
Deep Learning Models Outperform Generalized Machine Learning Models in Predicting Winter Wheat Yield Based on Multispectral Data from Drones

Abstract
:1. Introduction
2. Materials and Methods
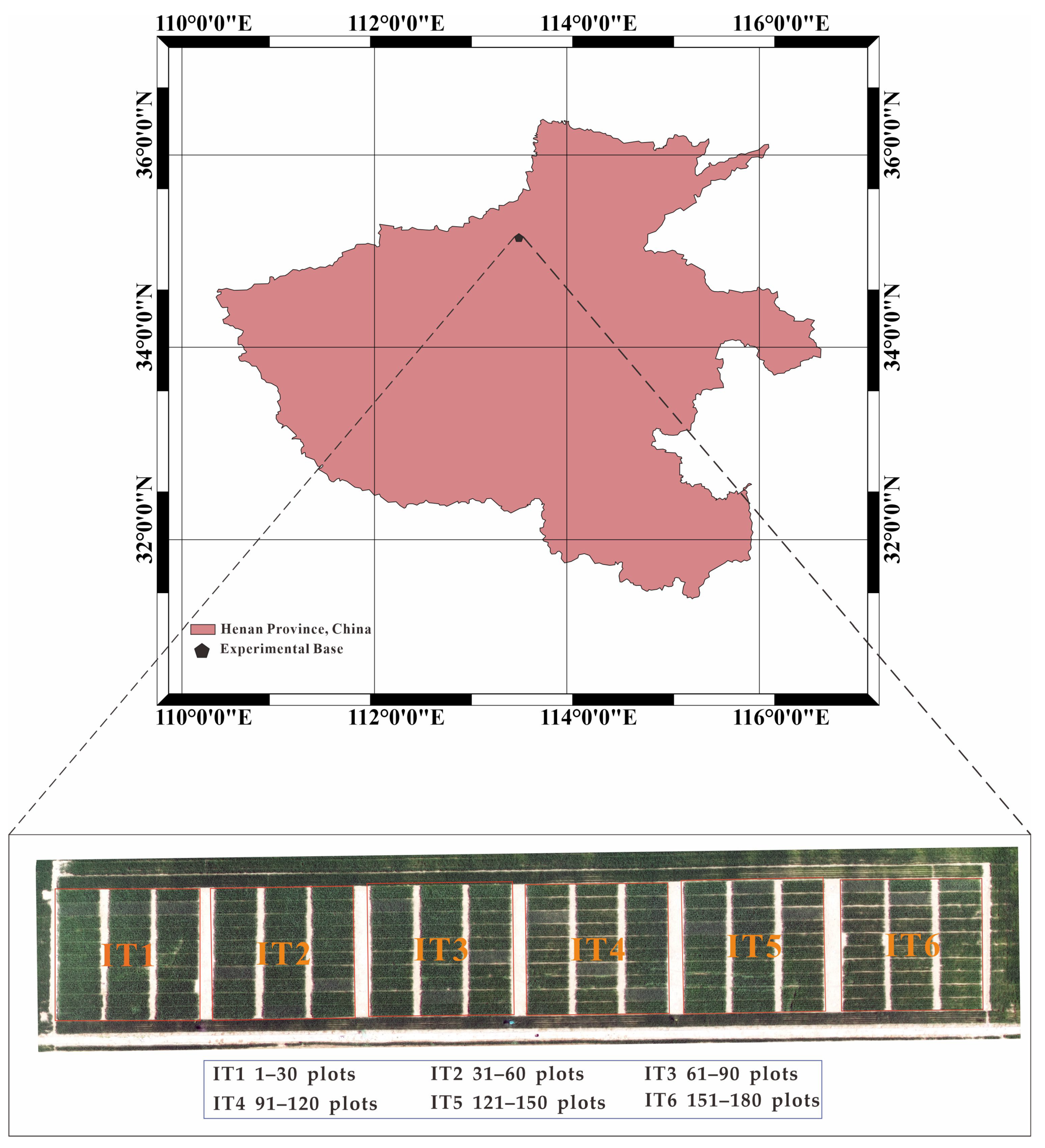
2.1. Experimental Area and Design
2.2. Spectral Data Acquisition and Processing
2.3. UAV Image Pre-Processing
2.4. Acquisition of Vegetation Index
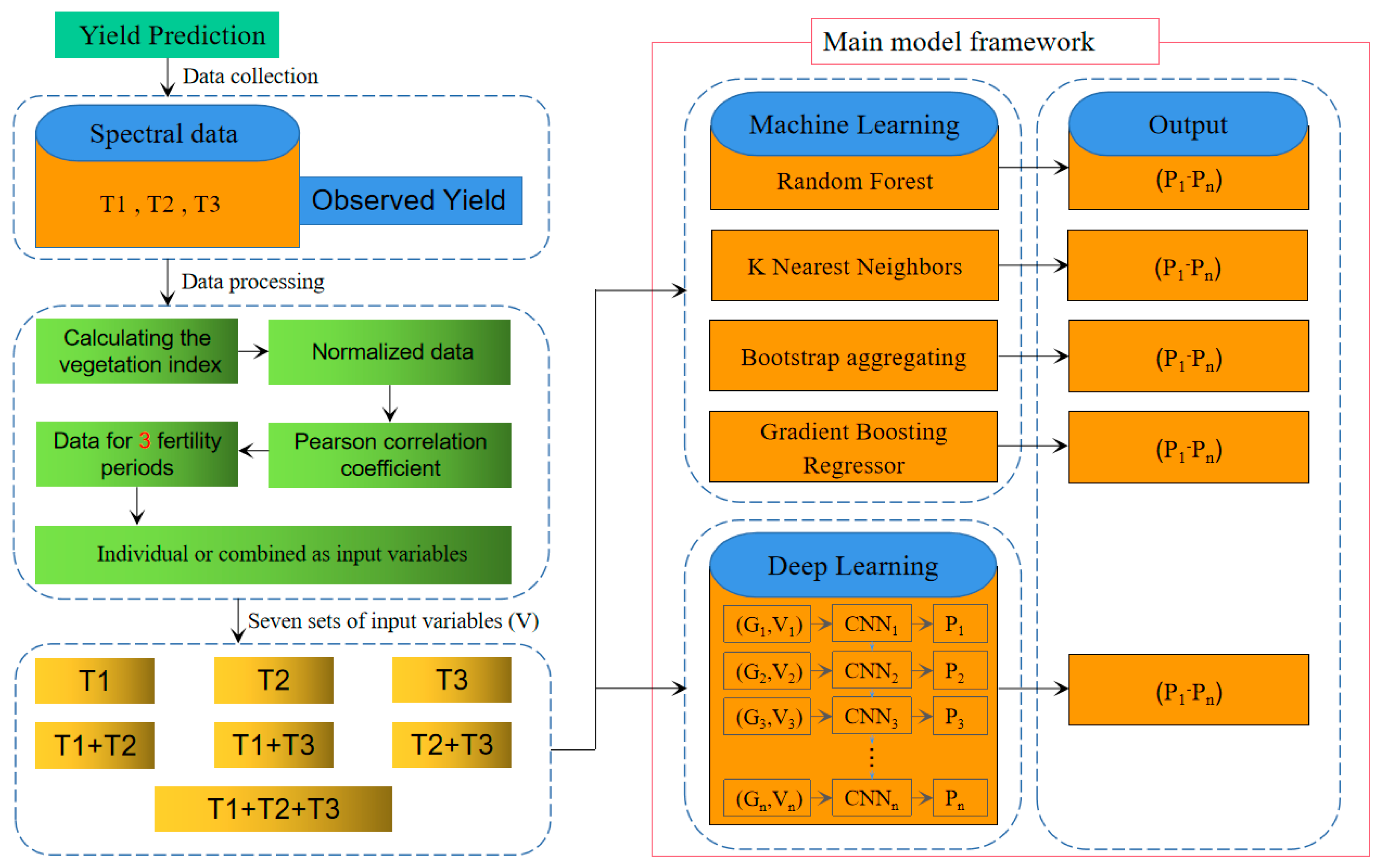
2.5. Framework for Yield Prediction Models
2.5.1. Generalized Machine Learning Models
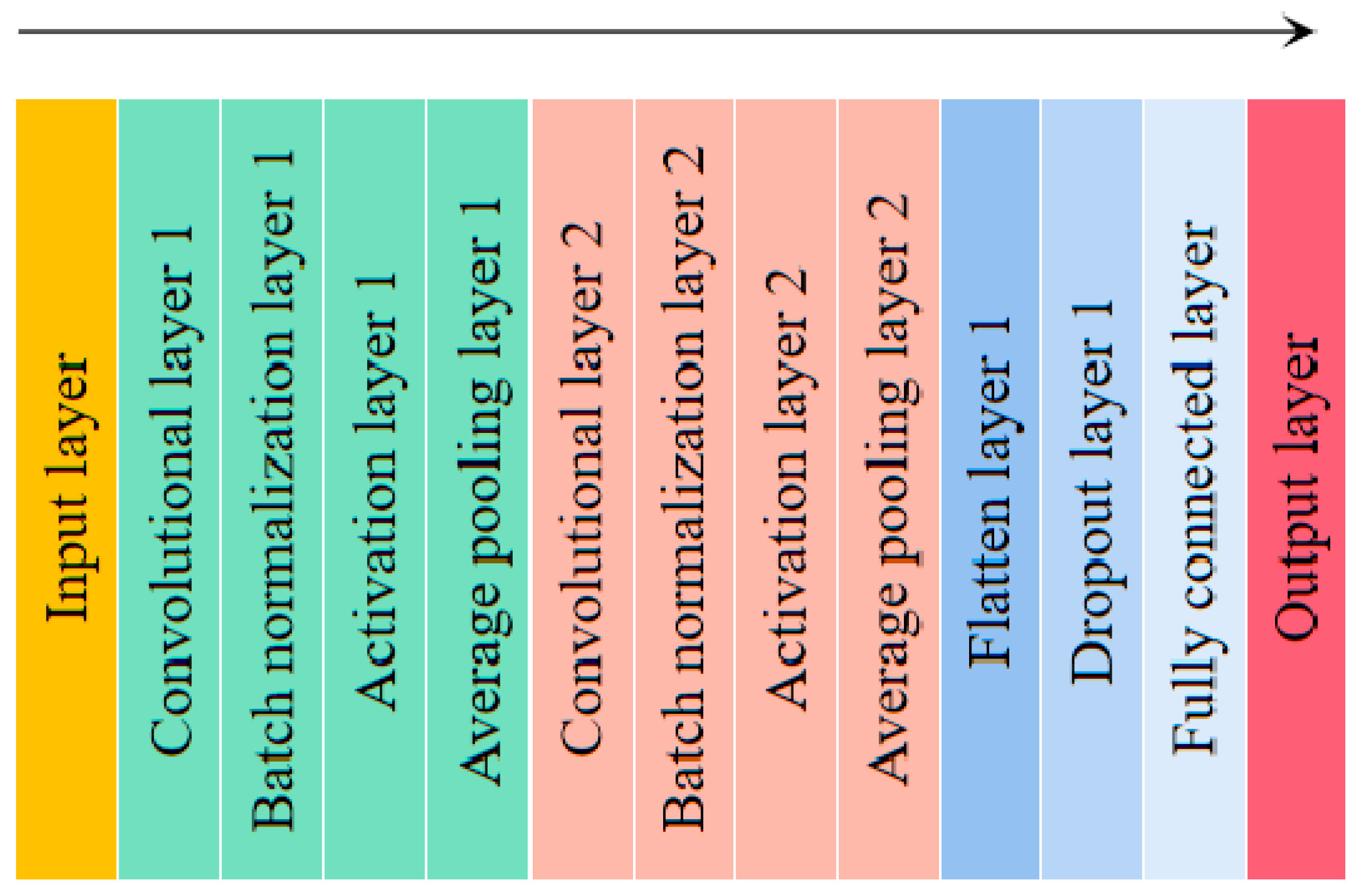
2.5.2. Deep Learning Models
2.6. Model Evaluation Indicators
3. Results
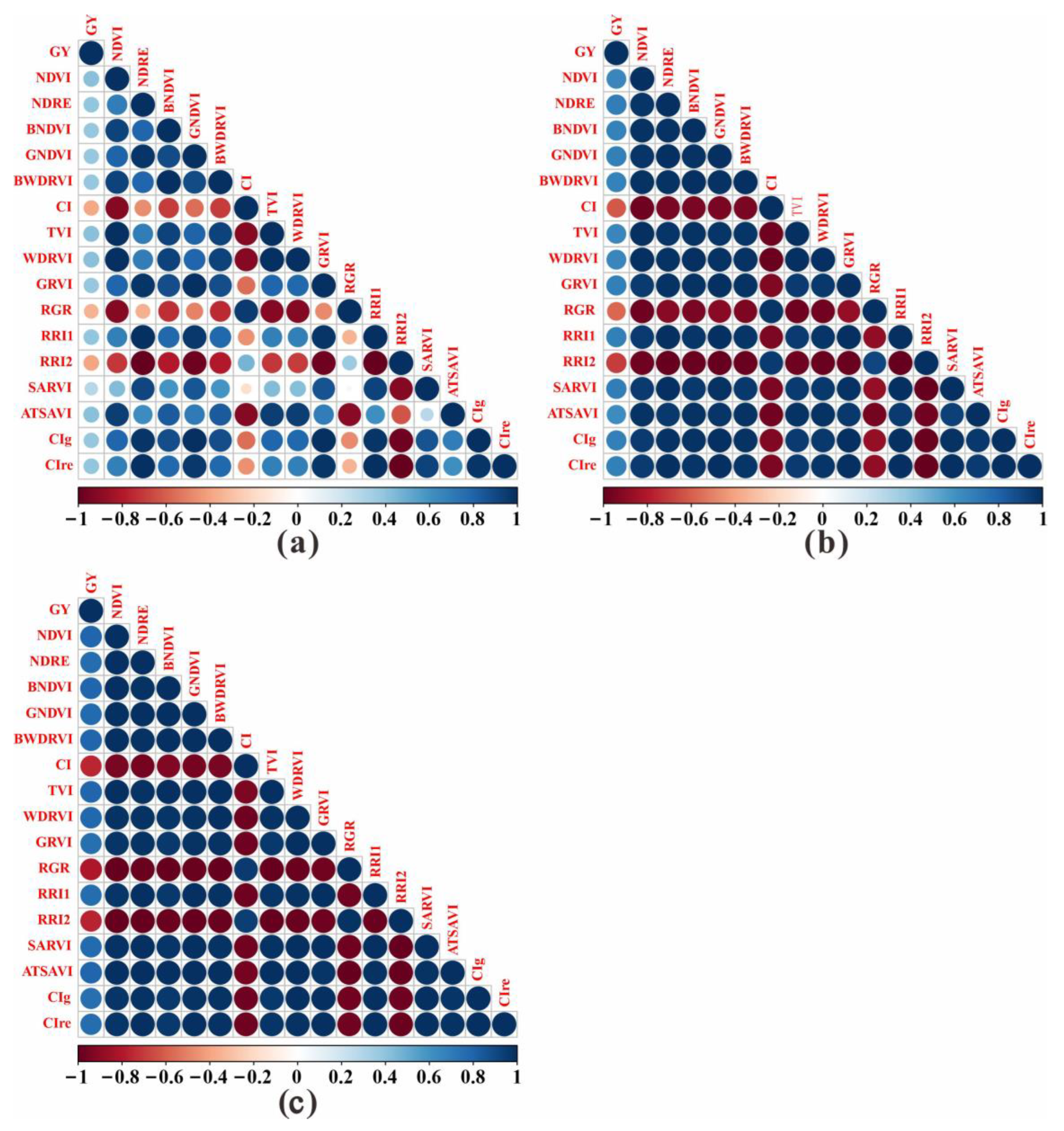
3.1. Correlation Analysis and Acquisition of Input Variable Sets
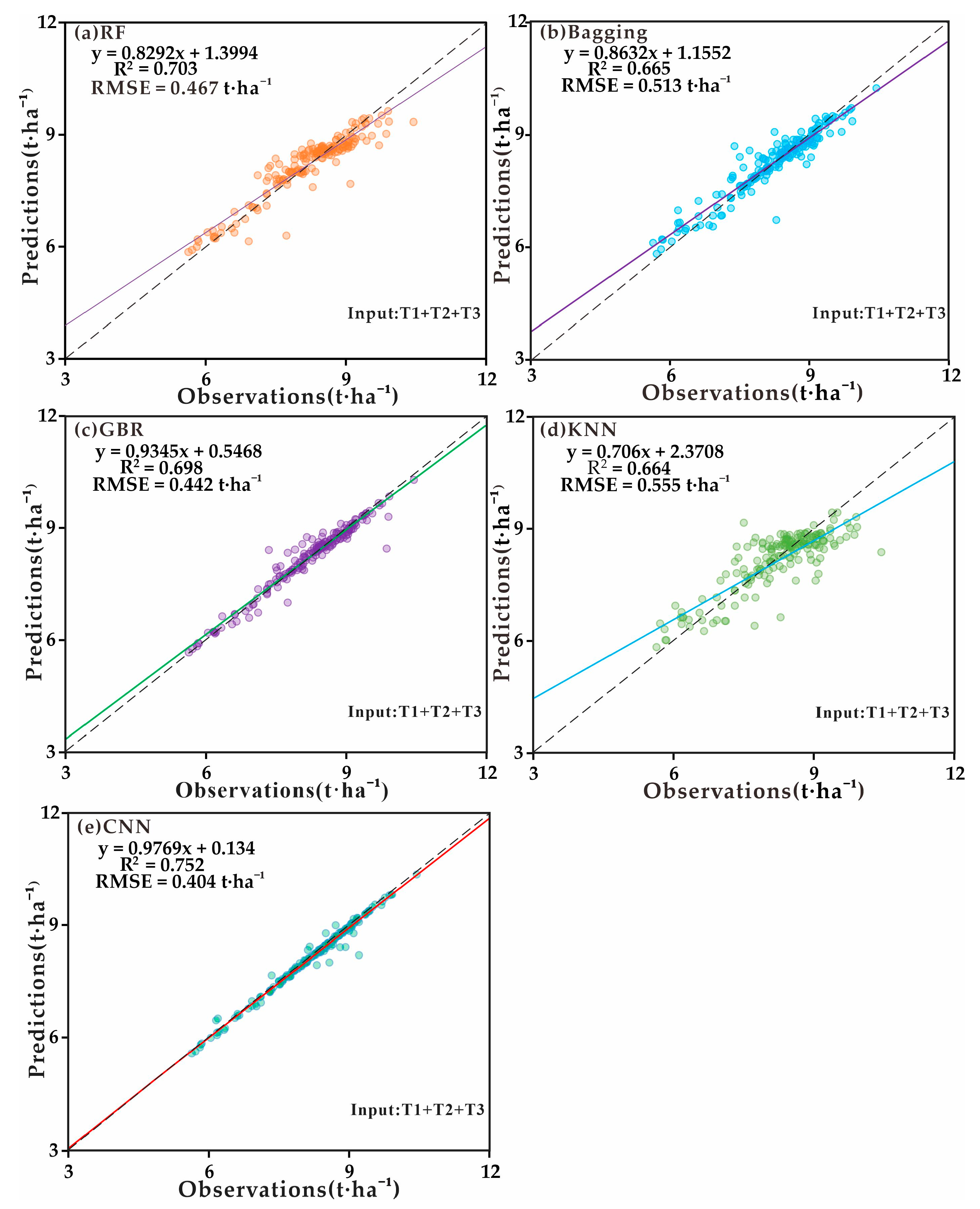
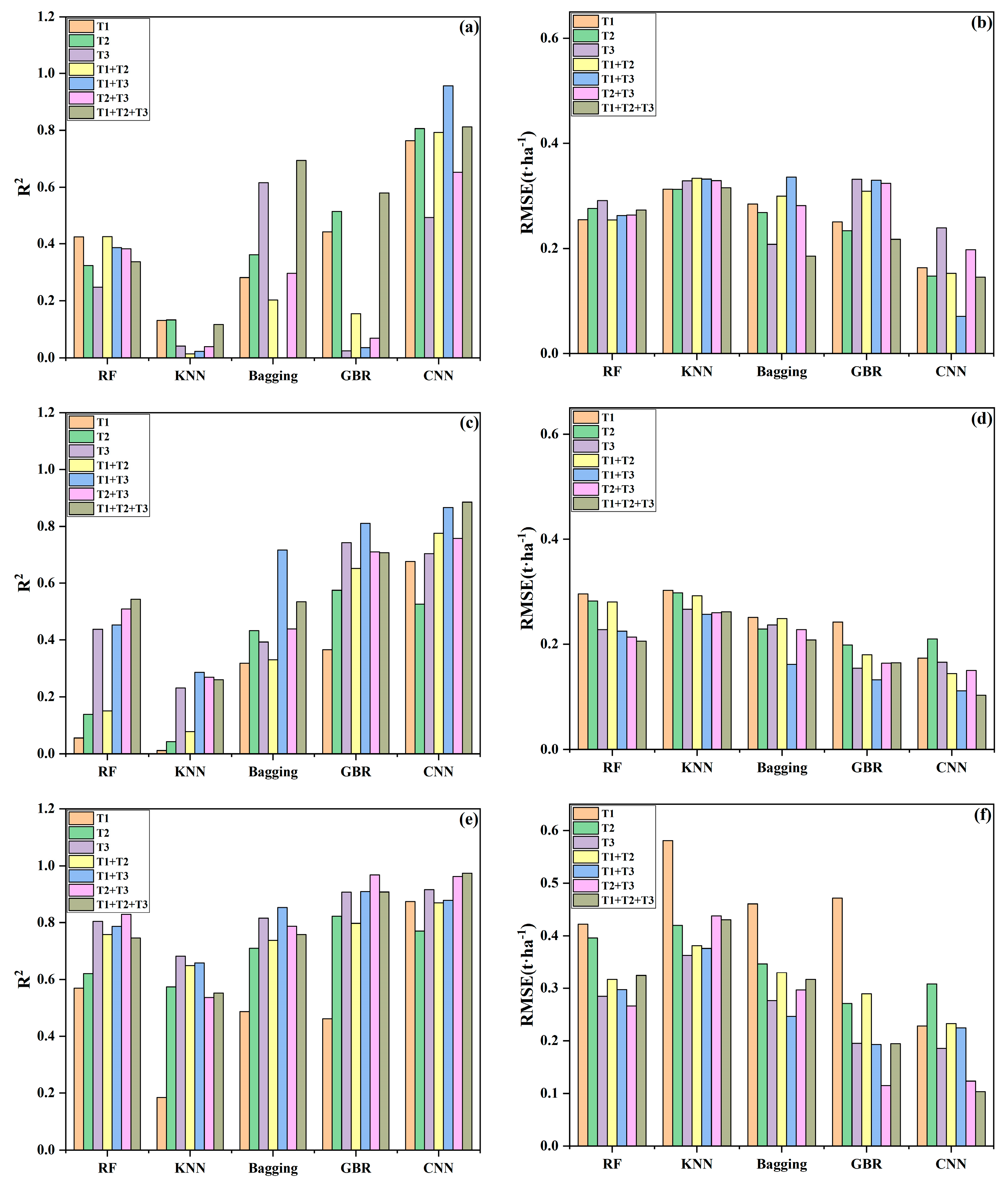
3.2. The Performance of Five Models on Yield Prediction
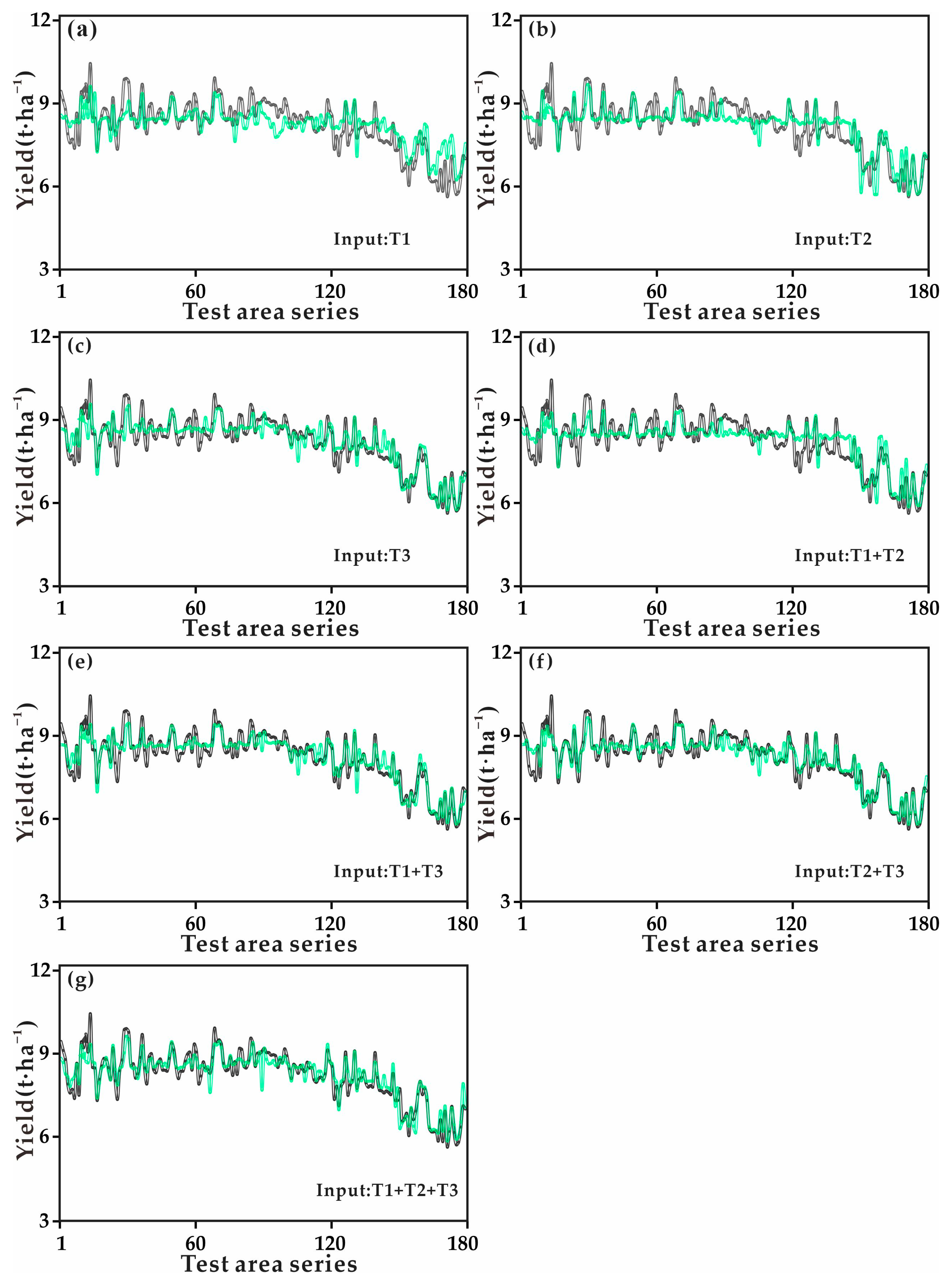
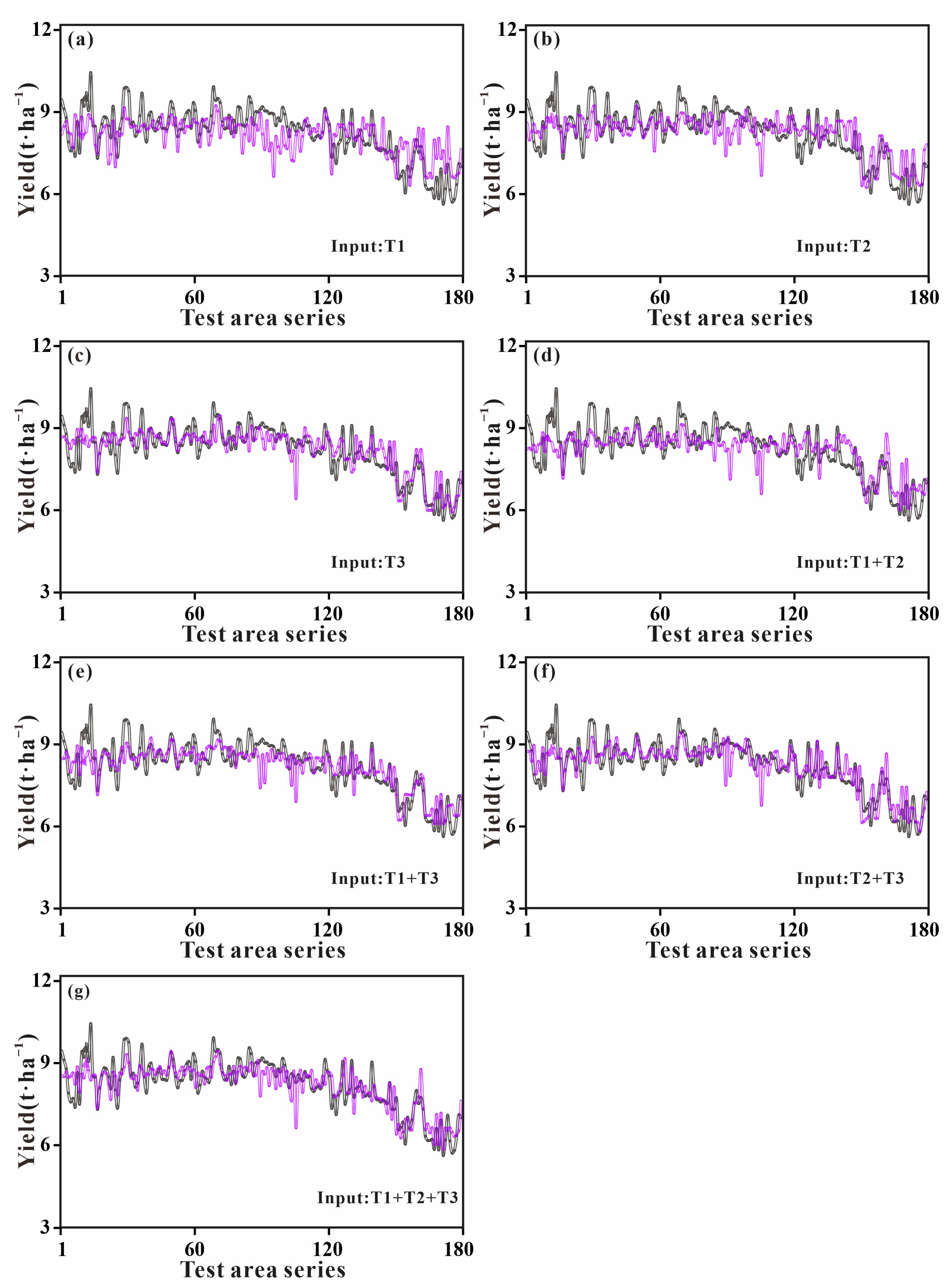
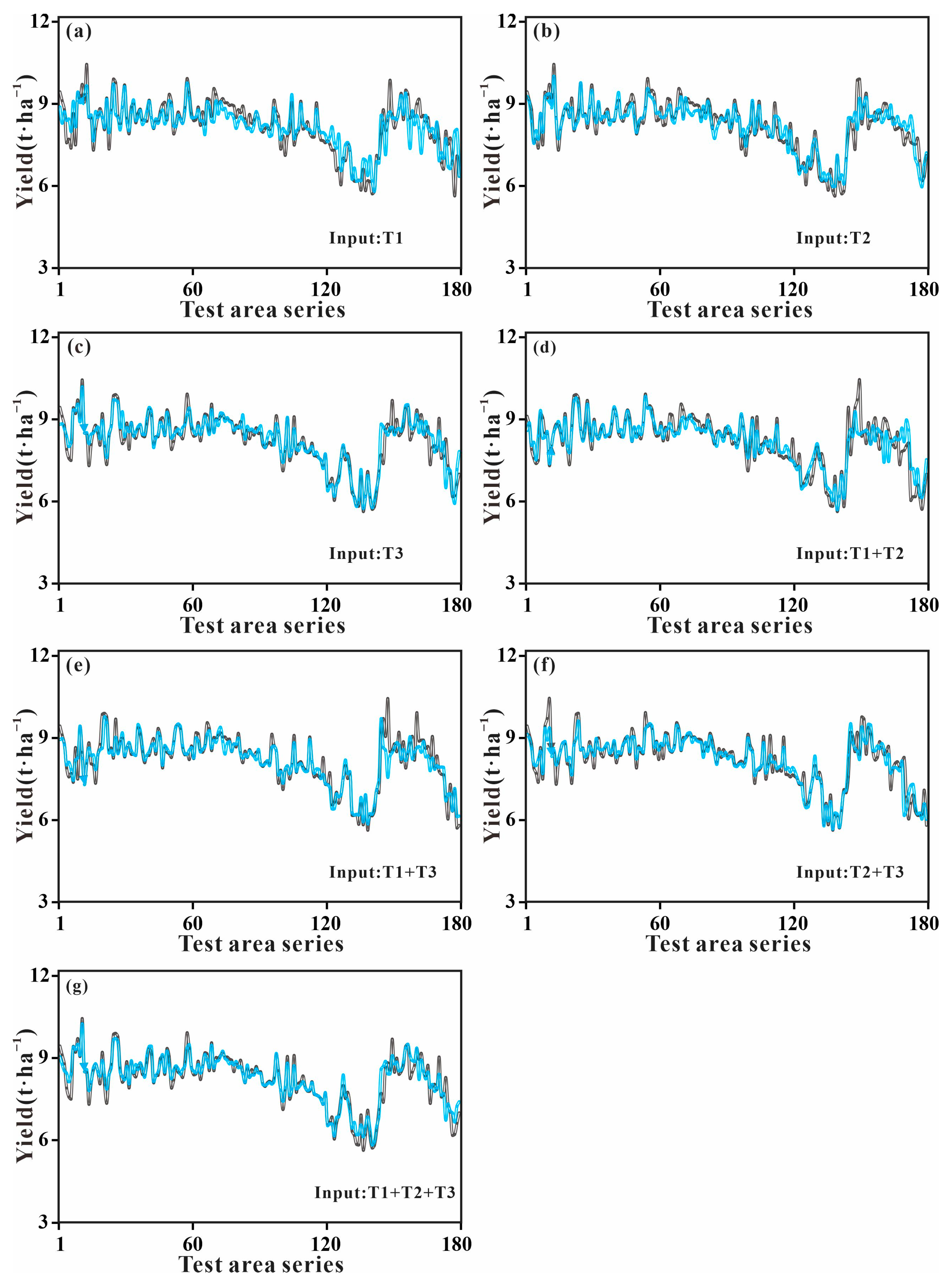
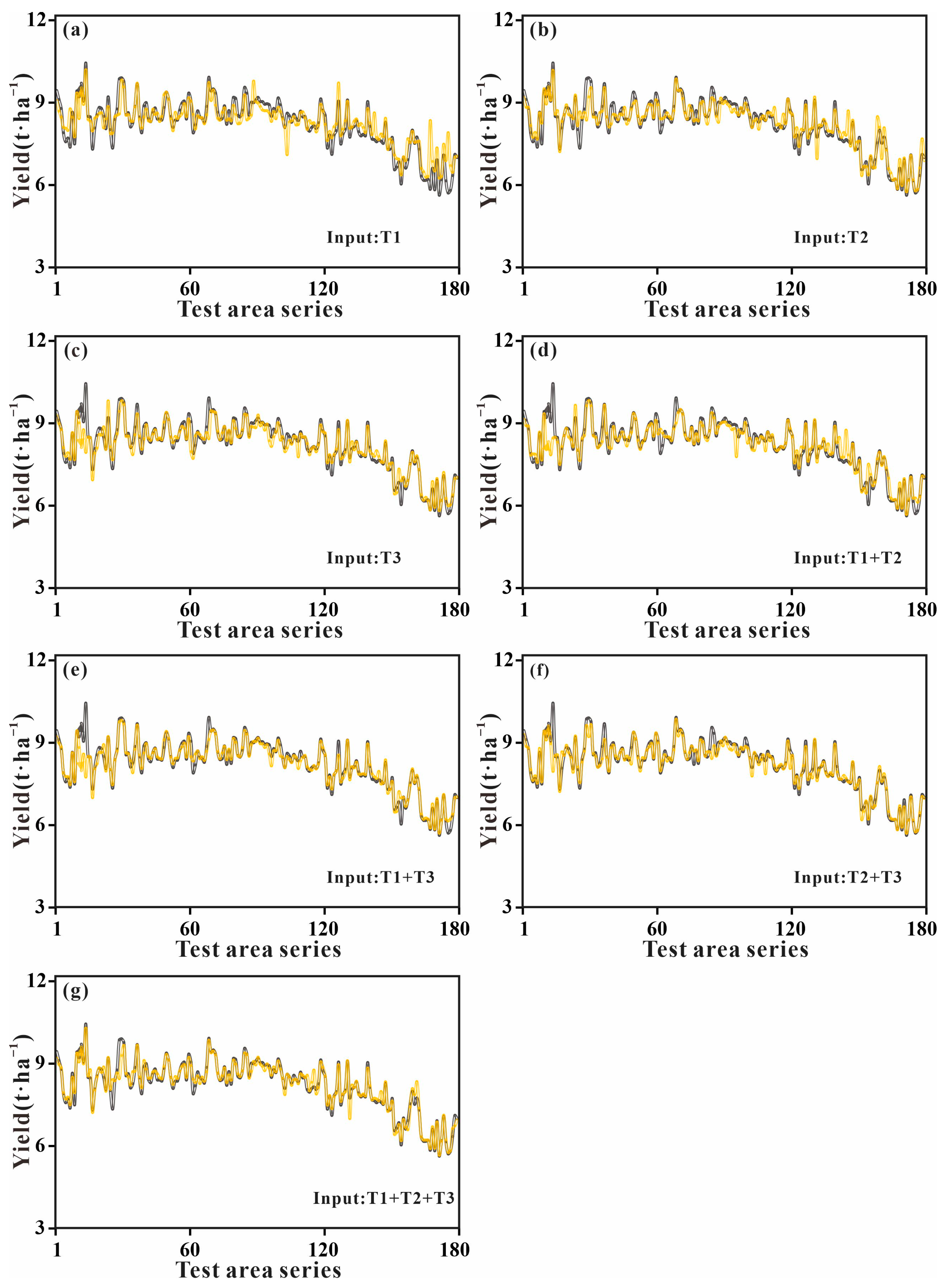
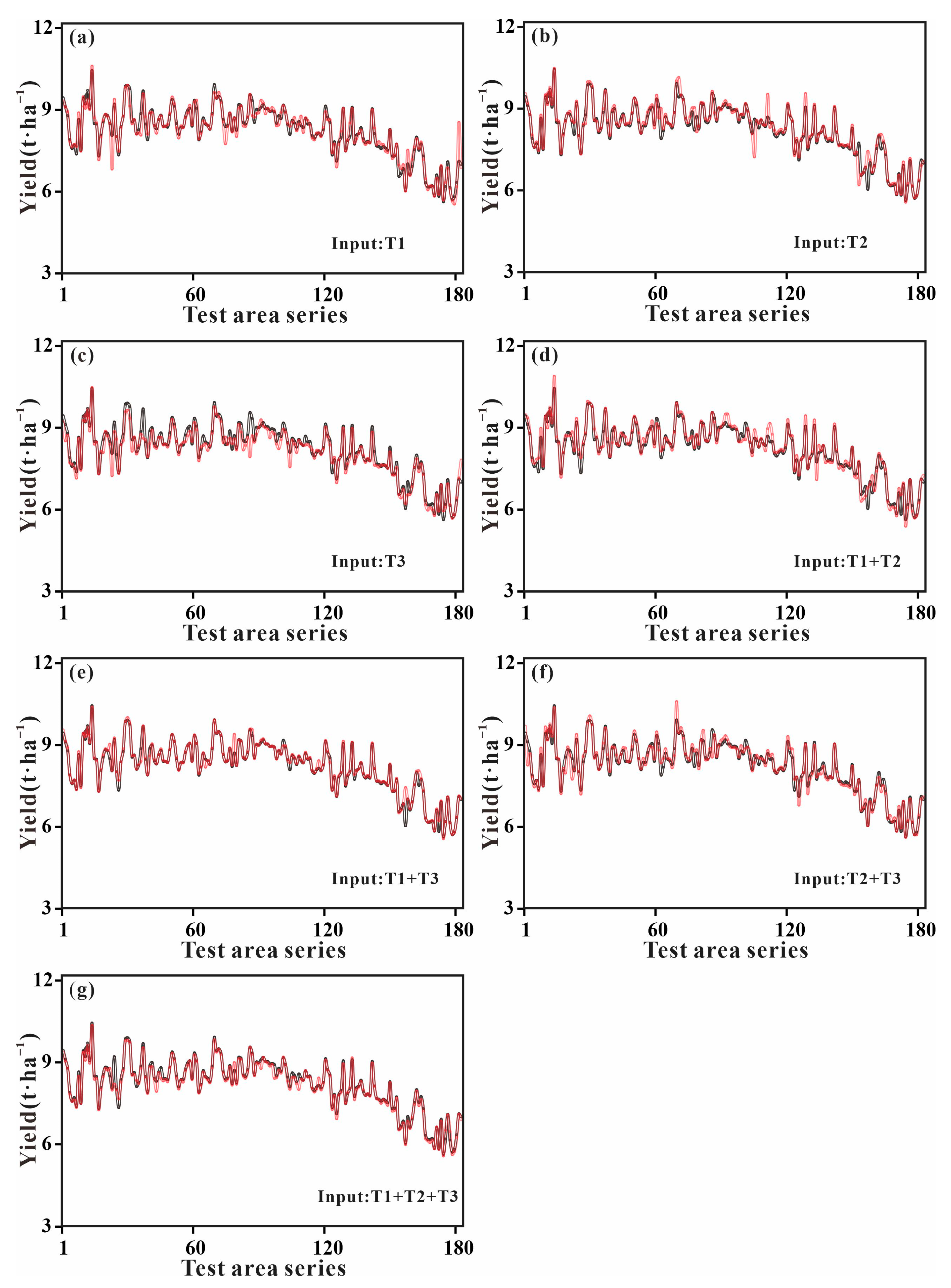
3.3. Analyzing the Dynamics of Predicting Yield
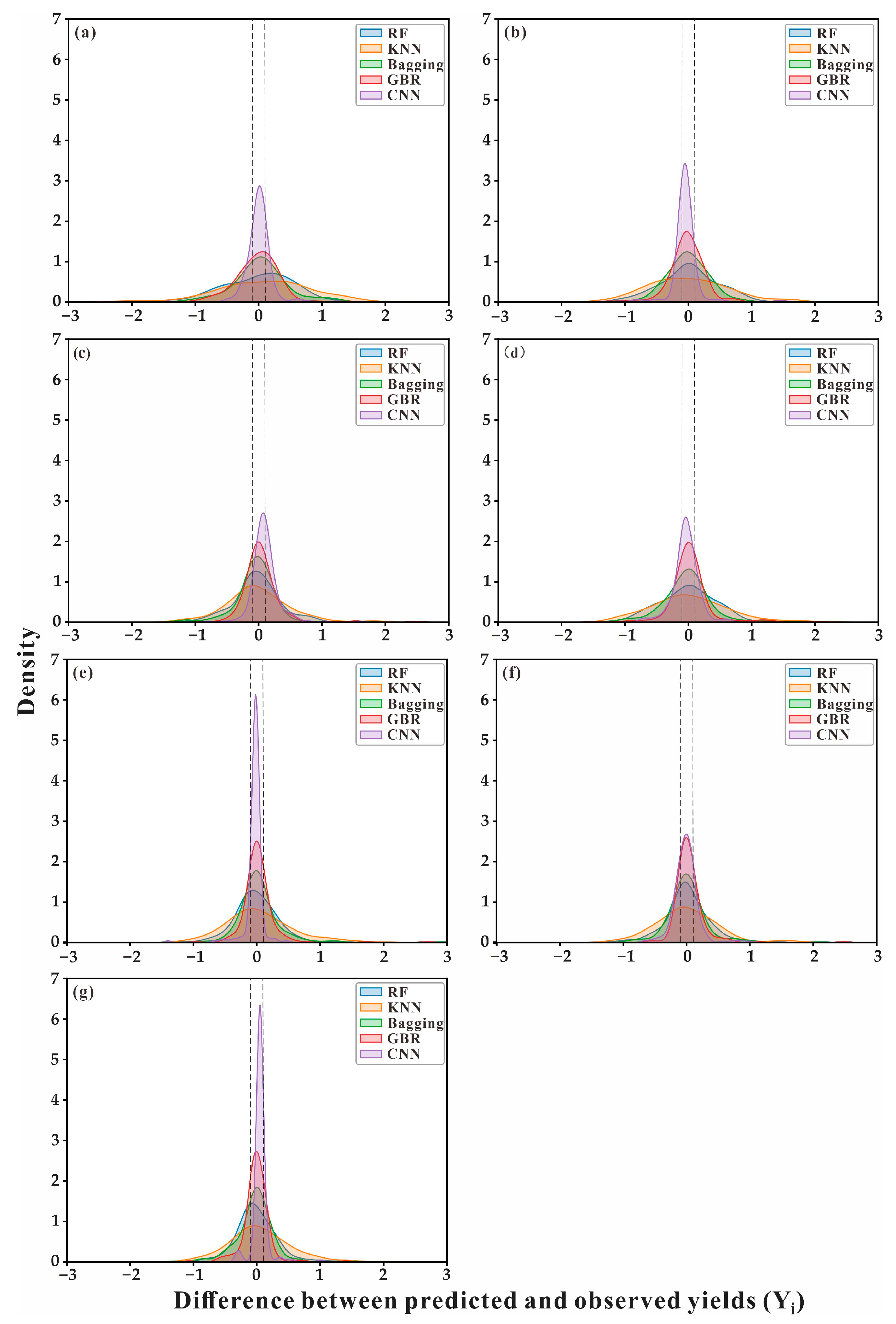
3.4. Distribution of Differences between Observed and Predicted Yields
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shen, Y.; Mercatoris, B.; Cao, Z.; Kwan, P.; Guo, L.; Yao, H.; Cheng, Q. Improving Wheat Yield Prediction Accuracy Using LSTM-RF Framework Based on UAV Thermal Infrared and Multispectral Imagery. Agriculture 2022, 12, 8926. [Google Scholar] [CrossRef]
- Deng, C.; Froese, R.E.; Zhang, S.; Lu, Y.; Xu, X.; Li, Q. Development of improved and comprehensive growth and yield models for genetically improved stands. Ann. For. Sci. 2020, 77, 89. [Google Scholar] [CrossRef]
- Wang, X.; Chen, R.; Kan, H. Application of remote sensing technology in atmospheric pollutant monitoring: A review of recent studies. J. Environ. Health 2011, 28, 924–927. [Google Scholar]
- Huang, Y.; Chen, Z.; Yu, T.; Huang, X.; Gu, X. Agricultural remote sensing big data: Management and applications. J. Integr. Agric. 2018, 17, 1915–1931. [Google Scholar] [CrossRef]
- Tunca, E.; Koksal, E.S.; Cetin, S.; Ekiz, N.M.; Balde, H. Yield and leaf area index estimations for sunflower plants using unmanned aerial vehicle images. Environ. Monit. Assess. 2018, 190, 68211. [Google Scholar] [CrossRef]
- Sha, Z.; Wang, Y.; Bai, Y.; Zhao, Y.; Jin, H.; Na, Y.; Meng, X. Comparison of leaf area index inversion for grassland vegetation through remotely sensed spectra by unmanned aerial vehicle and field-based spectroradiometer. J. Plant Ecol. 2019, 12, 395–408. [Google Scholar] [CrossRef] [Green Version]
- Zhu, H.; Liu, H.; Xu, Y.; Yang, G. UAV-based hyperspectral analysis and spectral indices constructing for quantitatively monitoring leaf nitrogen content of winter wheat. Appl. Optics 2018, 57, 7722–7732. [Google Scholar] [CrossRef]
- Chen, S.; Chen, J.; Zhang, Z.; Bian, J.; Wang, Y.; Shi, S. Retrieving soil water content of winter wheat during heading period by multi-spectral remote sensing of unmanned aerial vehicle (UAV). Water Sav. Irrig. 2018, 5, 39–43. [Google Scholar]
- Heidarian Dehkordi, R.; El Jarroudi, M.; Kouadio, L.; Meersmans, J.; Beyer, M. Monitoring Wheat Leaf Rust and Stripe Rust in Winter Wheat Using High-Resolution UAV-Based Red-Green-Blue Imagery. Remote Sens. 2020, 12, 3696. [Google Scholar] [CrossRef]
- Revill, A.; Florence, A.; MacArthur, A.; Hoad, S.; Rees, R.; Williams, M. Quantifying Uncertainty and Bridging the Scaling Gap in the Retrieval of Leaf Area Index by Coupling Sentinel-2 and UAV Observations. Remote Sens. 2020, 12, 184311. [Google Scholar] [CrossRef]
- Wang, D.; Li, R.; Zhu, B.; Liu, T.; Sun, C.; Guo, W. Estimation of Wheat Plant Height and Biomass by Combining UAV Imagery and Elevation Data. Agriculture 2023, 13, 9. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, W.; Krienke, B.; Cao, Q.; Zhu, Y.; Cao, W.; Liu, X. In-season variable rate nitrogen recommendation for wheat precision production supported by fixed-wing UAV imagery. Precis. Agric. 2022, 23, 830–853. [Google Scholar] [CrossRef]
- Yang, X.; Yang, R.; Ye, Y.; Yuan, Z.; Wang, D.; Hua, K. Winter wheat SPAD estimation from UAV hyperspectral data using cluster-regression methods. Int. J. Appl. Earth Obs. Geoinf. 2021, 105, 102618. [Google Scholar] [CrossRef]
- Sahoo, R.N.; Gakhar, S.; Rejith, R.G.; Ranjan, R.; Meena, M.C.; Dey, A.; Mukherjee, J.; Dhakar, R.; Arya, S.; Daas, A.; et al. Unmanned Aerial Vehicle (UAV)-Based Imaging Spectroscopy for Predicting Wheat Leaf Nitrogen. Photogramm. Eng. Remote Sens. 2023, 89, 107–116. [Google Scholar] [CrossRef]
- Bian, C.; Shi, H.; Wu, S.; Zhang, K.; Wei, M.; Zhao, Y.; Sun, Y.; Zhuang, H.; Zhang, X.; Chen, S. Prediction of Field-Scale Wheat Yield Using Machine Learning Method and Multi-Spectral UAV Data. Remote Sens. 2022, 14, 1474. [Google Scholar] [CrossRef]
- Marques Ramos, A.P.; Osco, L.P.; Garcia Furuya, D.E.; Goncalves, W.N.; Santana, D.C.; Ribeiro Teodoro, L.P.; Da Silva Junior, C.A.; Capristo-Silva, G.F.; Li, J.; Rojo Baio, F.H.; et al. A random forest ranking approach to predict yield in maize with uav-based vegetation spectral indices. Comput. Electron. Agric. 2020, 178, 105791. [Google Scholar] [CrossRef]
- Yang, H.; Li, F.; Wang, W.; Yu, K. Estimating Above-Ground Biomass of Potato Using Random Forest and Optimized Hyperspectral Indices. Remote Sens. 2021, 13, 2339. [Google Scholar] [CrossRef]
- Selvaraj, M.G.; Valderrama, M.; Guzman, D.; Valencia, M.; Ruiz, H.; Acharjee, A. Machine learning for high-throughput field phenotyping and image processing provides insight into the association of above and below-ground traits in cassava (Manihot esculenta Crantz). Plant Methods 2020, 16, 871. [Google Scholar] [CrossRef]
- Wang, W.; Cheng, Y.; Ren, Y.; Zhang, Z.; Geng, H. Prediction of Chlorophyll Content in Multi-Temporal Winter Wheat Based on Multispectral and Machine Learning. Front. Plant Sci. 2022, 13, 896408. [Google Scholar] [CrossRef]
- Ponraj, A.S.; Vigneswaran, T. Daily evapotranspiration prediction using gradient boost regression model for irrigation planning. J. Supercomput. 2020, 76, 5732–5744. [Google Scholar] [CrossRef]
- Lee, C.C.; Koo, V.C.; Lim, T.S.; Lee, Y.P.; Abidin, H. A multi-layer perceptron-based approach for early detection of BSR disease in oil palm trees using hyperspectral images. Heliyon 2022, 8, e092524. [Google Scholar] [CrossRef] [PubMed]
- Hu, M.; Pan, Y.; Zhang, N.; Xu, X. A Review on Zernike Coefficient-Solving Algorithms (CSAs) Used for Integrated Optomechanical Analysis (IOA). Photonics 2023, 10, 177. [Google Scholar] [CrossRef]
- Yang, W.; Nigon, T.; Hao, Z.; Paiao, G.D.; Fernandez, F.G.; Mulla, D.; Yang, C. Estimation of corn yield based on hyperspectral imagery and convolutional neural network. Comput. Electron. Agric. 2021, 184, 106092. [Google Scholar] [CrossRef]
- Wang, C.; Wu, X.; Li, L.; Wang, Y.; Li, Z. Convolutional Neural Network Application in Prediction of Soil Moisture Content. Spectrosc. Spectr. Anal. 2018, 38, 36–41. [Google Scholar]
- Tanabe, R.; Matsui, T.; Tanaka, T.S.T. Winter wheat yield prediction using convolutional neural networks and UAV-based multispectral imagery. Field Crop. Res. 2023, 291, 108786. [Google Scholar] [CrossRef]
- Li, D.; Li, L. Detection of Water pH Using Visible Near-Infrared Spectroscopy and One-Dimensional Convolutional Neural Network. Sensors 2022, 22, 5809. [Google Scholar] [CrossRef]
- Kawamura, K.; Nishigaki, T.; Andriamananjara, A.; Rakotonindrina, H.; Tsujimoto, Y.; Moritsuka, N.; Rabenarivo, M.; Razafimbelo, T. Using a One-Dimensional Convolutional Neural Network on Visible and Near-Infrared Spectroscopy to Improve Soil Phosphorus Prediction in Madagascar. Remote Sens. 2021, 13, 1519. [Google Scholar] [CrossRef]
- Dang, Y.P.; Pringle, M.J.; Schmidt, M.; Dalal, R.C.; Apan, A. Identifying the spatial variability of soil constraints using multi-year remote sensing. Field Crop. Res. 2011, 123, 248–258. [Google Scholar] [CrossRef]
- Ehammer, A.; Fritsch, S.; Conrad, C.; Lamers, J.; Dech, S. Statistical derivation of fPAR and LAI for irrigated cotton and rice in arid Uzbekistan by combining multi-temporal RapidEye data and ground measurements. In Remote Sensing for Agriculture, Ecosystems, and Hydrology Xii; SPIE: Toulouse, France, 2010; Volume 7824, p. 782409. [Google Scholar]
- Hancock, D.W.; Dougherty, C.T. Relationships between blue- and red-based vegetation indices and leaf area and yield of alfalfa. Crop Sci. 2007, 47, 2547–2556. [Google Scholar] [CrossRef]
- Wang, F.; Huang, J.; Tang, Y.; Wang, X. New Vegetation Index and Its Application in Estimating Leaf Area Index of Rice. Rice Sci. 2007, 14, 195–203. [Google Scholar] [CrossRef]
- Saha, S.K.; Tiwari, S.K.; Kumar, S. Integrated Use of Hyperspectral Remote Sensing and Geostatistics in Spatial Prediction of Soil Organic Carbon Content. J. Indian Soc. Remote Sens. 2022, 50, 129–141. [Google Scholar] [CrossRef]
- Hunt, E.R., Jr.; Daughtry, C.S.T.; Eitel, J.U.H.; Long, D.S. Remote Sensing Leaf Chlorophyll Content Using a Visible Band Index. Agron. J. 2011, 103, 1090–1099. [Google Scholar] [CrossRef] [Green Version]
- Ahamed, T.; Tian, L.; Zhang, Y.; Ting, K.C. A review of remote sensing methods for biomass feedstock production. Biomass Bioenerg. 2011, 35, 2455–2469. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Stark, R.; Rundquist, D. Novel algorithms for remote estimation of vegetation fraction. Remote Sens. Environ. 2002, 80, 76–87. [Google Scholar] [CrossRef] [Green Version]
- Gamon, J.A.; Surfus, J.S. Assessing leaf pigment content and activity with a reflectometer. New Phytol. 1999, 143, 105–117. [Google Scholar] [CrossRef]
- Lymburner, L.; Beggs, P.J.; Jacobson, C.R. Estimation of canopy-average surface-specific leaf area using Landsat TM data. Photogramm. Eng. Remote Sens. 2000, 66, 183–191. [Google Scholar]
- He, Y.; Guo, X.; Wilmshurst, J.F. Comparison of different methods for measuring leaf area index in a mixed grassland. Can. J. Plant Sci. 2007, 87, 803–813. [Google Scholar] [CrossRef]
- Bali, N.; Singla, A. Deep Learning Based Wheat Crop Yield Prediction Model in Punjab Region of North India. Appl. Artif. Intell. 2021, 35, 1304–1328. [Google Scholar] [CrossRef]
- Elavarasan, D.; Vincent, D.R.; Sharma, V.; Zomaya, A.Y.; Srinivasan, K. Forecasting yield by integrating agrarian factors and machine learning models: A survey. Comput. Electron. Agric. 2018, 155, 257–282. [Google Scholar] [CrossRef]
- Ren, L.; Yang, L.; Wang, H.; Yang, F.; Chen, W.; Zhang, L.; Xu, J. Spatial prediction of soil organic matter in apple region based on random forest. J. Arid Land Resour. Environ. 2018, 32, 141–146. [Google Scholar]
- Gonzalez-Sanchez, A.; Frausto-Solis, J.; Ojeda-Bustamante, W. Predictive ability of machine learning methods for massive crop yield prediction. Span. J. Agric. Res. 2014, 12, 313–328. [Google Scholar] [CrossRef] [Green Version]
- Uddin, S.; Haque, I.; Lu, H.; Moni, M.A.; Gide, E. Comparative performance analysis of K-nearest neighbour (KNN) algorithm and its different variants for disease prediction. Sci. Rep. 2022, 12, 62561. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Xiao, A.; Lei, G.; Dong, G.; Wu, M. Intelligent predicting of salt pond’s ion concentration based on support vector regression and neural network. Neural Comput. Appl. 2020, 32, 16901–16915. [Google Scholar] [CrossRef]
- Weleszczuka, J.; Kosinska-Selbi, B.; Cholewinskaa, P. Prediction of Polish Holstein’s economical index and calving interval using machine learning. Livest. Sci. 2022, 264, 105039. [Google Scholar] [CrossRef]
- Sirsat, M.S.; Cernadas, E.; Fernandez-Delgado, M.; Barro, S. Automatic prediction of village-wise soil fertility for several nutrients in India using a wide range of regression methods. Comput. Electron. Agric. 2018, 154, 120–133. [Google Scholar] [CrossRef]
- Suen, Y.L.; Melville, P.; Mooney, R.J. Combining bias and variance reduction techniques for regression trees. In Machine Learning: ECML 2005, Proceedings of the 16th European Conference on Machine Learning, Porto, Portugal, 3–7 October 2005; Gama, J., Camacho, R., Brazdil, P., Jorge, A., Torgo, L., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3720, pp. 741–749. [Google Scholar]
- Olmos-de-Aguilera, C.; Campos, P.G.; Risso, N. Error reduction in long-term mine planning estimates using deep learning models. Expert Syst. Appl. 2023, 217, 119487. [Google Scholar] [CrossRef]
- Huang, Y.; Yuan, B.; Wang, X.; Dai, Y.; Wang, D.; Gong, Z.; Chen, J.; Shen, L.; Fan, M.; Li, Z. Industrial wastewater source tracing: The initiative of SERS spectral signature aided by a one-dimensional convolutional neural network. Water Res. 2023, 232, 119662. [Google Scholar] [CrossRef]
- Bera, S.; Shrivastava, V.K.; Satapathy, S.C. Advances in Hyperspectral Image Classification Based on Convolutional Neural Networks: A Review. CMES-Comp. Model. Eng. Sci. 2022, 133, 219–250. [Google Scholar] [CrossRef]
- Zhu, J.; Jiang, X.; Rong, Y.; Wei, W.; Wu, S.; Jiao, T.; Chen, Q. Label-free detection of trace level zearalenone in corn oil by surface-enhanced Raman spectroscopy (SERS) coupled with deep learning models. Food Chem. 2023, 414, 135705. [Google Scholar] [CrossRef]
- Jewan, S.Y.Y.; Pagay, V.; Billa, L.; Tyerman, S.D.; Gautam, D.; Sparkes, D.; Chai, H.H.; Singh, A. The feasibility of using a low-cost near-infrared, sensitive, consumer-grade digital camera mounted on a commercial UAV to assess Bambara groundnut yield. Int. J. Remote Sens. 2022, 43, 393–423. [Google Scholar] [CrossRef]
- Feng, L.; Zhang, Z.; Ma, Y.; Du, Q.; Williams, P.; Drewry, J.; Luck, B. Alfalfa Yield Prediction Using UAV-Based Hyperspectral Imagery and Ensemble Learning. Remote Sens. 2020, 12, 2028. [Google Scholar] [CrossRef]
- Sun, Y.; Zhang, Y.; Lu, L.; Wu, Y.; Zhang, Y.; Kamran, M.A.; Chen, B. The application of machine learning methods for prediction of metal immobilization remediation by biochar amendment in soil. Sci. Total Environ. 2022, 829, 154668. [Google Scholar] [CrossRef]
- Zhong, K.; Xiao, Y.; Zhao, X.; Yin, L.; Shu, C.; Tian, Y. Predictive ability of four statistical models for determining the influence of coal thermophysical properties during the initial phase of coal spontaneous combustion. Fuel 2021, 292, 120348. [Google Scholar] [CrossRef]
- Ghanbari, H.; Antoniades, D. Convolutional neural networks for mapping of lake sediment core particle size using hyperspectral imaging. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102906. [Google Scholar] [CrossRef]
- He, Z.; Jiang, T.; Jiang, Y.; Luo, Q.; Chen, S.; Gong, K.; He, L.; Feng, H.; Yu, Q.; Tan, F.; et al. Gated recurrent unit models outperform other Machine learning models in prediction of minimum temperature in greenhouse Based on local weather data. Comput. Electron. Agric. 2022, 202, 107416. [Google Scholar] [CrossRef]
- Srivastava, A.K.; Safaei, N.; Khaki, S.; Lopez, G.; Zeng, W.; Ewert, F.; Gaiser, T.; Rahimi, J. Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Sci. Rep. 2022, 12, 32151. [Google Scholar] [CrossRef]
- He, X.; Chaney, N.W.; Schleiss, M.; Sheffield, J. Spatial downscaling of precipitation using adaptable random forests. Water Resour. Res. 2016, 52, 8217–8237. [Google Scholar] [CrossRef]
- Hu, Z.; Zhang, L.; Wang, Y.; Shamaila, Z.; Zeng, A.; Song, J.; Liu, Y.; Wolfram, S.; Joachim, M.; He, X. Application of BP Neural Network in Predicting Winter Wheat Yield Based on Thermography Technology. Spectrosc. Spectr. Anal. 2013, 33, 1587–1592. [Google Scholar]
- Leng, L.; Yang, L.; Lei, X.; Zhang, W.; Ai, Z.; Yang, Z.; Zhan, H.; Yang, J.; Yuan, X.; Peng, H.; et al. Machine learning predicting and engineering the yield, N content, and specific surface area of biochar derived from pyrolysis of biomass. Biochar 2022, 4, 631. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Vegetation Index | Formulas | References | Applications |
|---|---|---|---|
| Normalised Difference Vegetation Index | [28] | Agriculture, Vegetation | |
| Normalised Difference Red-Edge | [29] | Vegetation | |
| Blue-normalised difference vegetation index | [30] | Vegetation | |
| Green NDVI | [31] | Vegetation | |
| Blue-wide dynamic range vegetation index | [30] | Vegetation | |
| Coloration index | [32] | Vegetation | |
| Transformed Vegetation Index | [33] | Vegetation | |
| Wide Dynamic Range Vegetation Index | [34] | Vegetation | |
| Green ratio vegetation index | [35] | Vegetation | |
| Red-Green Ratio | [36] | Vegetation | |
| RedEdge Ratio Index 1 | [29] | Remote sensing | |
| RedEdge Ratio Index 2 | [29] | Remote sensing | |
| Soil and Atmospherically Resistant Vegetation Index | [37] | Soil, Vegetation | |
| Adjusted transformed soil-adjusted Vegetation Index | [38] | Soil, Vegetation | |
| Chlorophyll Index Green | [33] | Vegetation | |
| Chlorophyll IndexRedEdge | [33] | Vegetation |
| Variable Sets | RF | Bagging | GBR | KNN | CNN | Means | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | |
| (a) | 0.458 | 0.593 | 0.384 | 0.711 | 0.397 | 0.842 | 0.377 | 0.672 | 0.472 | 0.733 | 0.418 | 0.710 |
| (b) | 0.506 | 0.623 | 0.505 | 0.566 | 0.494 | 0.676 | 0.469 | 0.695 | 0.540 | 0.654 | 0.517 | 0.643 |
| (c) | 0.614 | 0.500 | 0.594 | 0.556 | 0.601 | 0.586 | 0.589 | 0.602 | 0.627 | 0.526 | 0.605 | 0.554 |
| (d) | 0.594 | 0.513 | 0.554 | 0.643 | 0.546 | 0.735 | 0.509 | 0.764 | 0.636 | 0.497 | 0.568 | 0.630 |
| (e) | 0.648 | 0.477 | 0.632 | 0.662 | 0.647 | 0.648 | 0.615 | 0.677 | 0.674 | 0.445 | 0.643 | 0.582 |
| (f) | 0.681 | 0.409 | 0.641 | 0.516 | 0.673 | 0.560 | 0.649 | 0.477 | 0.720 | 0.442 | 0.673 | 0.481 |
| (g) | 0.703 | 0.467 | 0.665 | 0.513 | 0.698 | 0.442 | 0.664 | 0.555 | 0.752 | 0.404 | 0.697 | 0.476 |
| Means | 0.611 | 0.512 | 0.568 | 0.595 | 0.579 | 0.641 | 0.553 | 0.635 | 0.631 | 0.529 | ||
| Treatment | RF | Bagging | GBR | KNN | CNN | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | R2 | RMSE (t·ha−1) | |
| IT1 | 0.256 | 1.05 | 0.553 | 0.531 | 0.552 | 0.556 | 0.411 | 0.811 | 0.684 | 0.917 |
| IT2 | 0.732 | 0.201 | 0.61 | 0.299 | 0.605 | 0.232 | 0.538 | 0.207 | 0.543 | 0.642 |
| IT3 | 0.345 | 0.381 | 0.547 | 0.269 | 0.573 | 0.252 | 0.614 | 0.416 | 0.682 | 0.446 |
| IT4 | 0.459 | 0.309 | 0.724 | 0.144 | 0.795 | 0.148 | 0.663 | 0.242 | 0.735 | 0.464 |
| IT5 | 0.827 | 0.207 | 0.655 | 0.368 | 0.514 | 0.392 | 0.726 | 0.626 | 0.62 | 0.496 |
| IT6 | 0.337 | 0.474 | 0.612 | 0.473 | 0.706 | 0.309 | 0.673 | 0.425 | 0.902 | 0.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Z.; Chen, Z.; Cheng, Q.; Fei, S.; Zhou, X. Deep Learning Models Outperform Generalized Machine Learning Models in Predicting Winter Wheat Yield Based on Multispectral Data from Drones. Drones 2023, 7, 505. https://doi.org/10.3390/drones7080505
Li Z, Chen Z, Cheng Q, Fei S, Zhou X. Deep Learning Models Outperform Generalized Machine Learning Models in Predicting Winter Wheat Yield Based on Multispectral Data from Drones. Drones. 2023; 7(8):505. https://doi.org/10.3390/drones7080505
Chicago/Turabian StyleLi, Zongpeng, Zhen Chen, Qian Cheng, Shuaipeng Fei, and Xinguo Zhou. 2023. "Deep Learning Models Outperform Generalized Machine Learning Models in Predicting Winter Wheat Yield Based on Multispectral Data from Drones" Drones 7, no. 8: 505. https://doi.org/10.3390/drones7080505