

Get Inspired

Educate yourself

Start the journey

Collaborate

Ordlista/lexikon för artificiell intelligens.
Read more
|
IntroductionIn today's digital age, where information is king, protecting sensitive data is paramount. Whether you're a business handling confidential client information or an individual safeguarding personal documents, ensuring secure disposal is crucial. This is where document destruction companies come into play, offering specialized services to safely dispose of sensitive materials. Understanding Document DestructionWhat is Document Destruction?Document destruction involves the secure disposal of confidential and sensitive information to prevent unauthorized access or identity theft. It typically entails shredding documents into small, unreadable pieces to ensure complete destruction of data. Importance of Document DestructionProper document destruction company helps mitigate the risk of data breaches, identity theft, and corporate espionage. It also ensures compliance with privacy regulations such as GDPR, HIPAA, and FACTA, which mandate the secure handling and disposal of sensitive information. Types of Document Destruction CompaniesDocument destruction companies come in various forms, catering to different needs and settings. Document Shredding CompanyDocument shredding company specialize in shredding large volumes of documents for businesses, organizations, and government agencies. They offer both on-site and off-site shredding services, ensuring secure disposal of sensitive materials. Residential Shredding CompanyResidential shredding company cater to individuals and households, providing convenient and secure shredding services for personal documents. They offer on-demand or scheduled pickups, allowing homeowners to dispose of sensitive information safely. Benefits of Hiring a Document Destruction CompanySecurity and ConfidentialityDocument destruction companies utilize advanced shredding technologies and adhere to strict security protocols to safeguard sensitive information. They offer a secure chain of custody from collection to destruction, ensuring confidentiality at every step. Compliance with RegulationsBy outsourcing document destruction to reputable companies, businesses and individuals can ensure compliance with data protection laws and industry regulations. This mitigates the risk of legal penalties and reputational damage associated with data breaches. Environmental ResponsibilityMany document destruction companies prioritize environmental sustainability by implementing recycling programs for shredded materials. By recycling paper waste, they contribute to resource conservation and reduce the carbon footprint associated with traditional disposal methods. Choosing the Right Document Destruction CompanyWhen selecting a document destruction company, it's essential to consider several factors to ensure quality service and peace of mind. Reputation and ExperienceChoose a company with a proven track record and extensive experience in the document destruction industry. Look for reviews, testimonials, and certifications that demonstrate their reliability and professionalism. Services OfferedEvaluate the range of services offered by the company, including on-site shredding, off-site shredding, and digital media destruction. Ensure they can accommodate your specific needs and volume requirements. Certifications and ComplianceVerify that the company complies with industry standards and holds relevant certifications such as NAID (National Association for Information Destruction) AAA Certification. This ensures adherence to strict security and privacy protocols. How Document Destruction Companies WorkDocument destruction companies follow a systematic process to ensure secure and efficient disposal of sensitive materials. Collection of DocumentsClients can either schedule on-site pickups or deliver documents to designated drop-off locations. The company provides secure containers for temporary storage until shredding. Secure Shredding ProcessDocuments are shredded using industrial-grade shredders that reduce paper into confetti-like particles. The shredding process is conducted under strict supervision to prevent unauthorized access. Recycling and DisposalOnce shredded, the paper material is baled and transported to recycling facilities for processing. Any remaining waste is disposed of responsibly, adhering to environmental regulations. Cost of Document Destruction ServicesThe cost of document destruction services varies depending on several factors, including the volume of materials, frequency of service, and additional requirements. Factors Affecting CostFactors such as document volume, location, service frequency, and level of security required can influence the overall cost of document destruction services. Cost vs. Risk of Data BreachWhile document destruction services entail a financial investment, the cost is minimal compared to the potential repercussions of a data breach. Investing in secure disposal ensures protection against costly legal penalties and reputational damage. Tips for Effective Document DestructionImplementing effective document destruction practices is essential for maintaining security and compliance. Implement Document Management PoliciesEstablish clear guidelines and procedures for document handling, storage, and disposal. Educate employees on the importance of data security and compliance with company policies. Regular Scheduled ShreddingImplement regular shredding schedules to ensure timely disposal of outdated or redundant documents. Scheduled shredding reduces the accumulation of sensitive materials and minimizes security risks. Secure Disposal of Digital DataIn addition to physical document shredding, ensure secure disposal of digital data through proper data erasure techniques and secure destruction of electronic media. Case StudiesSuccess Stories of Document Destruction CompaniesHighlight real-world examples of how document destruction companies have helped businesses and individuals safeguard sensitive information and maintain compliance with regulations. Future Trends in Document DestructionAs technology continues to evolve, document destruction companies are embracing new trends and innovations to enhance security and sustainability. Technology IntegrationIntegration of advanced technologies such as RFID tracking, cloud-based document management, and mobile shredding services improves efficiency and security in document destruction processes. Sustainable PracticesDocument destruction companies are increasingly adopting sustainable practices such as paper recycling, energy-efficient shredding technologies, and eco-friendly packaging materials to minimize environmental impact. ConclusionIn conclusion, document destruction plays a crucial role in safeguarding sensitive information and ensuring compliance with privacy regulations. By partnering with reputable document destruction companies, businesses and individuals can mitigate the risk of data breaches, protect confidential data, and contribute to environmental sustainability. |
|
Viktor Valadi, Pedro Porto Buarqye de Gusmão, Nicholas D. Lane, and Mina Alibeigi. 2023. FedVal: Different good or different bad in federated learning. 32nd USENIX Security Symposium (USENIX Security 23).
https://www.usenix.org/system/files/usenixsecurity23-valadi.pdf |
|
Edvin Listo-Zec, Johan Östman, Olof Mogren, and Daniel Gillblad. 2023. Efficient Node Selection in Private Personalized Decentralized Learning. Northern Lights Deep Learning Conference.
https://proceedings.mlr.press/v233/zec24a/zec24a.pdf |
|
Marvin Xhemreshi, Johan Östman, Antonia Wachter-Zeh, and Alexandre Graell I Amat. 2023. FedGT: Identification of Malicious Clients in Federated Learning with Secure Aggregation. arXiv preprint arXiv:2305.05506. (preprint)
https://arxiv.org/abs/2305.05506 |
|
Johan Östman, Pablo Gómez, Vinutha Magal Shreenath, and Gabriele Meoni. 2023. Decentralised semi-supervised onboard learning for scene classification in low-earth orbit. Proceedings of the 14th IAA Symposium on Small Satellites for Earth Observation, SSEO.
https://arxiv.org/pdf/2305.04059.pdf |
|
Johan Östman, Ather Gattami, and Daniel Gillblad. 2023. Decentralized Online Bandit Optimization on Directed Graphs with Regret Bounds. arXiv preprint arXiv:2301.11802. (preprint) https://arxiv.org/pdf/2301.11802.pdf
|
|
Rickard Brännvall, Helena Linge, Johan Östman. 2023. Can the use of privacy enhancing technologies enable federated learning for health data applications in a Swedish regulatory context? 35th Annual Workshop of the Swedish Artificial Intelligence Society SAIS 2023
|
|
2024-05-05 17:05
Towards Data Science
How Transformer architecture has been adapted to computer vision tasks |
|
2024-05-05 17:00
Towards Data Science
I’m Not Just Punching In Numbers At A Computer All Day Choosing a college major was difficult for me. It felt like the first step to committing to a career and I wanted a little of everything. I liked math and programming, but I also wanted a job that allowed me to be creative, gave me a platform for communication, and was versatile enough to explore different industries. After some research, the data science program at the Halıcıoğlu Data Science Institute (HDSI) at UC San Diego seemed like a good fit. Despite my decision to pursue this path, I still had doubts and the assumptions I made at the start reflected this skepticism. However, as I work through my final quarters, I am glad (and surprised!) by how the realities of my experience have diverged from those expectations. Expectation #1: Data science will be a lot of repetitive math and programming classes. Looking back, my classes have had much more variety than I expected. Programming and math classes are a majority but each course offers a different perspective on core topics while equipping us with a myriad of tools. There’s also significantly more diversity in the field, ranging from classes on statistical fairness definitions to bioinformatics. I also found niches I especially enjoyed in healthcare, data ethics, and privacy. This helped widen my perspectives on the roles and industries I could enter as a data scientist early on. Expectation #2: I’d be working alone most of the time. I like working with people. Ideas are generated faster. I feel more creative and it’s just more fun! Nevertheless, I initially gave into the stereotype and pictured myself doing my data science homework hunched over a laptop for the better part of my day, so I was surprised by how much group work there was. Nearly all my programming and math classes encourage us to work with at least one other person. Meeting and working with people I didn’t know pushed me outside my comfort zone and refined my teamwork and communication skills. Even in professional settings when my work was independent, I found that working with other interns made me a better data scientist. Although we each had similar foundational skills, leaning on one another to utilize our different strengths and areas of focus allowed us to be better as a whole. Expectation #3: Data science is the same as machine learning. To be fair, I didn’t know much about data science or how machine learning (ML) was defined when I started my journey. Still, coming into the HDSI program, I thought data science was synonymous with ML. I imagined that most of my classes and work would be creating predictive models and delving into neural networks. Instead, the bulk of courses and work in data science focuses on data cleaning, data expiration, and visualization, with the ML analysis taking less time than you’d expect at the end… at least for now. Expectation #4: My role could be automated. This concern originated during my first natural language processing class where my professor showed how quickly GPT-3 could write code. It was daunting as an entry-level data scientist — how was I supposed to compete with models that could correctly write SQL queries faster than I could read them? However, this exercise was meant to illustrate that our roles as technologists weren’t just learning to use tools and understand the inherent processes that allow them to function. Large language models still can’t do your homework correctly, but eventually (and inevitably) they will improve, and when they do, I’m optimistic that they’ll be more of an aid rather than a detriment to data scientists. Unlike data scientists, LLMs aren’t problem solvers. They can’t generate original ideas, use creativity to navigate ambiguous problems, or effectively communicate with different audiences. This may change in the future but through my education and professional experiences, I am confident that I can still make a positive impact in the field. The Takeaway As a part of my data science journey, I’ve learned to embrace the unexpectedness that comes with reality. I learned that the breadth and depth of data science were ideal for doing a bit of everything: to research, to program, to analyze, and to tell stories. With that, I’m confident in my decision to pursue data science and excited to see what the next phase of my career brings. Expectations & Realities of a Student Data Scientist was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. |
|
2024-05-05 16:50
Towards Data Science
|
|
2024-05-05 16:27
Towards Data Science
Applying machine learning methodology to prompt building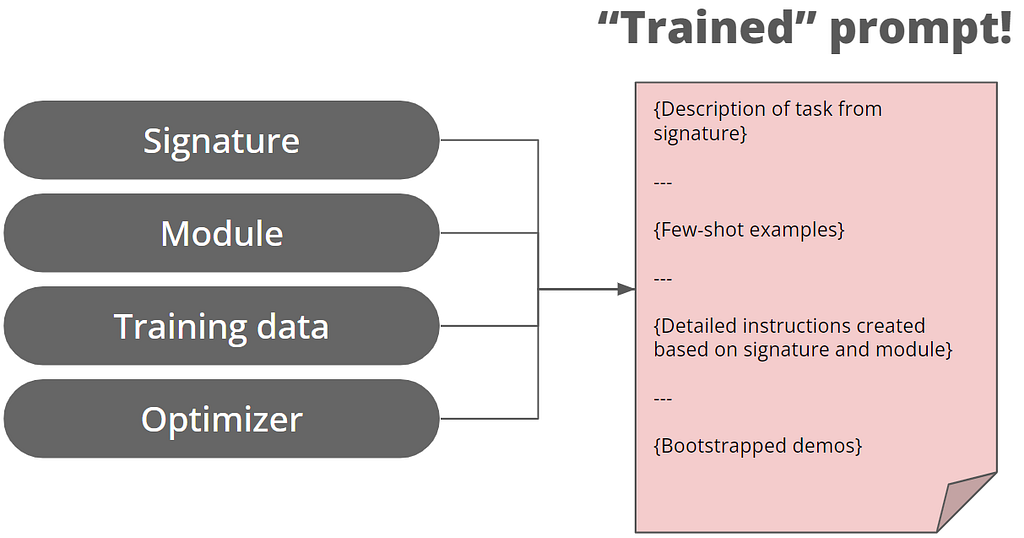 LLMs are grounded in data science, but our approach to prompt engineering might strike us as unscientific:
To address these issues, Stanford NLP has published a paper introducing a new approach with prompt writing: instead of manipulating free-form strings, we generate prompts via modularized programming. The associated library, called DSPy, can be found here. This article aims to show how this “prompt programming” is done, to go deeper in explaining what’s happening behind the optimization process. The code can also be found here. (Speaking of which, you might also find coaxing LLMs to output properly formatted JSON very unscientific too, I have also written an article about how to address this with Function Calling. Check it out !) Build Autonomous AI Agents with Function Calling We will spend some time to go over the environment preparation. Afterwards, this article is divided into 3 sections:
We are now ready to start! Preparation
Basic concept of DSPy: Signature and ModuleThey are the building blocks of prompt programming in DSPy. Let’s dive in to see what they are about! Signatures: Specification of input/outputA signature is the most fundamental building block in DSPy’s prompt programming, which is a declarative specification of input/output behavior of a DSPy module. Signatures allow you to tell the LM what it needs to do, rather than specify how we should ask the LM to do it. Say we want to obtain the sentiment of a sentence, traditionally we might write such prompt: Given a sentence {the_sentence_itself}, deduce its sentiment.But in DSPy, we can achieve the same by defining a signature as below. At its most basic form, a signature is as simple as a single string separating the inputs and output with a -> Note: Code in this section contains those referred from DSPy’s documentation of Signatures # Define signature --- Output --- The prediction is not a good one, but for instructional purpose let’s inspect what was the issued prompt. # This is how we inpect the last issued prompt to the LM --- Output --- We can see the above prompt is assembled from the sentence -> sentiment signature. But how did DSPy came up with the Given the fields… in the prompt? Inspecting the dspy.Predict() class, we see when we pass to it our signature, the signature will be parsed as the signature attribute of the class, and subsequently assembled as a prompt. The instructions is a default one hardcoded in the DSPy library. # Check the variables of the `classify` object, --- Output --- What if we want to provide a more detailed description of our objective to the LLM, beyond the basic sentence -> sentiment signature? To do so we need to provide a more verbose signature in form of Class-based DSPy Signatures. Notice we provide no explicit instruction as to how the LLM should obtain the sentiment. We are just describing the task at hand, and also the expected output. # Define signature in Class-based form --- Output --- It is now outputting a much better prediction! Again we see the descriptions we made when defining the class-based DSPy signatures are assembled into a prompt. Classify emotions in a sentence. This might do for simple tasks, but advanced applications might require sophisticated prompting techniques like Chain of Thought or ReAct. In DSPy these are implemented as Modules Modules: Abstracting prompting techniquesWe may be used to apply “prompting techniques” by hardcoding phrases like let’s think step by step in our prompt . In DSPy these prompting techniques are abstracted as Modules. Let’s see below for an example of applying our class-based signature to the dspy.ChainOfThought module # Apply the class-based signature to Chain of Thought --- Output --- Notice how the “Reasoning: Let’s think step by step…” phrase is added to our prompt, and the quality of our prediction is even better now. According to DSPy’s documentation, as of time of writing DSPy provides the following prompting techniques in form of Modules. Notice the dspy.Predict we used in the initial example is also a Module, representing no prompting technique!
It also have some function-style modules: 6. dspy.majority: Can do basic voting to return the most popular response from a set of predictions. You can check out further examples in each module’s respective guide. Chaining the modulesOn the other hand, what about RAG? We can chain the modules together to deal with bigger problems! First we define a retriever, for our example we use a ColBERT retriever getting information from Wikipedia Abstracts 2017 # Configure retriever Then we define the RAG class inherited from dspy.Module. It needs two methods:
Note: Code in this section is borrowed from DSPy’s introduction notebook # Define a class-based signature Then we make use of the class to perform a RAG # Initilize our RAG class --- Output --- Inspecting the prompt, we see that 3 passages retrieved from Wikipedia Abstracts 2017 is interpersed as context for Chain of Thought generation Answer questions with short factoid answers. The above examples might not seem much. At its most basic application the DSPy seemed only doing nothing that can’t be done with f-string, but it actually present a paradigm shift for prompt writing, as this brings modularity to prompt composition! First we describe our objective with Signature, then we apply different prompting techniques with Modules. To test different prompt techniques for a given problem, we can simply switch the modules used and compare their results, rather than hardcoding the “let’s think step by step…” (for Chain of Thought) or “you will interleave Thought, Action, and Observation steps” (for ReAct) phrases. The benefit of modularity will be demonstrated later in this article with a full-fledged example. The power of DSPy is not only limited to modularity, it can also optimize our prompt based on training samples, and test it systematically. We will be exploring this in the next section! Optimizer: Train our prompt as with machine learningIn this section we try to optimize our prompt for a RAG application with DSPy. Taking Chain of Thought as an example, beyond just adding the “let’s think step by step” phrase, we can boost its performance with a few tweaks:
Doing this manually would be highly time-consuming and can’t generalize to different problems, but with DSPy this can be done automatically. Let’s dive in! Preparation#1: Loading test data: Like machine learning, to train our prompt we need to prepare our training and test datasets. Initially this cell will take around 20 minutes to run. from dspy.datasets.hotpotqa import HotPotQA Inspecting our dataset, which is basically a set of question-and-answer pairs Example({'question': 'At My Window was released by which American singer-songwriter?', 'answer': 'John Townes Van Zandt'}) (input_keys={'question'})#2 Set up Phoenix for observability: To facilitate understanding of the optimization process, we launch Phoenix to observe our DSPy application, which is a great tool for LLM observability in general! I will skip pasting the code here, but you can execute it in the notebook. Note: If you are on Windows, please also install Windows C++ Build Tools here, which is necessary for Phoenix Prompt OptimizationThen we are ready to see what this opimitzation is about! To “train” our prompt, we need 3 things:
Now we train our prompt. from dspy.teleprompt import BootstrapFewShot --- Successful execution should show this output --- Before using the compiled_rag to answer a question, let’s see what went behind the scene during the training process (aka compile). We launch the Phoenix console by visiting http://localhost:6006/ in browser 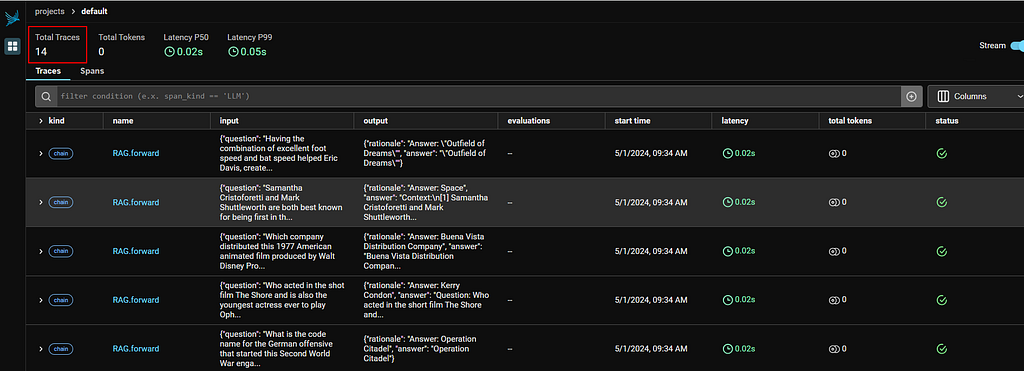 In my run I have made 14 calls using the RAG class, in each of those calls we post a question to LM to obtain a prediction. Refer to the result summary table in my notebook, 4 correct answers are made from these 14 samples, thus reaching our max_bootstrapped_demos parameter and stopping the calls. But what are the prompts DSPy issued to obtain the bootstrapped demos? Here’s the prompt for question #14. We can see as DSPy tries to generate one bootstrapped demo, it would randomly add samples from our trainset for few-short learning. Answer questions with short factoid answers. Time to put the compiled_rag to test! Here we raise a question which was answered wrongly in our summary table, and see if we can get the right answer this time. compiled_rag(question="Which of these publications was most recently published, Who Put the Bomp or Self?") --- Output --- We now get the right answer! Again let’s inspect the prompt issued. Notice how the compiled prompt is different from the ones that were used during bootstrapping. Apart from the few-shot examples, bootstrapped Context-Question-Reasoning-Answer demonstrations from correct predictions are added to the prompt, improving the LM’s capability. Answer questions with short factoid answers. So the below is basically went behind the scene with BootstrapFewShot during compilation: 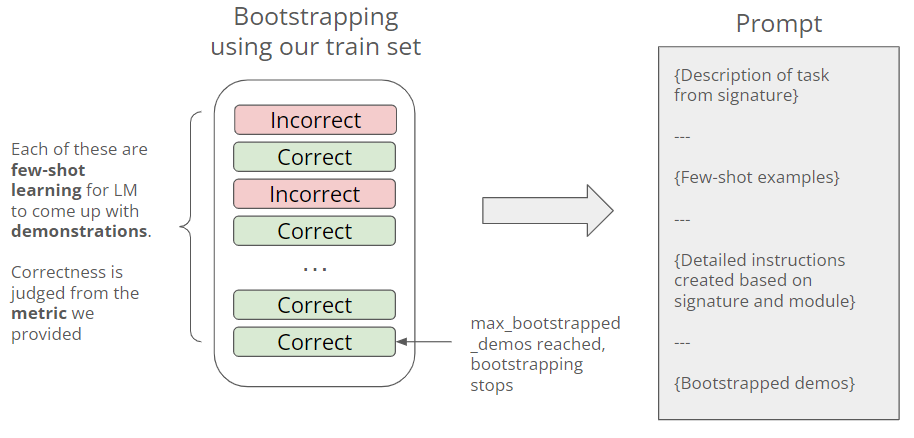 The above example still falls short of what we typically do with machine learning: Even boostrapping maybe useful, we are not yet proving it to improve the quality of the responses. Ideally, like in traditional machine learning we should define a couple of candidate models, see how they perform against the test set, and select the one achieving the highest performance score. This is what we will do next! Full fledged example: Prompt comparison with LLMThe aim of this exampleIn this section, we want to evaluate what is the “best prompt” (expressed in terms of module and optimizer combination) to perform a RAG against the HotpotQA dataset (distributed under a CC BY-SA 4.0 License), given the LM we use (GPT 3.5 Turbo). The Modules under evaluation are:
And the Optimizer candidates are:
As for evaluation metric, we again use exact match as criteria (dspy.evaluate.metrics.answer_exact_match) against the test set. ComparisonLet’s begin! First, we define our modules # Vanilla Then define permutations for our model candidates from dspy.teleprompt import LabeledFewShot, BootstrapFewShot Then I defined a helper class to facilitate the evaluation. The code is a tad bit long so I am not pasting it here, but it could be found in my notebook. What it does is to apply each the optimizers against the modules, compile the prompt, then perform evaluation against the test set. We are now ready to start the evaluation, it would take around 20 minutes to complete # Compile the models Here’s the evaluation result. We can see the COT module with BootstrapFewShot optimizer has the best performance. The scores represent the percentage of correct answers (judged by exact match) made for the test set. 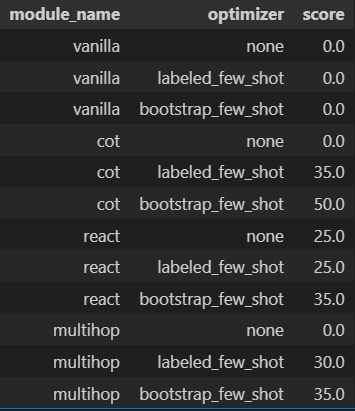 But before we conclude the exercise, it might be useful to inspect the result more deeply: Multihop with BootstrapFewShot, which supposedly equips with more relevant context than COT with BootstrapFewShot, has a worse performance. It is strange! Debug and fine-tune our promptNow head to the Phoenix Console to see what’s going on. We pick a random question William Hughes Miller was born in a city with how many inhabitants ?, and inspect how did COT, ReAct, BasicMultiHop with BoostrapFewShot optimizer came up with their answer. You can type this in the search bar for filter: """William Hughes Miller was born in a city with how many inhabitants ?""" in input.value 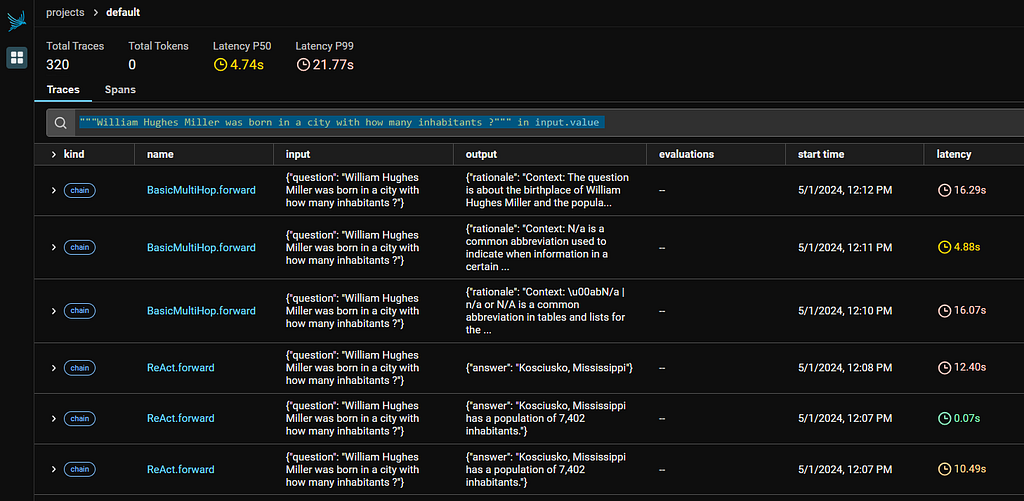 These are the answers provided by the 3 models during my run:
The correct answer is 7,402 at the 2010 census. Both ReAct with BootstrapFewShot and COT with BootstrapFewShot provided relevant answers, but Multihop with BootstrapFewShot simply failed to provide one. Checking the execution trace in Phoenix for Multihop with BootstrapFewShot, looks like the LM fails to understand what is expected for the search_query specified in the signature. 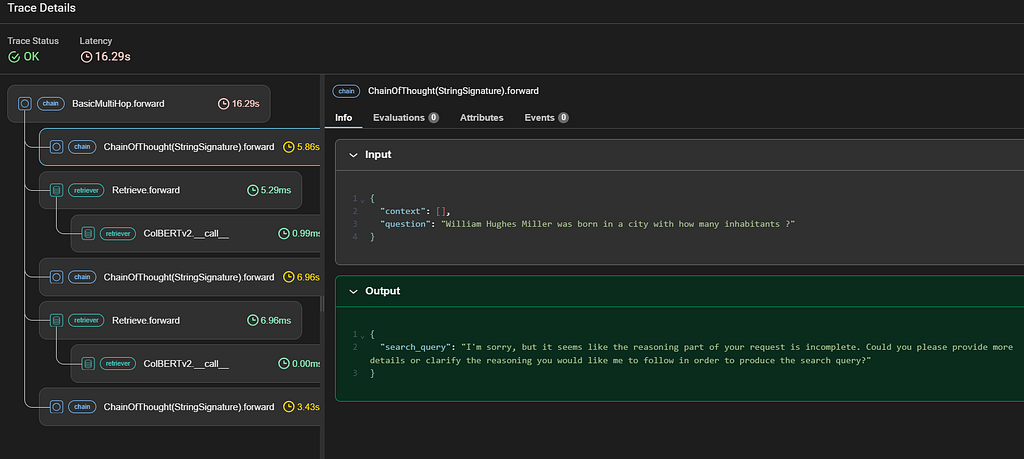 So we revise the signature, and re-run the evaluation with the code below # Define a class-based signature # Revise the modules with the class-based signatures. You can find the relevant code in my notebook 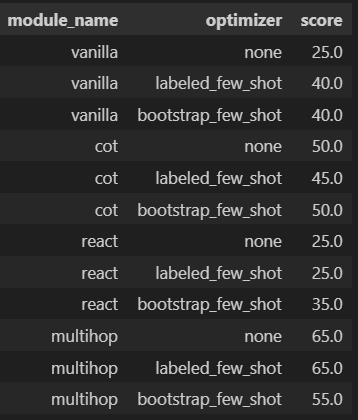 We now see the score improved across all models, and Multihop with LabeledFewShot and Multihop with no examples now have the best performance! This indicates despite DSPy tries to optimize the prompt, there is still some prompt engineering involved by articulating your objective in signature. The best model now produce an exact match for our question! # The correct answer is 7,402 --- Output --- Since the best prompt is Multihop with LabeledFewShot, the prompt does not contain bootstrapped Context-Question-Reasoning-Answer demonstrations. So bootstrapping may not surely lead to better performance, we need to prove which one is the best prompt scientifically. Answer questions with short factoid answers. It does not mean Multihop with BootstrapFewShot has a worse performance in general however. Only that for our task, if we use GPT 3.5 Turbo to bootstrap demonstration (which might be of questionable quality) and output prediction, then we might better do without the bootstrapping, and keep only the few-shot examples. This lead to the question: Is it possible to use a more powerful LM, say GPT 4 Turbo (aka teacher) to generate demonstrations, while keeping cheaper models like GPT 3.5 Turbo (aka student) for prediction? “Teacher” to power-up bootstrapping capabilityThe answer is YES as the following cell demonstrates, we will use GPT 4 Turbo as teacher. # Define the GPT-4 Turbo model  Using GPT-4 Turbo as teacher does not significantly boost our models’ performance however. Still it is worthwhile to see its effect to our prompt. Below is the prompt generated just using GPT 3.5 Answer questions with short factoid answers. And here’s the prompt generated using GPT-4 Turbo as teacher. Notice how the “Reasoning” is much better articulated here! Answer questions with short factoid answers. ConclusionCurrently we often rely on manual prompt engineering at best abstracted as f-string. Also, for LM comparison we often raise underspecified questions like “how do different LMs compare on a certain problem”, borrowed from the Stanford NLP paper’s saying. But as the above examples demonstrate, with DSPy’s modular, composable programs and optimizers, we are now equipped to answer toward “how they compare on a certain problem with Module X when compiled with Optimizer Y”, which is a well-defined and reproducible run, thus reducing the role of artful prompt construction in modern AI. That’s it! Hope you enjoy this article. *Unless otherwise noted, all images are by the author Prompt Like a Data Scientist: Auto Prompt Optimization and Testing with DSPy was originally published in Towards Data Science on Medium, where people are continuing the conversation by highlighting and responding to this story. |
|
2024-05-05 13:22
MarkTechPost

 In deep learning, especially in NLP, image analysis, and biology, there is an increasing focus on developing models that offer both computational efficiency and robust expressiveness. Attention mechanisms have been revolutionary, allowing for better handling of sequence modeling tasks. However, the computational complexity associated with these mechanisms scales quadratically with sequence length, which becomes a […] In deep learning, especially in NLP, image analysis, and biology, there is an increasing focus on developing models that offer both computational efficiency and robust expressiveness. Attention mechanisms have been revolutionary, allowing for better handling of sequence modeling tasks. However, the computational complexity associated with these mechanisms scales quadratically with sequence length, which becomes a […]
The post Researchers at the University of Waterloo Introduce Orchid: Revolutionizing Deep Learning with Data-Dependent Convolutions for Scalable Sequence Modeling appeared first on MarkTechPost. |
|
2024-05-05 10:00
MarkTechPost

 In recent years, the demand for AI and Machine Learning has surged, making ML expertise increasingly vital for job seekers. Additionally, Python has emerged as the primary language for various ML tasks. This article outlines the top ML courses in Python, offering readers the opportunity to enhance their skill set, transition careers, and meet the […] In recent years, the demand for AI and Machine Learning has surged, making ML expertise increasingly vital for job seekers. Additionally, Python has emerged as the primary language for various ML tasks. This article outlines the top ML courses in Python, offering readers the opportunity to enhance their skill set, transition careers, and meet the […]
The post Top Courses for Machine Learning with Python appeared first on MarkTechPost. |
|
2024-05-04 10:30
Wired
Plus: An assassination plot, an AI security bill, a Project Nimbus revelation, and more of the week’s top security news.
|
|
2024-05-03 15:19
ScienceDaily
A stretchy electronic skin could equip robots and other devices with the same softness and touch sensitivity as human skin, opening up new possibilities to perform tasks that require a great deal of precision and control of force.
|




|
Handle-IT
2023-03-09
-
2024-06-15
|

|
Engineering students looking for a real-world challenge
2024-05-01
-
2025-06-06
|















