology for recommending machine learning algorithm. Expert Systems with Applications, 71, 257–278.
Amorim, T., Martin, H., Ma, Z., et al. (2017). Systematic pattern approach for safety and security co-engineering in the automotive domain. In: Proceedings of the International Conference on Computer Safety, Reliability, and Security, pp. 329–342.
An, J., & Cho, S. (2015). Variational autoencoder based anomaly detection using reconstruction probability. Special Lecture on IE, 2(1), 1–18.
Arrieta, A. B., Díaz-Rodríguez, N., Del Ser, J., et al. (2020). Explainable artificial intelligence (XAI): Concepts, taxonomies, opportunities and challenges toward responsible AI. Information Fusion, 58, 82–115.
Ashmore, R., Calinescu, R., & Paterson, C. (2021). Assuring the machine learning lifecycle: Desiderata, methods, and challenges. ACM Computing Surveys, 54(5), 1–39.
Assurance Case Working Group. (2021). Goal structuring notation community standard (Version 3). Technical Report SCSC-141C, Safety-Critical Systems Club, UK.
Barr, E. T., Harman, M., McMinn, P., et al. (2014). The oracle problem in software testing: A survey. IEEE Transactions on Software Engineering, 41(5), 507–525.
Ben Abdessalem, R., Nejati, S., Briand, LC., et al. (2016). Testing advanced driver assistance systems using multi-objective search and neural networks. In: Proceedings of the 31st International Conference on Automated Software Engineering, pp. 63–74.
Bolya, D., Foley, S., Hays, J., et al. (2020). Tide: A general toolbox for identifying object detection errors. In: Proceeding of the European Conference on Computer Vision, pp. 558–573.
Borg, M., Ben Abdessalem, R., Nejati, S., et al. (2021a). Digital twins are not monozygotic: Cross-replicating ADAS testing in two industry-grade automotive simulators. In: Proceedings of the 14th Conference on Software Testing, Verification and Validation, pp. 383–393.
Borg, M., Bronson, J., Christensson, L., et al. (2021b). Exploring the assessment list for trustworthy AI in the context of advanced driver-assistance systems. In: Proceedings of the 2nd International Workshop on Ethics in Software Engineering Research and Practice, pp. 5–12.
Borg, M., Englund, C., Wnuk, K., et al. (2019). Safely entering the deep: A review of verification and validation for machine learning and a challenge elicitation in the automotive industry. Journal of Automotive Software Engineering, 1(1), 1–19.
Bosch, J., Olsson, H. H., & Crnkovic, I. (2021). Engineering AI systems: A research agenda. In: Artificial Intelligence Paradigms for Smart Cyber-Physical Systems. IGI global, pp. 1–19.
Chen, L., Babar, M. A., & Nuseibeh, B. (2012). Characterizing architecturally significant requirements. IEEE Software, 30(2), 38–45.
dela Vara, J. L., Ruiz, A., Gallina, B., et al. (2019). The AMASS approach for assurance and certification of critical systems. In: Embedded World 2019.
Denney, E., Pai, G., & Habli, I. (2015). Dynamic safety cases for through-life safety assurance. In: Proceedings of the 37th International Conference on Software Engineering, pp. 587–590.
Denyer, D., Tranfield, D., & Van Aken, J. E. (2008). Developing design propositions through research synthesis. Organization studies, 29(3), 393–413.
Dollar, P., Wojek, C., Schiele, B., et al. (2011). Pedestrian detection: An evaluation of the state of the art. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(4), 743–761.
Ebadi, H., Moghadam, M. H., Borg, M., et al. (2021). Efficient and effective generation of test cases for pedestrian detection-search-based software testing of Baidu Apollo in SVL. In: Proceedings of the International Conference on Artificial Intelligence Testing, pp. 103–110.
Engström, E., Storey, M. A., Runeson, P., et al. (2020). How software engineering research aligns with design science: A review. Empirical Software Engineering, 25(4), 2630–2660.
Fagan, M. (1976). Design and code inspections to reduce errors in program development. IBM Systems Journal, 15(3), 182–211.
Garousi, V., Petersen, K., & Ozkan, B. (2016). Challenges and best practices in industry-academia collaborations in software engineering: A systematic literature review. Information and Software Technology, 79, 106–127.
Garousi, V., Borg, M., & Oivo, M. (2020). Practical relevance of software engineering research: Synthesizing the community’s voice. Empirical Software Engineering, 25(3), 1687–1754.
Gauerhof, L., Hawkins, R., Picardi, C., et al. (2020). Assuring the safety of machine learning for pedestrian detection at crossings. In: Proceedings of the International Conference on Computer Safety, Reliability, and Security, pp. 197–212.
Haq, F. U., Shin, D., Briand, L. C., et al. (2021a). Automatic test suite generation for key-points detection DNNs using many-objective search (experience paper). In: Proceedings of the 30th International Symposium on Software Testing and Analysis, pp. 91–102.
Haq, F. U., Shin, D., Nejati, S., et al. (2021b). Can offline testing of deep neural networks replace their online testing? Empirical Software Engineering, 26(5), 1–30.
Hauer, F., Schmidt, T., Holzmüller, B., et al. (2019). Did we test all scenarios for automated and autonomous driving systems? In: Proceedings of the IEEE Intelligent Transportation Systems Conference, pp. 2950–2955.
Hawkins, R., Paterson, C., Picardi, C., et al. (2021). Guidance on the assurance of machine learning in autonomous systems (AMLAS). Technical Report Version 1.1, Assuring Autonomy Int’l. Programme, University of York.
Henriksson, J., Berger, C., Borg, M., et al. (2019). Towards structured evaluation of deep neural network supervisors. In: Proceedings of the Interbational Conference on Artificial Intelligence Testing, pp. 27–34.
Henriksson, J., Berger, C., Borg, M., et al. (2021a). Performance analysis of out-of-distribution detection on trained neural networks. Information and Software Technology, 130(106), 409.
Henriksson, J., Berger, C., & Ursing, S. (2021b). Understanding the impact of edge cases from occluded pedestrians for ML systems. In: Proceedings of the 47th Euromicro Conference on Software Engineering and Advanced Applications, pp. 316–325.
High-Level Expert Group on Artificial Intelligence. (2019). Ethics guidelines for trustworthy AI. Directorate-General for Communications Networks, Content and Technology, European Commission: Technical Report.
Horkoff, J. (2019). Non-functional requirements for machine learning: Challenges and new directions. In: Proceedings of the IEEE 27th International Requirements Engineering Conference, pp. 386–391.
IEEE. (1998). IEEE recommended practice for software requirements specifications. Technical Report IEEE 830-1998, Institute of Electrical and Electronics Engineers.
Jia, Y., Mcdermid, J. A., Lawton, T., et al. (2022). The role of explainability in assuring safety of machine learning in healthcare. IEEE Transactions on Emerging Topics in Computing.
Käpyaho, M., & Kauppinen, M. (2015) Agile requirements engineering with prototyping: A case study. In: Proceedings of the 23rd International Requirements Engineering Conference, pp. 334–343.
Klaise, J., Van Looveren, A., Cox, C., et al. (2020). Monitoring and explainability of models in production. In: Proceedings of the ICML Workshop on Challenges in Deploying and Monitoring Machine Learning Systems.
Koch, P., Wagner, T., Emmerich, M. T., et al. (2015). Efficient multi-criteria optimization on noisy machine learning problems. Applied Soft Computing, 29, 357–370.
Kruchten, P. B. (1995). The 4+1 view model of architecture. IEEE Software, 12(6), 42–50.
Lin, T. Y., Maire, M., Belongie, S., et al. (2014). Microsoft COCO: Common objects in context. In: European Conference on Computer Vision, pp. 740–755.
Liu, S., Qi, L., Qin, H., et al. (2018). Path aggregation network for instance segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8759–8768.
Masuda, S. (2017). Software testing design techniques used in automated vehicle simulations. In: Proceedings of the International Conference on Software Testing, Verification and Validation Workshops, pp. 300–303.
Maxwell, J. (1992). Understanding and validity in qualitative research. Harvard Educational Review, 62(3), 279–301.
Mohseni, S., Pitale, M., Singh, V., et al. (2020) Practical solutions for machine learning safety in autonomous vehicles. In: Proceedings of the Artificial Intelligence Safety (SafeAI) Workshop at AAAI 2020. http://ceur-ws.org/Vol-2560/
Motor Industry Software Reliability Association. et al. (2012) MISRA-C guidelines for the use of the C language in critical systems.
Panichella, A., Kifetew, F. M., & Tonella, P. (2015). Reformulating branch coverage as a many-objective optimization problem. In: Proceedings of the 8th International Conference on Software Testing, Verification and Validation, pp. 1–10.
Pei, K., Cao, Y., Yang, J., et al. (2017). DeepXplore: Automated whitebox testing of deep learning systems. In: Proceedins of the 26th Symposium on Operating Systems Principles, pp. 1–18.
Pelliccione, P., Knauss, E., Ågren, S. M., et al. (2020). Beyond connected cars: A systems of systems perspective. Science of Computer Programming, 191(102), 414.
Petersson, H., Thelin, T., Runeson, P., et al. (2004). Capture-recapture in software inspections after 10 years research: Theory, evaluation and application. Journal of Systems and Software, 72(2), 249–264.
Picardi, C., Paterson, C., Hawkins, R. D., et al. (2020) Assurance argument patterns and processes for machine learning in safety-related systems. In: Proceedings of the Workshop on Artificial Intelligence Safety, pp. 23–30.
Poucin, F., Kraus, A., & Simon, M. (2021). Boosting instance segmentation with synthetic data: A study to overcome the limits of real world data sets. In: Proceedings of the IEEE/CVF International Conference on Computer Vision, pp. 945–953/.
Preschern, C., Kajtazovic, N., & Kreiner, C. (2015). Building a safety architecture pattern system. In: Proceedings of the 18th European Conference on Pattern Languages of Program, pp. 1–55.
Rajput, M. (2020). YOLO V5 – Explained and demystified. https://towardsai.net/p/computer-vision/yolo-v5%E2%80%8A-%E2%80%8Aexplained-and-demystified
Ralph, P., Bin Ali, N., Baltes, S., et al. (2020). Empirical standards for software engineering research. arXiv preprint arXiv:2010.03525
Redmon, J., Divvala, S., Girshick, R., et al. (2016). You only look once: Unified, real-time object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 779–788.
Riccio, V., Jahangirova, G., Stocco, A., et al. (2020). Testing machine learning based systems: A systematic mapping. Empirical Software Engineering, 25(6), 5193–5254.
RISE Research Institutes of Sweden. (2022). SMIRK GitHub repository. https://github.com/RI-SE/smirk/
Runeson, P., Engström, E., & Storey, M. A. (2020). The design science paradigm as a frame for empirical software engineering. In: Contemporary Empirical Methods in Software Engineering. Springer, pp. 127–147.
Salay, R., Queiroz, R., & Czarnecki, K. (2018). An analysis of ISO 26262: Machine learning and safety in automotive software.
Schwalbe, G., & Schels, M. (2020). A survey on methods for the safety assurance of machine learning based systems. In: Proceedings of the 10th European Congress on Embedded Real Time Software and Systems.
Schwalbe, G., Knie, B., Sämann, T., et al. (2020). Structuring the safety argumentation for deep neural network based perception in automotive applications. In: Proceedings of the International Conference on Computer Safety, Reliability, and Security, Springer, pp. 383–394.
Schyllander, J. (2014) Fotgängarolyckor - statistik och analys. Technical Report MSB744, Swedish Civil Contingencies Agency. https://rib.msb.se/filer/pdf/27438.pdf
Socha, K., Borg, M., & Henriksson, J. (2022). SMIRK: A machine learning-based pedestrian automatic emergency braking system with a complete safety case. Software Impacts, 13(100), 352.
Song, Q., Borg, M., Engström, E., et al. (2022). Exploring ML testing in practice: Lessons learned from an interactive rapid review with axis communications. In: Proceedings of the 1st International Conference on AI Engineering – Software Engineering for AI.
Stocco, A., Pulfer, B., Tonella, P. (2022). Mind the gap! A study on the transferability of virtual vs physical-world testing of autonomous driving systems. IEEE Transactions on Software Engineering.
Tambon, F., Laberge, G., An, L., et al. (2022). How to certify machine learning based safety-critical systems? A systematic literature review. Automated Software Engineering, 29(38).
Tao, J., Li, Y., Wotawa, F., et al. (2019). On the industrial application of combinatorial testing for autonomous driving functions. In: Proceedings of the International Conference on Software Testing, Verification and Validation Workshops, pp. 234–240.
Thorn, E., Kimmel, S. C., Chaka, M., et al. (2018). A framework for automated driving system testable cases and scenarios. Technical Report, US Department of Transportation. National Highway Traffic Safety Administration.
Tian, Y., Pei, K., Jana, S., et al. (2018). DeepTest: Automated testing of deep-neural-network-driven autonomous cars. In: Proceedings of the 40th International Conference on Software Engineering, pp. 303–314.
Tsilionis, K., Wautelet, Y., Faut, C., et al. (2021). Unifying behavior driven development templates. In: Proceedings of the 29th International Requirements Engineering Conference, pp. 454–455.
van Aken, J. E. (2004). Management research based on the paradigm of the design sciences: The quest for field-tested and grounded technological rules. Journal of Management Studies, 41(2), 219–246.
Weissensteiner, P., Stettinger, G., Rumetshofer, J., et al. (2021). Virtual validation of an automated lane-keeping system with an extended operational design domain. Electronics, 11(1), 72.
Wiegers, K. (2008). Karl Wiegers’ software requirements specification (SRS) template. Technical Report, Process Impact. https://www.modernanalyst.com/Resources/Templates/tabid/146/ID/497/Karl-Wiegers-Software-Requirements-Specification-SRS-Template.aspx
Willers, O., Sudholt, S., Raafatnia, S., et al. (2020). Safety concerns and mitigation approaches regarding the use of deep learning in safety-critical perception tasks. In: Proceedings of the International Conference on Computer Safety, Reliability, and Security, pp. 336–350.
Wieringa, R. J. (2014). Design science methodology for information systems and software engineering. Springer.
Wozniak, E., Cârlan, C., Acar-Celik, E., et al. (2020). A safety case pattern for systems with machine learning components. In: Proceedings of the International Conference on Computer Safety, Reliability, and Security, pp. 370–382.
Wu, B., & Nevatia, R. (2008). Optimizing discrimination-efficiency tradeoff in integrating heterogeneous local features for object detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1–8.
Wu, W., & Kelly, T. (2004). Safety tactics for software architecture design. In: Proceedings of the 28th Annual International Computer Software and Applications Conference, pp. 368–375.
Zablocki, É., Ben-Younes, H., Pérez, P., et al. (2022). Explainability of deep vision-based autonomous driving systems: Review and challenges. International Journal of Computer Vision, 130, 2425–2452.
Zhang, M., Zhang, Y., Zhang, L., et al. (2018). DeepRoad: GAN-based metamorphic testing and input validation framework for autonomous driving systems. In: Proceedings of the 33rd International Conference on Automated Software Engineering, pp. 132–142.
Zimek, A., Schubert, E., & Kriegel, H. P. (2012). A survey on unsupervised outlier detection in high-dimensional numerical data. Statistical Analysis and Data Mining: The ASA Data Science Journal, 5(5), 363–387.
Acknowledgements
Thanks go to ESI Group for supporting us with technical details along the way, especially Erik Abenius and François-Xavier Jegeden. We also thank AI Sweden for agreeing to host the SMIRK data set as part of their Data Factory initiative.
Funding
Open access funding provided by RISE Research Institutes of Sweden. This work was carried out within the SMILE III project financed by Vinnova, FFI, Fordonsstrategisk forskning och innovation under the grant number 2019-05871 and partially supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by Knut and Alice Wallenberg Foundation.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix. AMLAS safety argumentation for machine learning in SMIRK
Appendix. AMLAS safety argumentation for machine learning in SMIRK
This section describes the complete SMIRK safety argumentation organized by the six AMLAS stages (Hawkins et al., 2021). For each step, we present an argument pattern using GSN notation (Assurance Case Working Group, 2021) and present the final argument in a text box.
1.1 A.1 Stage 1: machine learning assurance scoping
Figure 17 shows the overall ML assurance scoping argument pattern for SMIRK. The pattern, as well as all subsequent patterns in this paper, follows the examples provided in AMLAS, but adapts it to the specific SMIRK case. Furthermore, we provide evidence that supports our arguments.

ML Assurance Scoping Argument Pattern [F]
The top claim, i.e., the starting point for the safety argument for the ML-based component, is that the system safety requirements that have been allocated to the pedestrian recognition component are satisfied in the ODD (G1.1). The safety claim for the pedestrian recognition component is made within the context of the information that was used to establish the safety requirements allocation, i.e., the system description ([C]), the ODD ([B]), and the ML component description ([D]). The allocated system safety requirements ([E]) are provided as context. An explicit assumption is made that the allocated safety requirements have been correctly defined (A1.1), as this is part of the overall system safety process (FuSa and SOTIF) preceding AMLAS. Our claim to the validity of this assumption is presented in relation to the HARA described in [E]. As stated in AMLAS, “the primary aim of the ML Safety Assurance Scoping argument is to explain and justify the essential relationship between, on the one hand, the system-level safety requirements and associated hazards and risks, and on the other hand, the ML-specific safety requirements and associated ML performance and failure conditions.”
The ML safety claim is supported by an argument split into two parts. First, the development of the ML component is considered with an argument that starts with the elicitation of the ML safety requirements. Second, the deployment of the ML component is addressed with a corresponding argument.

1.2 A.2 Stage 2: machine learning requirements assurance
Figure 18 shows the ML Safety Requirements Argument Pattern [I]. The top claim is that the system safety requirements that have been allocated to the ML component are satisfied by the model that is developed (G2.1). This is demonstrated through considering explicit ML safety requirements defined for the ML model [H]. The argument approach is a refinement strategy translating the allocated safety requirements into two concrete ML safety requirements (S2.1) provided as context (C2.1). Justification J2.1 explains how we allocated safety requirements to the ML component as part of the system safety process, including the HARA.

ML Safety Requirements Argument Pattern [I]
Strategy S2.1 is refined into two subclaims about the validity of the ML safety requirements corresponding to missed pedestrians and ghost braking, respectively. Furthermore, a third subclaim concerns the satisfaction of those requirements. G2.2 focuses on the ML safety requirement SYS-ML-REQ1, i.e., that the nominal functionality of the pedestrian recognition component shall be satisfactory. G2.2 is considered in the context of the ML data (C2.2) and the ML model (C2.3), which in turn are supported by the ML Data Argument Pattern [R] and the ML Learning Argument Pattern [W]. The argumentation strategy (S2.2) builds on two subclaims related to two types of safety requirements with respect to safety-related outputs, i.e., performance requirements (G2.5 in context of C2.4) and robustness requirements (G2.6 in context of C2.5). The satisfaction of both G2.5 and G2.6 are addressed by the ML Verification Argument Pattern [BB].
Subclaim G2.3 focuses on the ML safety requirement SYS-ML-REQ2, i.e., that the pedestrian recognition component shall reject input that does not resemble the training data to avoid ghost braking. G2.3 is again considered in the context of the ML data (C2.2) and the ML model (C2.3). For SMIRK, the solution is the safety cage architecture (Sn2.1) developed in the SMILE research program (Henriksson et al., 2021a), described in Section 9.3.
Subclaim G2.4 states that the ML safety requirements are a valid development of the allocated system safety requirements. The justification (J2.2) is that the requirements have been validated in cross-organizational workshops within the SMILE III research project. We provide evidence through ML Safety Requirements Validation Results [J] originating in a Fagan inspection (Sn2.2).

1.3 A.3 Stage 3: data management assurance
Figure 19 shows the ML Data Argument Pattern [R]. The top claim is that the data used during the development and verification of the ML model is sufficient (G3.1). This claim is made for all three data sets: development data [N], internal test data [O], and verification data [P]. The argumentation strategy (S2.1) involves how the sufficiency of these data sets is demonstrated given the Data Requirements [L]. The strategy is supported by arguing over subclaims demonstrating sufficiency of the Data Requirements (G3.2) and that the Data Requirements are satisfied (G3.3). Claim G3.2 is supported by evidence in the form of a data requirements justification report [M]. As stated in AMLAS, “It is not possible to claim that the data alone can guarantee that the ML safety requirements will be satisfied, however the data used must be sufficient to enable the model that is developed to do so.”

ML Data Argument Pattern [R]
Claim G3.3 states that the generated data satisfies the data requirements in context of the decisions made during data collection. The details of the data collection, along with rationales, are recorded in the Data Generation Log [Q]. The argumentation strategy (S2.2) uses refinement mapping to the assurance-related desiderata of the data requirements. The refinement of the desiderata into concrete data requirements for the pedestrian recognition component of SMIRK, given the ODD, is justified by an analysis of the expected traffic agents and objects that can appear in ESI Pro-SiVIC. For each subclaim corresponding to a desideratum, i.e., relevance (G3.4), completeness (G3.5), accuracy (G3.6), and balance (G3.7), there is evidence in a matching section in the ML Data Validation Report [S].

1.4 A.4 Stage 4: model learning assurance
Figure 20 shows the ML Learning Argument Pattern [W]. The top claim (G4.1) is that the development of the learned model [V] is sufficient. The strategy is to argue over the internal testing of the model and that the ML development was appropriate (S4.1) in context of creating a valid model that meets practical constraints such as real-time performance and cost (C4.2). Subclaim (G4.2) is that the ML model satisfies the ML safety requirements when using the internal test data [O]. We justify that the internal test results indicate that the ML model satisfies the ML safety requirements (J3.1) by presenting evidence from the internal test results [X].

ML Learning Argument Pattern [W]
Subclaim G4.3 addresses the approach that was used when developing the model. This claim is in turn supported by two additional subclaims regarding the type of model selected and the model parameters selected, respectively. First, G4.4 claims that the type of model is appropriate for the specified ML safety requirements and the other model constraints. ML development processes, including transfer learning, are highly iterative thus rationales for development decisions must be recorded. Second, G4.5 claims that the parameters of the ML model are appropriately selected to tune performance toward the object detection task within the specified ODD. Rationales for all relevant decisions in G4.4 and G4.5 are recorded in the model development log [U].

1.5 A.5 Stage 5: model verification assurance
Figure 21 shows the ML Verification Argument Pattern [BB]. The top claim (G5.1) corresponds to the bottom claim in the safety requirements argument pattern [I], i.e., that all ML safety requirements are satisfied. The argumentation builds on a subclaim and an argumentation strategy. First, subclaim G5.2 is that the verification of the ML model is independent of its development. The verification log [AA] specifies how this has been achieved for SMIRK (Sn5.1). Second, the strategy S5.1 argues that test-based verification is an appropriate approach to generate evidence that the ML safety requirements are met. The justification (J5.1) is that the SMIRK test strategy follows the proposed organization in peer-reviewed literature on ML testing, which is a better fit than using less mature formal methods for ML models as complex as YOLOv5.

ML Verification Argument Pattern [BB]
Following the test-based verification approach, the subclaim G5.3 argues that the ML model satisfies the ML safety requirements when the verification data (C5.1) is applied. The testing claim is supported by three subclaims. First, G5.4 argues that the test results demonstrate that the ML safety requirements are satisfied, for which Verification Test Results [Z] are presented as evidence. Second, G5.5 argues that the Verification Data [P] is sufficient to verify the intent of the ML safety requirements in the ODD. Third, G5.6 argues that the test platform is representative of the operational platform. Evidence for both G5.5 and G5.6 is presented in the Verification Log [AA].

1.6 A.6 Stage 6: model deployment assurance
Figure 22 shows the ML Verification Argument Pattern [GG]. The top claim (G6.1) is that the ML safety requirements SYS-ML-REQ1 and SYS-ML-REQ2 are satisfied when deployed to the ego car in which SMIRK operates. The argumentation strategy S6.1 is two-fold. First, subclaim G6.2 is that the ML safety requirements are satisfied under all defined operating scenarios when the ML component is integrated into SMIRK in the context (C6.1) of the specified operational scenarios [EE]. Justification J6.1 explains that the scenarios were identified through an analysis of the SMIRK ODD. G6.2 has another subclaim (G6.4), arguing that the integration test results [FF] show that SYS-ML-REQ1 and SYS-ML-REQ2 are satisfied.

ML Deployment Argument Pattern [GG]
Second, subclaim G6.3 argues that SYS-ML-REQ1 and SYS-ML-REQ2 continue to be satisfied during the operation of SMIRK. The supporting argumentation strategy (S6.3) relates to the design of SMIRK and is again two-fold. First, subclaim G6.6 argues that the operational achievement of the deployed component satisfies the ML safety requirements. Second, subclaim G6.5 argues that the design of SMIRK into which the ML component is integrated ensures that SYS-ML-REQ1 and SYS-ML-REQ2 are satisfied throughout operation. The corresponding argumentation strategy (S6.4) is based on demonstrating that the design is robust by taking into account identified erroneous behavior in the context (C5.1) of the Erroneous Behavior Log [DD]. More specifically, the argumentation entails that predicted erroneous behavior will not result in the violation of the ML safety requirements. This is supported by two subclaims, i.e., that the system design provides sufficient monitoring of erroneous inputs and outputs (G6.7) and that the system design provides acceptable response to erroneous inputs and outputs (G6.8). Both G6.7 and G6.8 are addressed by the safety cage architecture that monitors input through OOD detection using an autoencoder that rejects anomalies accordingly. The acceptable system response is to avoid emergency braking and instead let the human driver control ego car.

Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Borg, M., Henriksson, J., Socha, K. et al. Ergo, SMIRK is safe: a safety case for a machine learning component in a pedestrian automatic emergency brake system. Software Qual J 31, 335–403 (2023). https://doi.org/10.1007/s11219-022-09613-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11219-022-09613-1